


概述
本文以使用 EMR 作为存算引擎,在 WeData 上建立编排工作流并使用 Hive SQL、ETL 等任务节点为例,介绍数据工程师如何使用任务开发、工作流设计与调度策略创建一个数据处理工作流程,帮助数据工程师快速了解数据开发模块的基本使用逻辑。
?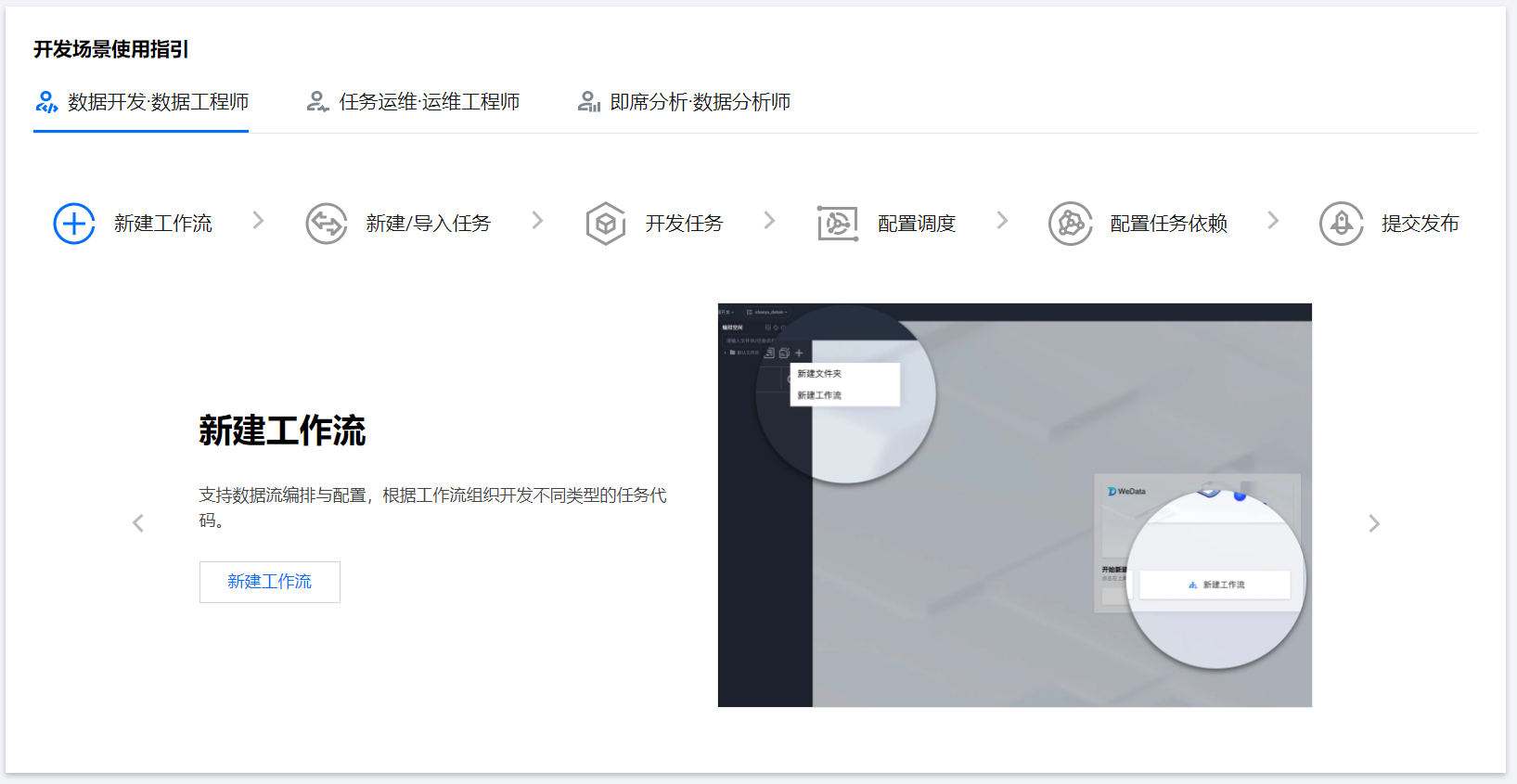
新建工作流来组织数据任务,开发不同类型的代码任务,编排数据工作流程。根据实际需要,可以设置工作流的名称、描述、责任人、执行引擎、参数等属性。
?步骤二:新建任务?
