


平台预置了适配主流深度学习和机器学习框架(TensorFlow、PyTorch、PySpark等)的推理镜像,用户可以直接使用平台预置推理镜像部署模型,节省在线服务部署的开发成本。
推理镜像列表
镜像名称 | 适配框架 | 适配芯片 |
tensorflow1.15-py37 | TensorFlow-1.15.0、LIGHT-3.0 | GPU(CUDA-10.0),CPU |
tensorflow2.4-py38 | TensorFlow-2.4.0、LIGHT-3.0 | GPU(CUDA-11.0),CPU |
pytorch1.9.0-py38 | PyTorch-1.9.0、LIGHT-3.0 | GPU(CUDA-11.1),CPU |
pytorch1.12.1-py38
| PyTorch-1.12.1、LIGHT-3.0 | GPU(CUDA-11.1),CPU |
detectron2-py38 | PyTorch-1.9.0、LIGHT-3.0 | GPU(CUDA-11.1) |
mmdetection1.4.8-py38 | PyTorch-1.9.0、LIGHT-3.0 | GPU(CUDA-11.1) |
onnx1.11.1-py38 | onnx-runtime-1.11.1 | GPU(CUDA-11.1),CPU |
jpmml-py38 | PySpark-2.4.5 | CPU |
操作指引
1. 准备开发环境
a. anaconda 安装与 python 环境准备
因为 TI 平台推理框架仅支持在 Linux 内核系统,请用户在 Linux 内核系统下进行后续操作。
如需要使用 GPU,请自行在本地安装 cuda(对应版本请查看表1. 推理镜像列表)。
anaconda 安装完成之后,使用 anaconda 创建 python 的虚拟环境,假设本次创建的虚拟环境名称为 TIONE-test,请根据实际需求指定 python 版本为3.7或者3.8(暂时只支持这两个版本的环境安装):
conda create -n TIONE-test python=3.8conda activate TIONE-test
b. 安装推理框架相关依赖
脚本主要功能包含安装 tiinfer 推理框架、安装 python 基本功能库、安装 tensorflow/torch 等环境库、平台 demo 和模型文件下载等功能,可以使用
python init_infer_env.py -h查看使用方法,具体参数含义见下表。“脚本依赖”和“已有的 python 环境”,需要用户在开发机本地自行安装 cuda。参数名称/缩写 | 说明 | 可填参数 | 是否必填 |
--ti-infer-version/-v | tiinfer 版本 | 1.0 | 否 |
--model-format/-m | 模型格式 | TorchScript、Detectron2、ONNX、FrozenGraph、SavedModel、MMDetection、PMML、HuggingFace | 是 |
--framework/-f | 推理框架,torch 或者 tensorflow的版本,与模型格式相对应 | torch1.9.0、torch1.12.1、onnx1.11.0、tf1.15.0、tf2.4.0、jpmml0.6.2 | 是 |
--model-scene/-s | 模型使用场景,默认 detect | detect、classify、nlp、ocr、recommend | 否 |
--demo-dir/-d | 下载的路径,默认不做下载 | - | 否 |
--index-url/-i | - | 否 |
脚本安装环境细节与对应安装指令见下表,其中
{}内为可选参数,选择其中某一个填入即可。请勿使用未隔离的同一python环境安装不同的镜像环境,这样可能造成依赖包之间的关联出现问题。如果需要使用多种环境,推荐对不同的镜像名称隔离出多个python环境后再分别进行安装。
模型格式 | 对应镜像名称 | 安装依赖 | 安装指令 |
PYTORCH TorchScript | pytorch1.9.0-py38 | pytorch==1.9.0
opencv-contrib-python==4.6.0.66
opencv-python==4.6.0.66
setuptools==59.5.0
mmcv-full==1.4.8
transformers==4.19.4
torchvision==0.10.0
easyocr==1.6.2 | python init_infer_env.py --framework torch1.9.0 --model-format TorchScript --model-scene {detect, classify, ocr, nlp} --demo-dir ./或 python init_infer_env.py --framework torch1.9.0 --model-format HuggingFace --model-scene nlp --demo-dir ./ |
? | pytorch1.12.1-py38 | pytorch==1.12.1
opencv-contrib-python==4.6.0.66
opencv-python==4.6.0.66
mmcv-full==1.4.8
transformers==4.23.0
torchvision==0.13.1
easyocr==1.6.2 | python init_infer_env.py --framework torch1.12.1 --model-format TorchScript --model-scene {detect, classify, ocr, nlp} --demo-dir ./ |
DETECTRON2 | detectron2-py38 | pytorch==1.9.0
opencv-contrib-python==4.6.0.66
setuptools==59.5.0
detectron2
torchvision==0.10.0 | python init_infer_env.py --framework torch1.9.0 --model-format Detectron2 --model-scene detect --demo-dir ./ |
MMDETECTION | mmdetection1.4.8-py38 | pytorch==1.9.0
opencv-contrib-python==4.6.0.66
opencv-python==4.6.0.66
setuptools==59.5.0
mmcv-full==1.4.8
