


操作场景
本文介绍如何基于云服务器 CVM 搭建 Tensorflow+Taco Train 分布式训练集群。
操作步骤
购买实例
实例:选择 计算型 GN10Xp 或 GT4。
系统盘:配置容量不小于50GB的云硬盘。您也可在创建实例后使用文件存储,详情参见 在 Linux 客户端上使用 CFS 文件系统。
镜像:建议选择公共镜像,您也可选择自定义镜像。
操作系统请使用 CentOS 8.0/CentOS 7.8/Ubuntu 20.04/Ubuntu 18.04/TecentOS 3.1/TencentOS 2.4。
若您选择公共镜像,则请勾选“后台自动安装GPU驱动”,实例将在系统启动后预装对应版本驱动。如下图所示:
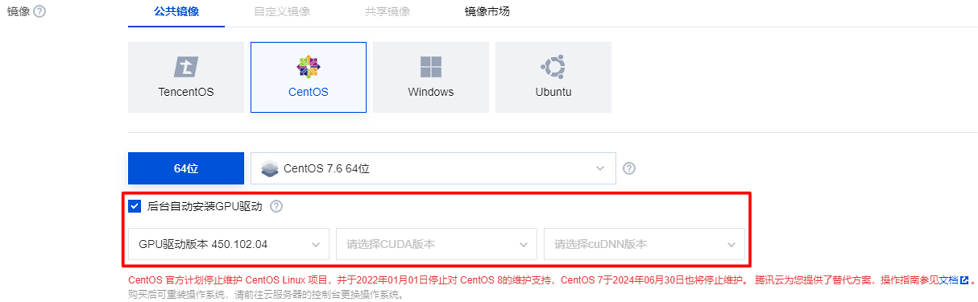
说明
选择公共镜像并自动安装 GPU 驱动的实例,创建成功后,请登录实例等待约20分钟后重启实例,使配置生效。
配置实例环境
验证 GPU 驱动
1. 参考 使用标准登录方式登录 Linux 实例,登录实例。
2. 执行以下命令,验证 GPU 驱动是否安装成功。
nvidia-smi
查看输出结果是否为 GPU 状态:
是,代表 GPU 驱动安装成功。
否,请参考 NVIDIA Driver Installation Quickstart Guide 进行安装。