在新建的工作流中,可以新建数据任务,根据需要进行参数配置。可以选择不同的任务类型来完成数据工作流的构建。
数据开发过程通过编排计算任务,将不同类型,使用不同的任务节点按一定的先后顺序进行流程化编排,形成数据工作流。
在构建完成的数据任务节点中,需要编写相应的代码,比如 Python、Shell、Hive SQL 等开发任务,可以使用可视化工具或手动编写代码进行开发。
?步骤五:配置调度?
为开发任务配置调度执行策略,实现数据任务的自动执行。可以设置任务的调度时间、频率、参数传递、执行方式、事件调度等,以便按需求执行数据任务。
数据工作流下游数据任务需要依赖其上游任务的结果进行计算,因此需要设置任务依赖关系。可以定义任务之间的上下游依赖关系,包括数据工作流自依赖与数据任务自依赖。
下面按照以上的步骤演示数据工程师在 WeData 数据开发的整体流程。
流程规划
数据开发流程快速入门的使用规划,整体分为三部分:数据准备、数据开发、提交运维。
?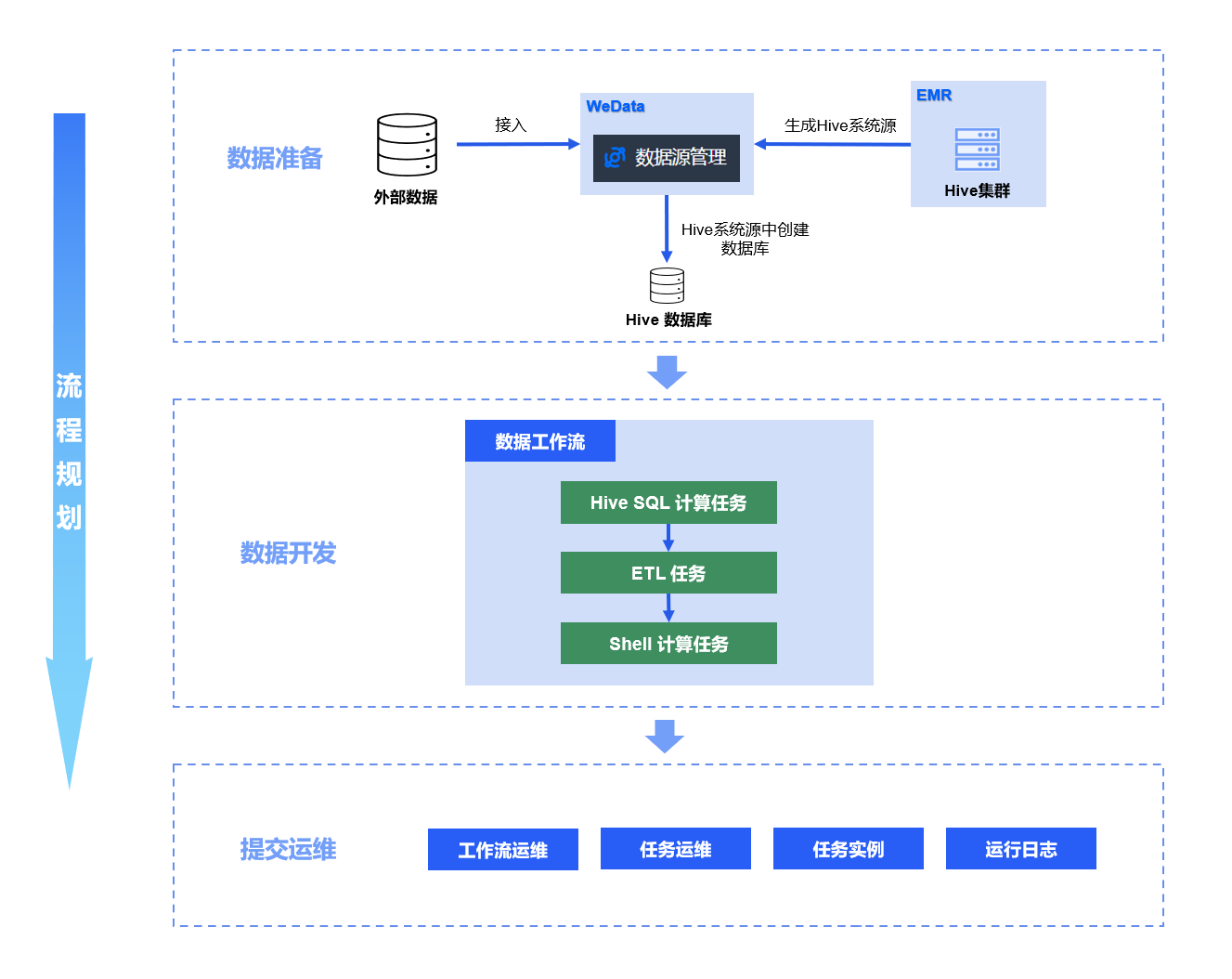
?数据准备:在 MySQL 数据库中准备数据,并将该数据库接入WeData;使用数据开发的数据管理功能,在 EMR 接入的 Hive 系统数据源下准备数据库。后续步骤中提供示例数据与数据库配置流程。
?数据开发:创建一个数据工作流,在数据工作流中使用 Hive SQL 计算任务在 Hive 系统源的数据库下新建数据表,再使用 ETL 计算任务将准备好的 MySQL 数据同步到 Hive 数据表中,最后使用 Shell 计算任务统计该流程的完成时间。
?提交运维:工作流配置完成提交后进入运维状态,其中的 Hive SQL、ETL、Shell 任务会按数据开发流程中配置的调度策略周期性运行,生成实例。通过SQL 查询与日志监控的方式查看数据开发流程的运行成果。
数据准备
在正式进行数据开发流程之前,需要先准备一份示例数据。在数据源管理中接入一个 MySQL 类型的数据源,数据源名称与显示名命名为 demo_mysql,并且接入名为 demo_mysql 的数据库。在其中准备一张名为 mysql_etl_read 的数据表并插入数据。相关的建表与数据插入语句如下:
?#在MySQL数据源demo_mysql数据库中创建一个名为 mysql_etl_read 的数据表CREATE TABLE IF NOT EXISTS demo_mysql.mysql_etl_read (id VARCHAR(20), #序号order_id VARCHAR(20), #订单编号user_id VARCHAR(20), #用户编号gender VARCHAR(20), #性别address VARCHAR(50), #地址vip VARCHAR(50), #用户等级标识telephone VARCHAR(50), #电话id_card VARCHAR(50) #用户身份证);?