transformers==4.19.4 | python init_infer_env.py --framework torch1.9.0 --model-format MMDetection --model-scene detect --demo-dir ./ |
ONNX | onnx1.11.0-py38 | torch==1.9.0
onnx==1.11.1
onnxruntime-gpu==1.11.1
opencv-contrib-python==4.6.0.66
setuptools==59.5.0 | python init_infer_env.py --framework onnx1.11.0 --model-format ONNX --model-scene detect --demo-dir ./ |
TENSORFLOW | tensorflow2.4-py38 | ensorflow==2.4.0
opencv-contrib-python==4.6.0.66
setuptools==59.5.0 | python init_infer_env.py --framework tf2.4.0 --model-format FrozenGraph --model-scene nlp --demo-dir ./或 python init_infer_env.py --framework tf2.4.0 --model-format SavedModel --model-scene {nlp, recommend} --demo-dir ./ |
? | tensorflow1.15-py37 | tensorflow==1.15.0
opencv-contrib-python==4.6.0.66
setuptools==59.5.0 | python init_infer_env.py --framework tf1.15.0 --model-format FrozenGraph --model-scene nlp --demo-dir ./ |
PMML | jpmml-py38 | jpmml_evaluator==0.6.2
此环境依赖openjdk 1.8,需要用户自行在本地安装 | python init_infer_env.py --framework jpmml0.6.2 --model-format PMML |
2. 本地开发调试模型
用户需要自行开发 model_service.py 文件用于平台的推理服务,开发方法详细讲解可以参考 模型推理文件简介和示例,这里以 TorchScript 模型格式为例,进行模型包目录规范和 model_service.py 开发方法的讲解。
model_service.py 需要实现 tiinfer.Model 类对应的函数,包括 init 初始化、 load 模型加载、preprocess 数据预处理、predict 模型推理、 postprocess 后处理函数。
初始化函数 init 中,主要是对脚本以及模型参数进行设置。
load 函数中,对模型进行了加载,并设置了类别信息,这里的类别信息主要是为输出时提供数据,用户可根据自身需求选择是否需要。
preprocess 函数中,对请求输入的检测图片进行读取,并标准化到模型规定的输入大小。
predict 函数执行推理过程。
postprocess 函数对推理结果进行处理并打包。
检测模型推理脚本 Pytorch 实现示例:
import osimport loggingimport torchfrom typing import Dict, List, Unionimport numpy as npimport cv2cv2.setNumThreads(5)import tiinferimport tiinfer.utilsimport base64import urllib?from utils.general import non_max_suppression, scale_coordsfrom torchvision import transforms?# 如果使用加速,需添加加速库引用:tiacc_inference# import tiacc_inference?# 未使用加速时模型路径PYTORCH_FILE = "model/yolov5s_ts.pt"# 加速后模型路径# TIACC_FILE = "model/tiacc.pt"??class YoloV5DetectModel(tiinfer.Model):def __init__(self, model_dir: str):super().__init__(model_dir)# workers: 平台参数,设置进程数,非必填,默认值:1self.workers = 1# 以下为自定义参数,根据模型实际需求定义self.model = Noneself.imgsz=640 # 输入图片大小self.conf_thres=0.05self.iou_thres=0.45 # for NMSself.max_det = 20self.use_gpu = torch.cuda.is_available()self.device = torch.device('cuda:0' if self.use_gpu else 'cpu')self.resize = transforms.Resize((self.imgsz, self.imgsz))self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])?# 加载模型def load(self) -> bool:try:# 拼装模型路径,self.model_dir: 当前工作目录;当为加速模型时,请将'PYTORCH_FILE'替换为'TIACC_FILE'model_file = os.path.join(self.model_dir, PYTORCH_FILE)logging.info("model_file %s", model_file)# 加载模型self.model = torch.jit.load(model_file, map_location=self.device)# 设置类别信息self.det_obj_names = ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train','truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench','bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe','backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard','sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard','tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl','banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut','cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop','mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink','refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']logging.info("load model to device %s" % (self.device) )except Exception as e: # pylint: disable=broad-exceptlogging.error("load model failed: %s", e)return Falsereturn True?# 预处理请求体def preprocess(self, request: Dict) -> Dict:try:img_data = request["image"]# image_to_cv2_mat能够正确处理本地图片、图片url及base64编码的图片内容,将之转换为opencv2中的矩阵img_mat = tiinfer.utils.image_to_cv2_mat(img_data)# 纬度转换img_mat = torch.Tensor(img_mat).permute((2, 0, 1)).to(self.device)?# 如果在加速场景,图片尺寸必须在加速配置的tensor范围内,平台提供图片等比扩缩与填充接口:tiinfer.scale_fill_image方便用户使用。# 例如:加速模型tensor设置的范围为[720,2080],等比扩缩图片的范围[1080,1999],等比扩缩后最小边不在tensor范围内,需要做补边操作,例如下面最小边需要补边到800。# min_size=1080; #图片扩缩小边最小范围值# max_size=1999; #图片扩缩大边最大范围值# padding_limit=800; #填充时的短边上限# image, self.scaleratio = tiinfer.scale_fill_image(image, min_size, max_size, padding_limit, Horizontal.RIGHT,Vertical.LOWER) 具体使用指引。# 数据标准化c, h, w = img_mat.shapeimg_tensor = self.normalize(self.resize(img_mat).type(torch.float32)/255)return {"img_tensor": img_tensor.unsqueeze(0), "original_dims": [w, h]}except Exception as e:logging.error("Preprocess failed: %s" % (e))return {"error": "preprocess failed"}?# 推理执行,参数request是preprocess方法的返回结果def predict(self, request: Dict) -> Dict:with torch.no_grad():try:# 获取预测结果out = self.model(request["img_tensor"])# 可选操作,根据实际情况执行# 对预测结果进行非极大值抑制preds, nms_t = non_max_suppression(out, self.conf_thres, self.iou_thres, max_det=self.max_det)data = {"pred_out": preds[0].to('cpu'),"original_dims": request["original_dims"]}return dataexcept Exception as e:logging.error("Failed to predict" % (e))request["predict_err"] = str(e)return request?# 后处理,参数request是predict方法的返回结果def postprocess(self, request: Dict) -> Dict:try:# 可选操作,根据模型输出与实际需求对预测结果进行后处理pred_out = request["pred_out"]original_dim = request["original_dims"]# 调整图片形状pred_bbox = scale_coords([self.imgsz, self.imgsz], pred_out[:, :4], original_dim).round()# 输出参数,根据网络实际情况定义labels = []confs = []label_indx = []boxes = []for i in range(pred_out.shape[0]):obj = pred_out[i, :].tolist()boxes.append(pred_bbox[i, :].tolist())confs.append(obj[4])label_indx.append(int(obj[5]))labels.append(self.det_obj_names[int(obj[5])])image_result = {"det_boxes": boxes,"det_labels": labels,"det_labels_idx": label_indx,"det_scores": confs}return {"result": {"det_objs": image_result}}except Exception as e:logging.error("Postprocess failed: %s" % (e))request.pop("image", '')request.pop("instances", '')request.pop("predictions", '')request["post_process_err"] = str(e)return request
?