配置 HARP 分布式训练环境
1. 参考 配置 HARP 分布式训练环境,配置所需环境。
2. 配置完成后,执行以下命令进行验证,若配置文件存在,则表示已配置成功。
ls /usr/local/tfabric/tools/config/ztcp*.conf
安装 docker 和 nvidia docker
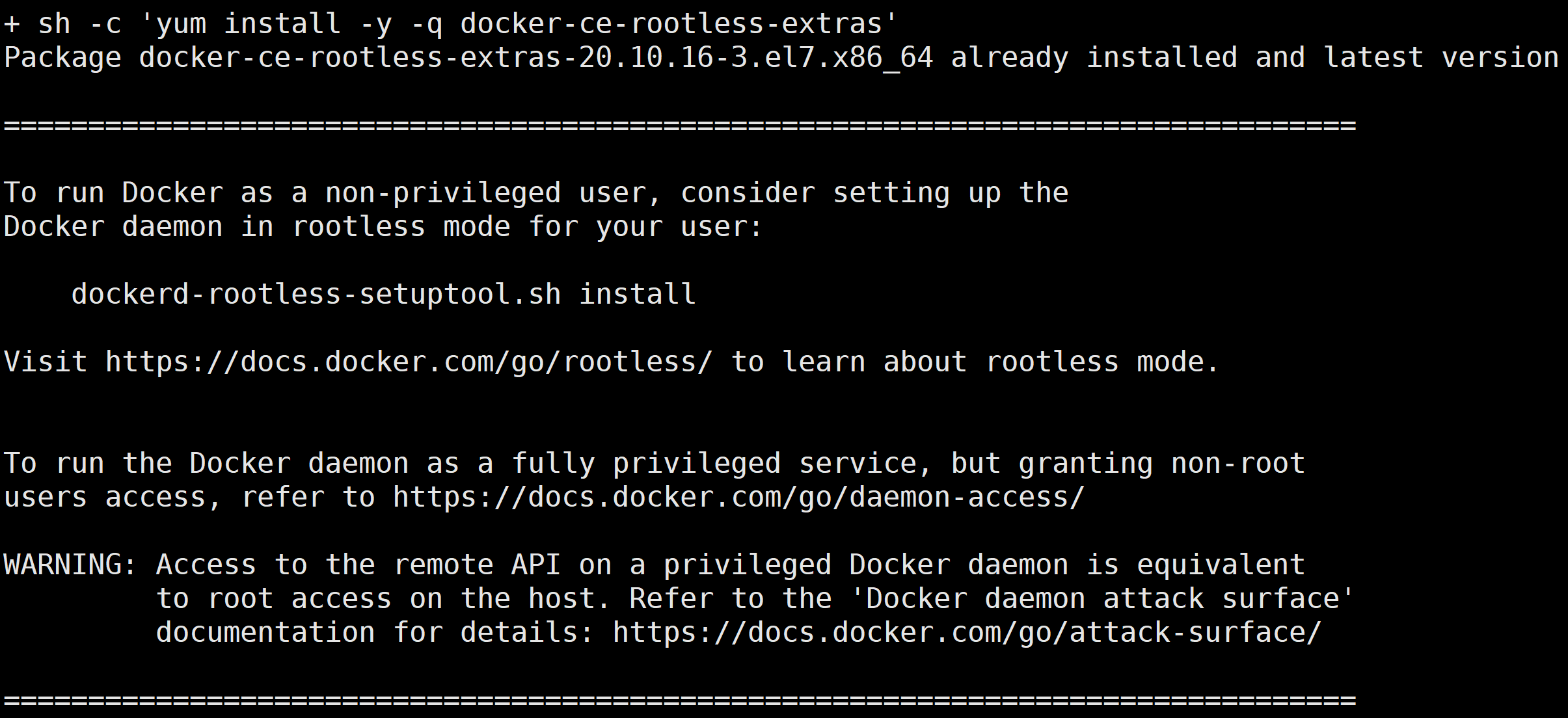
1. 执行以下命令,安装 docker。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-docker.sh | sudo bash
?
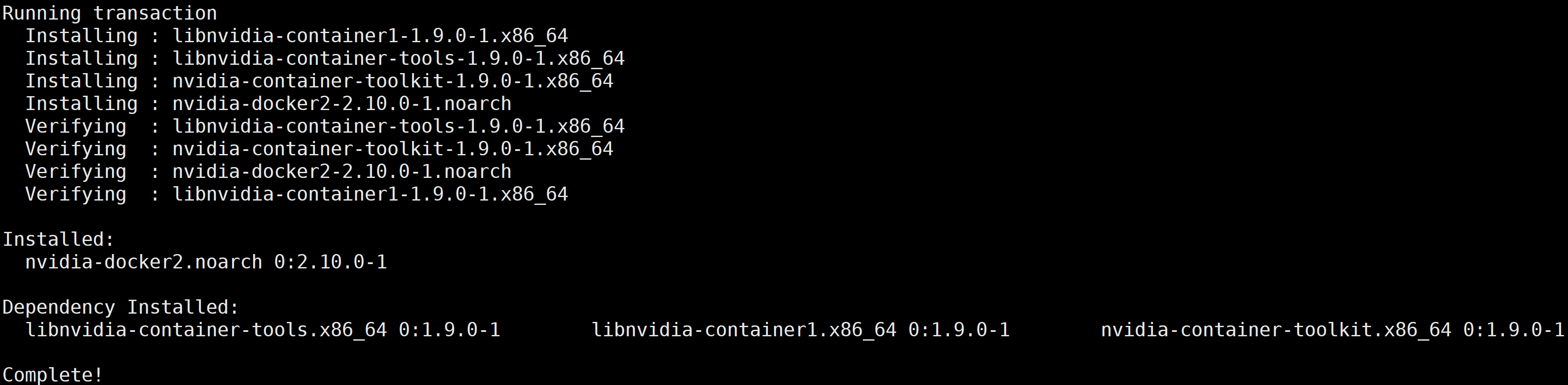
2. 执行以下命令,安装 nvidia-docker2。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-nvidia-docker2.sh | sudo bash
若您无法通过该命令安装,请尝试多次执行命令,或参考 NVIDIA 官方文档 Installation Guide & mdash 进行安装。
本文以 CentOS 为例,安装成功后,返回结果如下图所示:
?