#在创建完成的 mysql_etl_read 数据表中插入10条数据INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('1','DD20210101','U0001','男','上海市静安区','普通用户','13800000001','310101200001011111');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('2','DD20210102','U0002','男','北京市海淀区','普通用户','13900000002','110101200001021122');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('3','DD20210103','U0003','女','广东省深圳市南山区','普通用户','13700000003','440301200001031133');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('4','DD20210104','U0004','女','广东省广州市越秀区','金牌VIP','15800000004','440101200001041144');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('5','DD20210105','U0005','男','江苏省南京市鼓楼区','普通用户','13600000005','320106200001051155');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('6','DD20210106','U0006','女','江苏省苏州市姑苏区','银牌VIP','13500000006','320508200001061166');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('7','DD20210107','U0007','男','浙江省杭州市西湖区','普通用户','15900000007','330106200001071177');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('8','DD20210108','U0008','男','四川省成都市锦江区','普通用户','15600000008','510104200001081188');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('9','DD20210109','U0009','女','上海市徐汇区','铜牌VIP','13800000009','310104200001091199');INSERT INTO `demo_mysql`.`mysql_etl_read` (`id`,`order_id`,`user_id`,`gender`,`address`,`vip`,`telephone`,`id_card`) VALUES ('10','DD20210110','U0010','男','北京市朝阳区','普通用户','13900000010','110105200001101100');
然后回到数据开发模块,在数据管理页面的数据管理目录中,单击右上角
?