3. 在 TI 平台部署在线服务前测试
在上述环境安装完成后,用户可在本地开发机中进行模型测试。TI平台推理框架默认模型包路径为
/data/model/,在开始测试前请确认将模型包已放入该路径下;如有需要,也可以在系统环境变量文件/etc/profile中添加export TI_MODEL_DIR=/xxx自定义模型包路径,默认模型包路径请指向 model_service.py 所在的文件夹。在模型包开发完成后,进入
model_service.py所在路径,以框架默认路径为例,请在/data/model/路径下运行以下代码,以启动服务:python3 -m tiinfer --timeout 30000
服务启动成功后,调用端口为8501,可使用测试用例在本地调用,验证服务可用性。
curl -X POST -H "Content-Type: application/json" http://127.0.0.1:8501/v1/models/m:predict -d @test.json
4. 在 TI 平台上部署模型服务
用户如需使用平台预置推理镜像,可在模型仓库模块导入模型时,关联内置运行环境,则使用该模型启动服务时,会自动拉取对应的平台预置推理镜像进行服务部署。
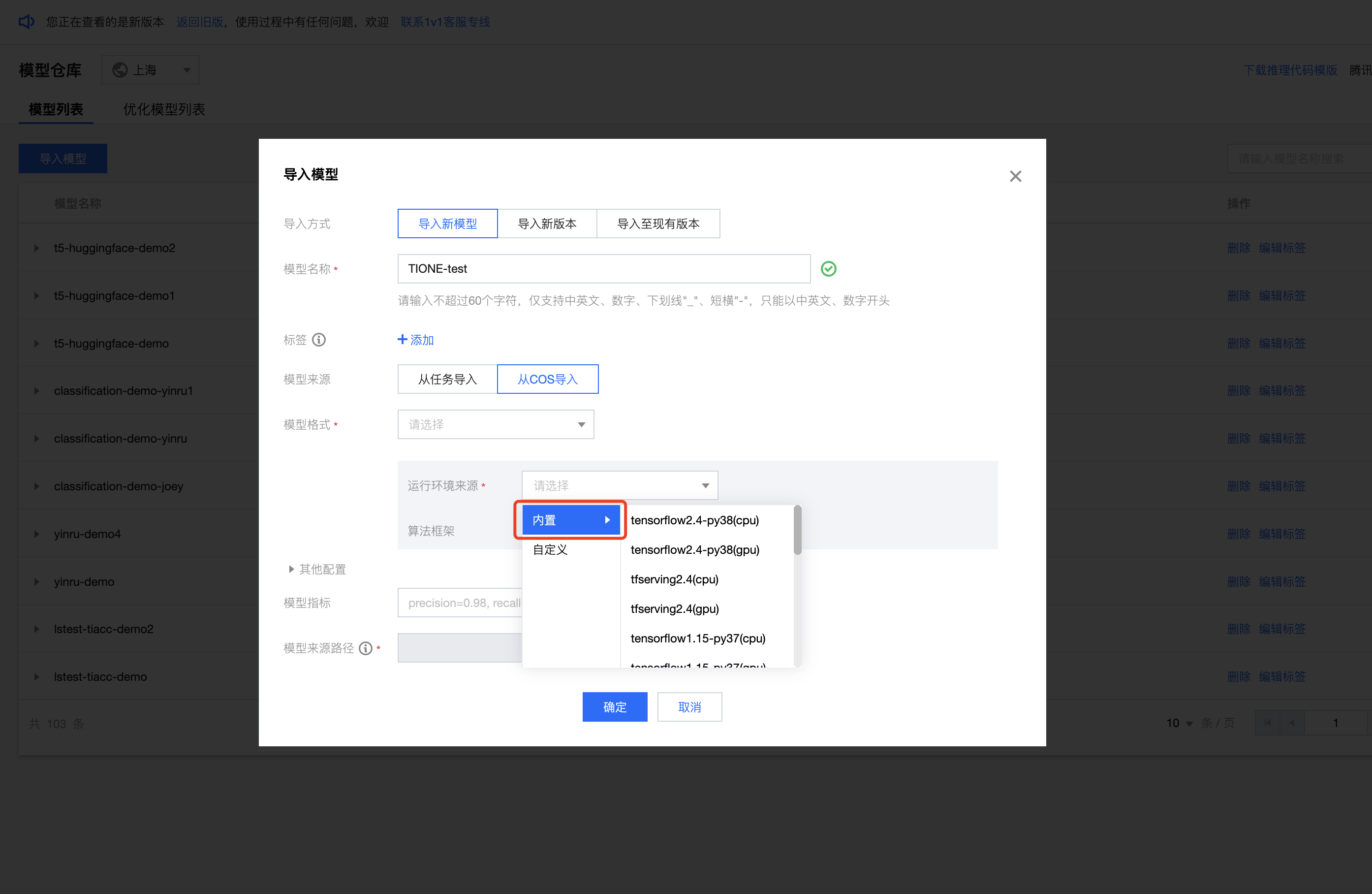
步骤1:
将本地模型上传到 COS 中,并在 TIONE 平台-模型仓库中导入模型。
?