下载 docker 镜像
执行以下命令,下载 docker 镜像。
docker pull ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1
该镜像包含的软件版本信息如下:
OS:18.04.5
python:3.6.9
cuda toolkits:V11.2.152
cudnn library:8.1.1
nccl library:2.8.4
tencent-lightcc :3.1.1
HARP library:v1.3
ttensorflow:1.15.5
其中:
LightCC 是腾讯云提供的基于 Horovod 深度定制优化的通信组件,完全兼容 Horovod API,不需要任何业务适配。
HARP 是腾讯云提供的用户态协议栈,致力于提高 VPC 网络下的分布式训练的通信效率。以动态库的形式提供,官方 NCCL 初始化过程中会自动加载,不需要任何业务适配。
ttensorflow 是腾讯云基于开源 tensorflow 1.15.5添加了 CUDA 11的支持,同时集成了 TFRA,用来支持动态 embedding 的特性。如需了解更多信息,请参见 TTensorflow 使用说明。
启动 docker 镜像
执行以下命令,启动 docker 镜像。
docker run -it --rm --gpus all --privileged --net=host -v /sys:/sys -v /dev/hugepages:/dev/hugepages -v /usr/local/tfabric/tools:/usr/local/tfabric/tools ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1
注意
/dev/hugepages 和 /usr/local/tfabric/tools 包含了 HARP 运行所需要的大页内存和配置文件。分布式训练 benchmark 测试
说明
展开全部
单卡
执行以下命令,进行测试。
/usr/local/openmpi/bin/mpirun -np 1 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
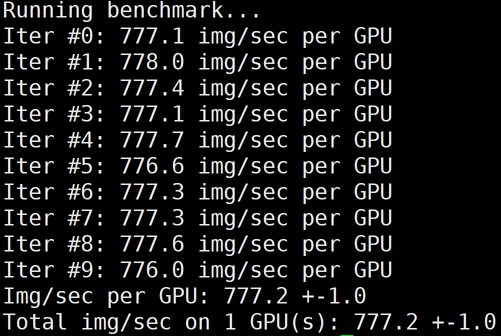
下图为 GT4/A100的单卡 benchmark 结果:
?
单机多卡
执行以下命令,进行测试。
/usr/local/openmpi/bin/mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
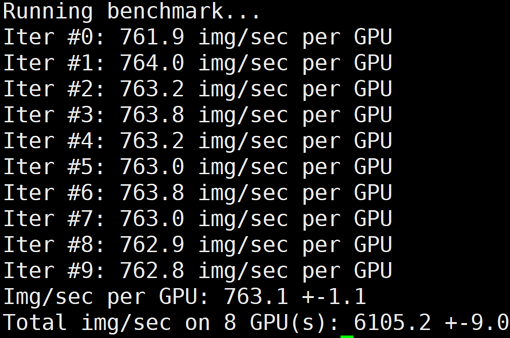
下图为 GT4/A100的单机8卡 benchmark 结果:
?
多机多卡
1. 参考?购买实例?-?启动 docker 镜像?步骤,购买和配置多台训练机器。
2. 配置多台服务器 docker 间相互免密访问,详情请参见?配置容器 SSH 免密访问。
3. 执行以下命令,使用 TACO Train 进行多机训练加速。
/usr/local/openmpi/bin/mpirun -np 8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
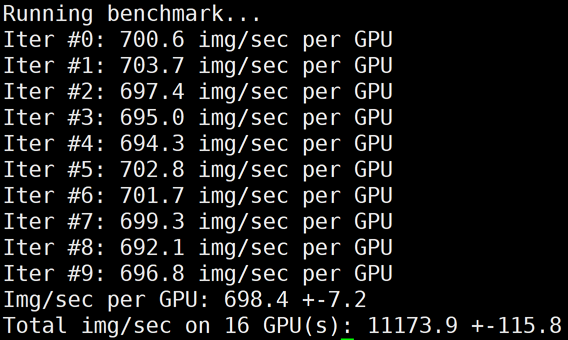
下图为 GT4/A100 的2机16卡 benchmark 结果:
?