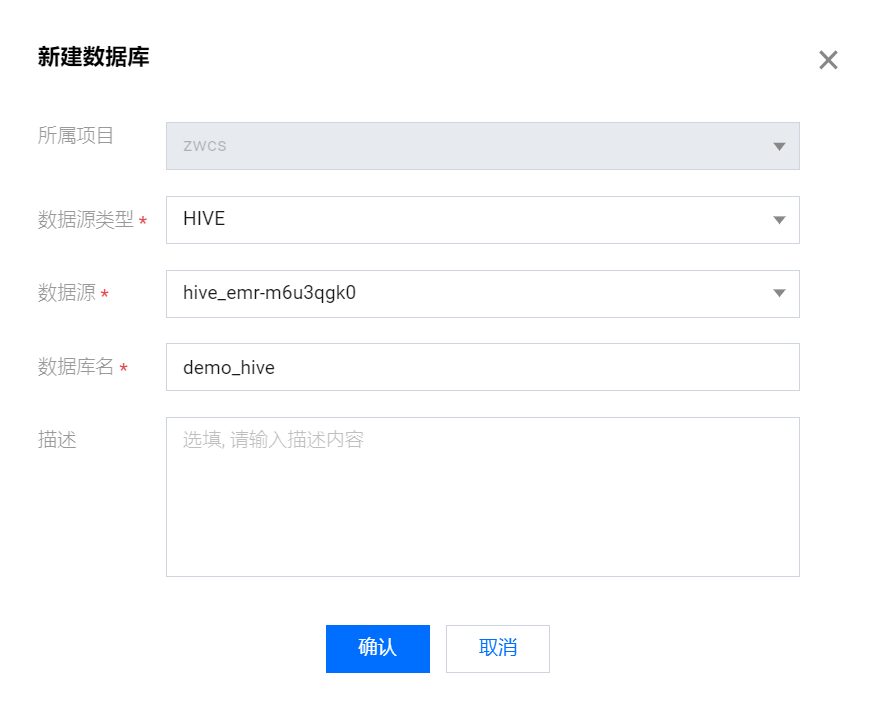
选择 EMR 提供的 Hive 系统源,在其中创建一个名为 demo_hive 的数据库,这里的系统源基于绑定的 EMR 引擎自动生成。配置属性如下:
数据源类型:Hive
数据源:( Hive 系统源)
数据库名:demo_hive
描述:无
?
完成上述准备工作后,即可参考后续步骤进行数据开发流程。
数据开发
步骤一:新建工作流
1. 进入数据工作流。
?
2. 创建工作流。