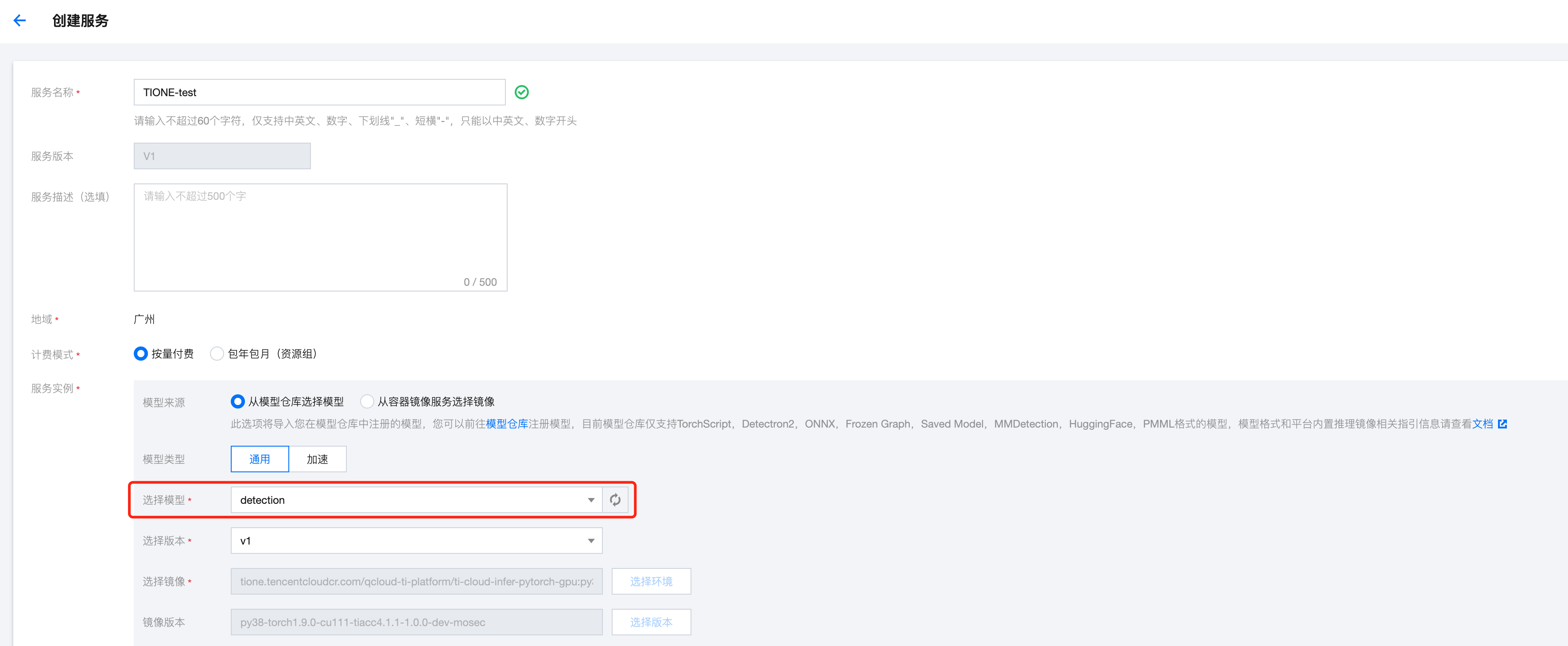
步骤2:
在在线服务模块选择对应的模型发布服务。
?
?
?
?
?
?
?
?
?
?
?
?