LightCC 的环境变量说明如下表:
环境变量 | 默认值 | 说明 |
LIGHT_2D_ALLREDUCE | 0 | 是否使用2D-Allreduce 算法 |
LIGHT_INTRA_SIZE | 8 | 2D-Allreduce 组内 GPU 数 |
LIGHT_HIERARCHICAL_THRESHOLD | 1073741824 | 2D-Allreduce 的阈值,单位是字节,小于等于该阈值的数据才使用2D-Allreduce |
LIGHT_TOPK_ALLREDUCE | 0 | 是否使用 TOPK 压缩通信 |
LIGHT_TOPK_RATIO | 0.01 | 使用 TOPK 压缩的比例 |
LIGHT_TOPK_THRESHOLD | 1048576 | TOPK 压缩的阈值,单位是字节,大于等于该阈值的数据才使用 TOPK 压缩通信 |
LIGHT_TOPK_FP16 | 0 | 压缩通信的 value 是否转成 FP16 |
4. 执行以下命令,关闭 TACO LightCC 加速进行测试。
# 修改环境变量,使用Horovod进行多机Allreduce/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
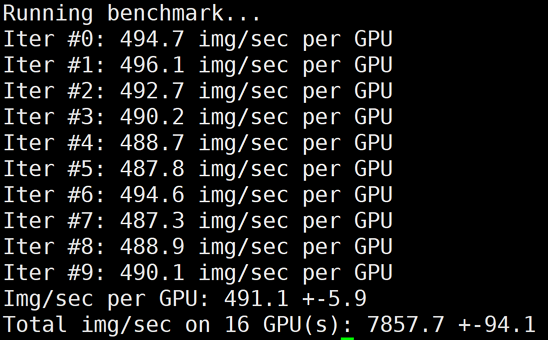
下图为 GT4/A100的2机16卡,关闭 LightCC 之后的 benchmark 结果:
?
5. 执行以下命令,同时关闭 LightCC 和 HARP 加速进行测试。
# 将HARP加速库rename为bak.libnccl-net.so即可关闭HARP加速。/usr/local/openmpi/bin/mpirun -np 2 -H gpu1:1,gpu2:1 --allow-run-as-root -bind-to none -map-by slot mv /usr/lib/x86_64-linux-gnu/libnccl-net.so /usr/lib/x86_64-linux-gnu/bak.libnccl-net.so?# 修改环境变量,使用Horovod进行多机Allreduce/usr/local/openmpi/bin/mpirun -np 16 -H gpu1:8,gpu2:8 --allow-run-as-root -bind-to none -map-by slot -x NCCL_ALGO=RING -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca btl_tcp_if_include eth0 python3 /mnt/tensorflow_synthetic_benchmark.py --model=ResNet50 --batch-size=256
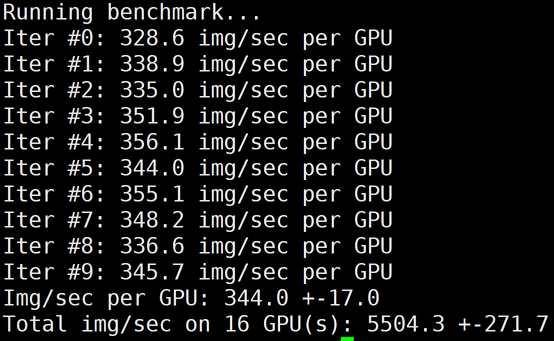
下图为 GT4/A100的2机16卡,同时关闭 LightCC 和 HARP 之后的 benchmark 结果:
?
注意:
测试完如需恢复 HARP 加速能力,只需要把所有机器上的?bak.libnccl-net.so?重新命名为?libncc-net.so?即可。
?
总结
本文测试数据如下:
机器:GT4(A100 * 8)+ 50G VPC 容器:ccr.ccs.tencentyun.com/qcloud/taco-train:ttf115-cu112-cvm-0.4.1 网络模型:ResNet50Batch:256 数据:synthetic data | ? | ? | ? | ? | ? | ? | ? |
机型 | #GPUs | Horovod+TCP | ? | Horovod+HARP | ? | LightCC+HARP | ? |
? | ? | 性能(img/sec) | 线性加速比 | 性能(img/sec) | 线性加速比 | 性能(img/sec) | 线性加速比 |
GT4/A100 | 1 | 777 | - | 777 | - | 777 | - |
? | 8 | 6105 | 98.21% | 6105 | 98.21% | 6105 | 98.21% |
? | 16 | 5504 | 44.27% | 7857 | 63.20% | 11173 | 89.87% |
说明如下:
对于 GT4,相比开源方案,使用 TACO 分布式训练加速组件之后,16卡A100的线性加速比从44.27%提升到89.87%,效果非常显著。
LightCC 和 HARP 只在多机分布式训练当中才有加速效果,单机8卡场景由于 NVLink 的高速带宽存在,一般不需要额外的加速就能达到比较高的线性加速比。
上述 benchmark 脚本也支持除 ResNet50之外的其他模型,ModelName 请参考 Keras Applications。
上述 docker 镜像仅用于 demo,若您具备开发或者部署环境,请提供 OS/python/CUDA/tensorflow 版本信息,并联系腾讯云售后提供特定版本的 TACO 加速组件。