2.1 工作流创建:在编排空间页面中单击新建工作流 。
2.2 编排目录创建:在编排空间目录右上角单击
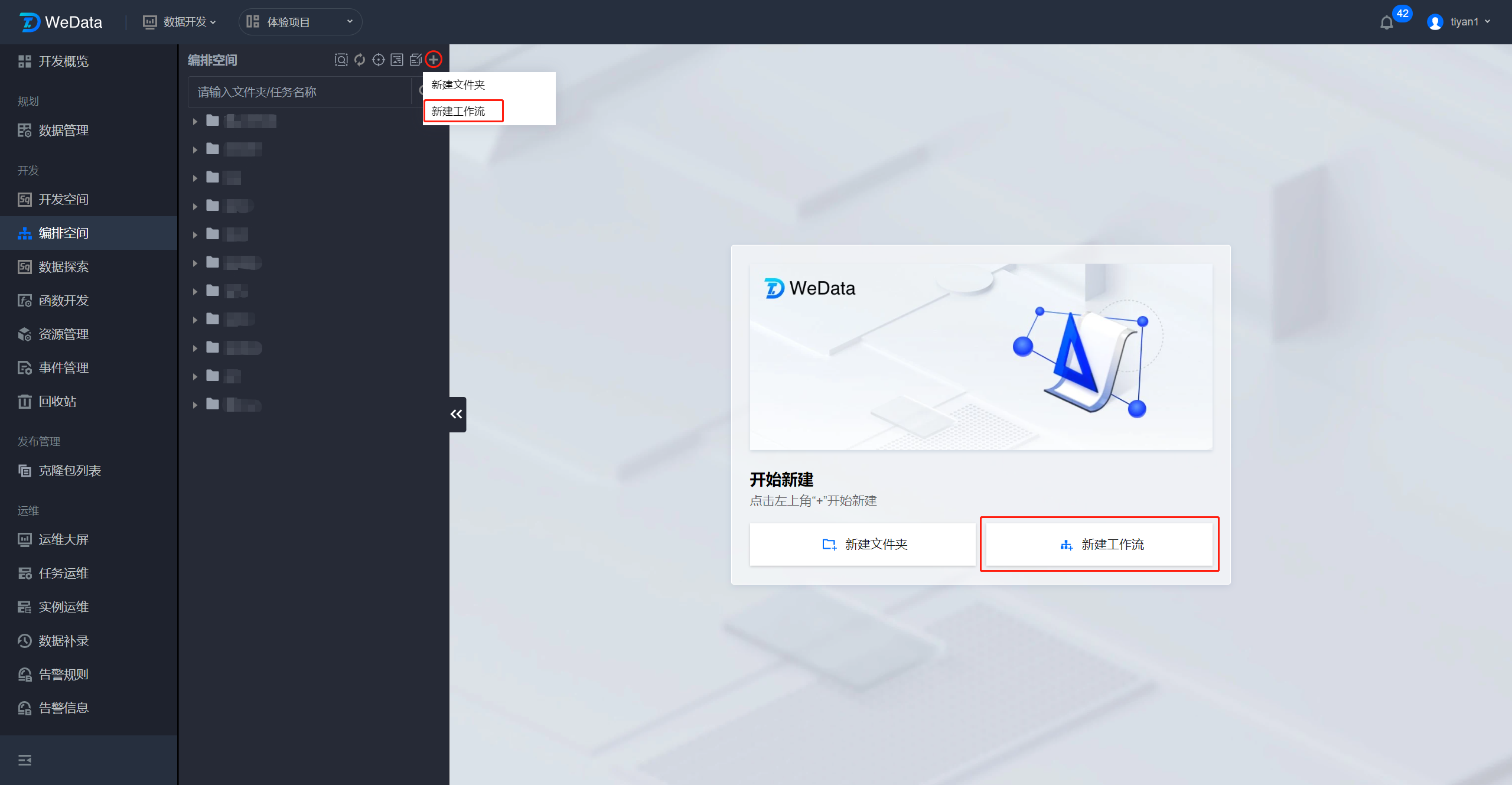
?
在弹框中配置工作流基本信息,包括工作流名称、工作流所在文件夹,确定后即可完成的新建步骤,这里创建一个名为 demo_workflow 数据工作流,并把它创建在默认文件夹下。
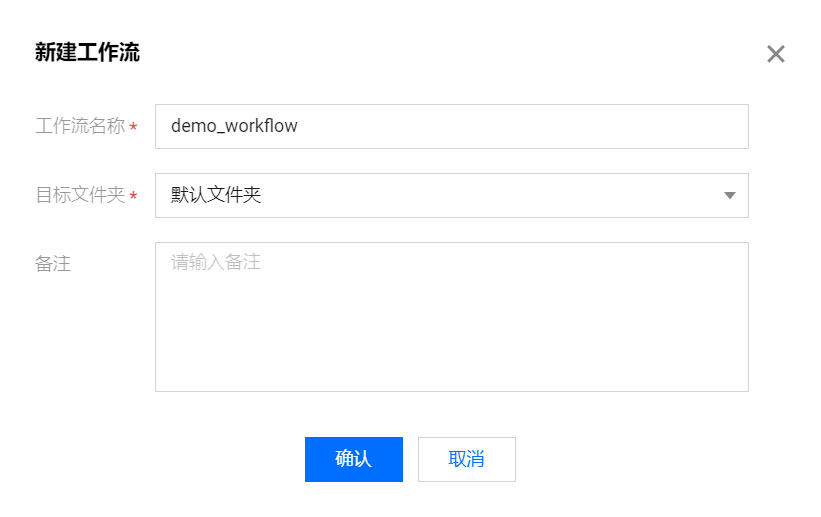
?
3. 打开工作流
在左侧编排空间中的默认文件夹下找到 demo_workflow ,左键移动上去单击两次即可打开 demo_workflow 的工作流画布。
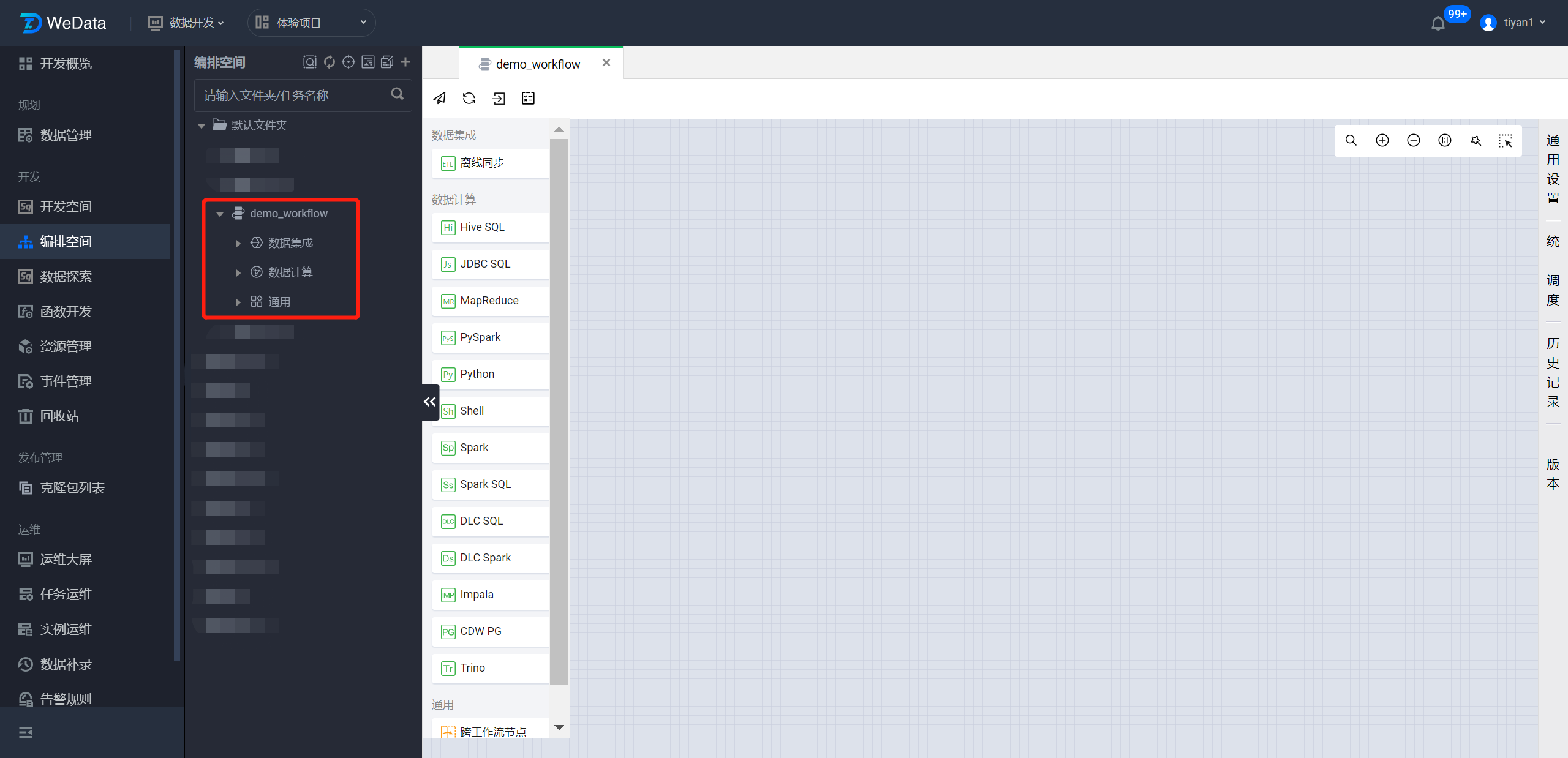
?
步骤二:新建任务
WeData 支持画布新建的方式手动创建计算任务,在 demo_workflow 工作流中新建一个名为 demo_HiveSQL 的 Hive SQL 类型任务。
画布新建:在 demo_workflow 工作流画布中单击需要使用的计算任务类型 。

?
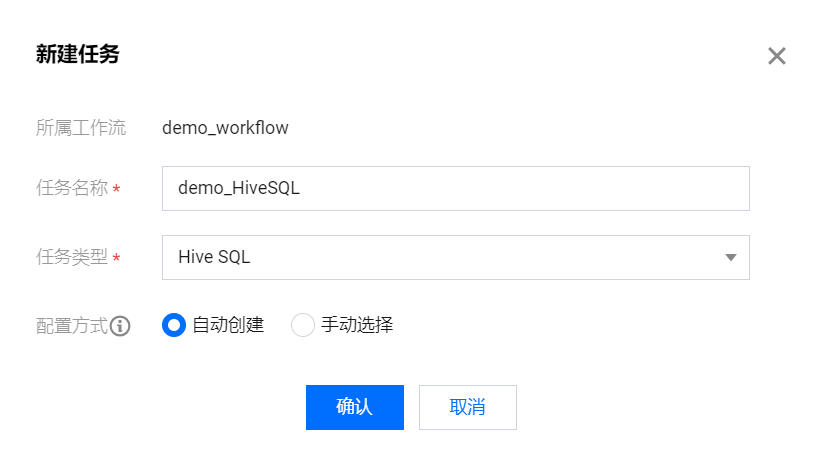
在 demo_workflow 工作流中选择 Hive SQL 类型任务,在弹框中配置基础信息,包括任务名称、配置方式。
这里创建一个名为 demo_HiveSQL 的计算任务,任务类型默认为Hive SQL。
单击确定后,即可将 demo_HiveSQL 创建完成。
?
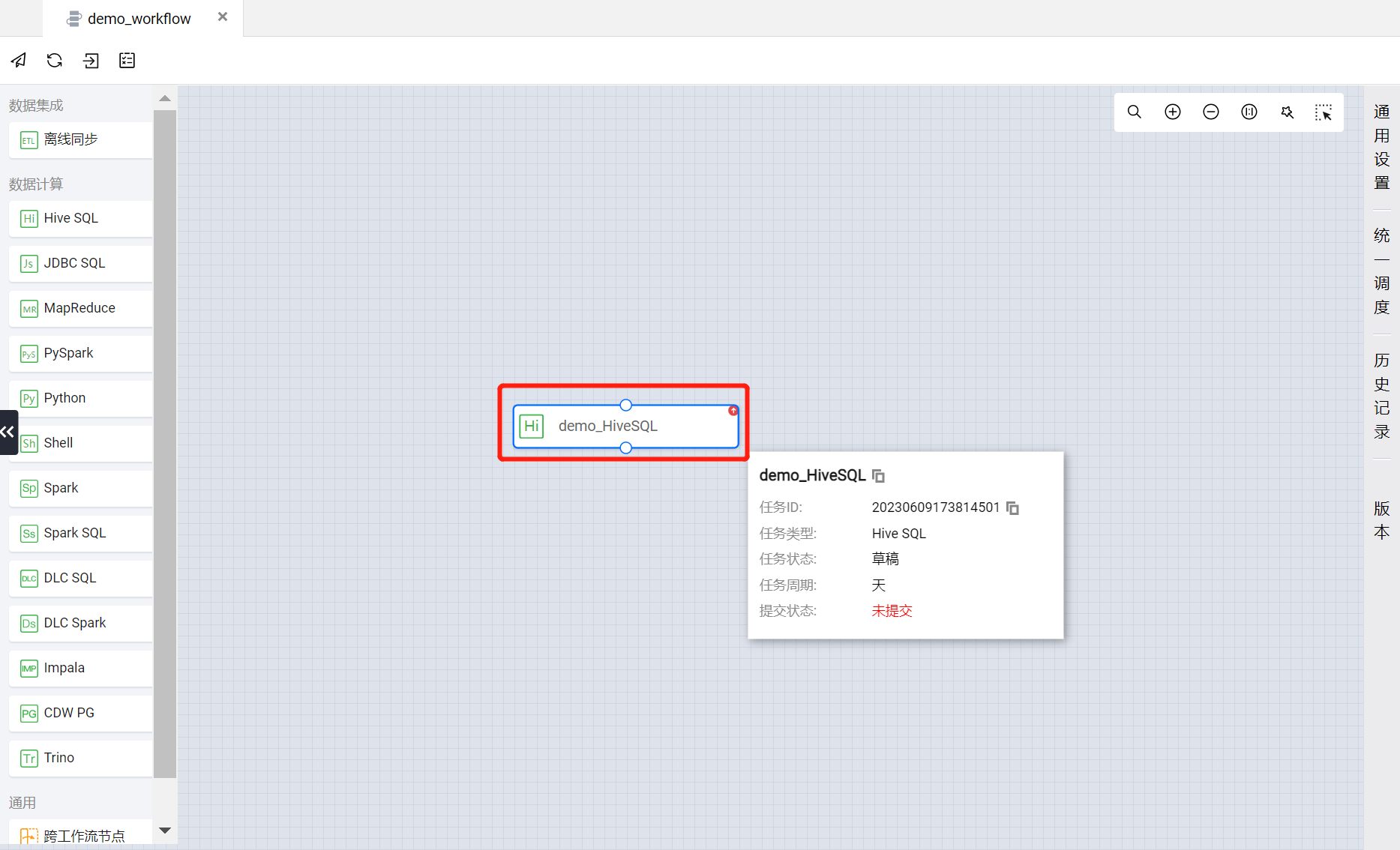
回到 demo_workflow 的画布中,可以看到 demo_HiveSQL 作为一个任务节点出现在画布上。
?
接下来按照上述步骤,在 demo_workflow 工作流中通过画布新建的方式再创建两个计算任务,分别是任务名为 demo_ETL 的离线同步类型任务与任务名为 demo_Shell 的 Shell 类型任务,两者的基本属性配置项如下:
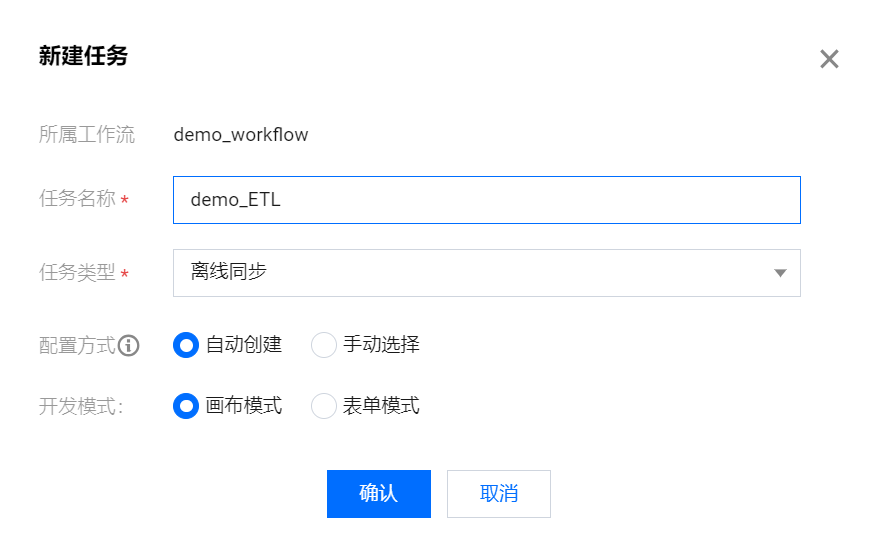
demo_ETL:
任务名称:demo_ETL
任务类型:离线同步(默认)
配置方式:自动创建
开发模式:画布模式
?
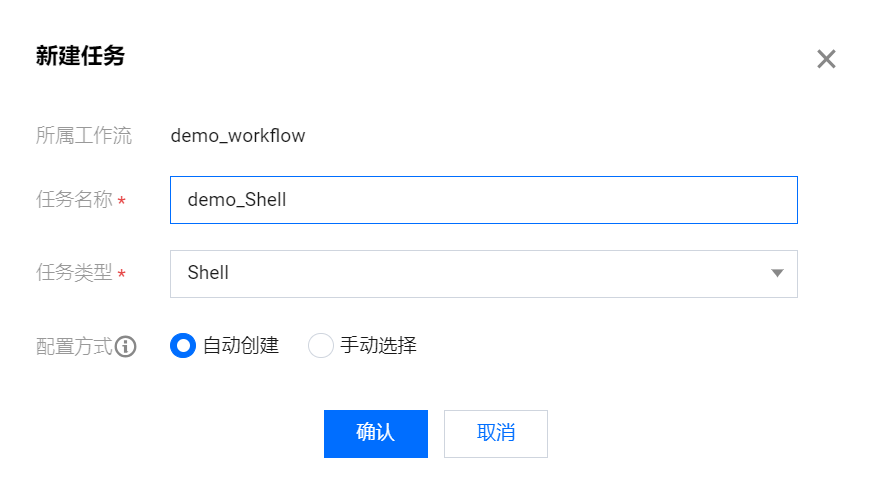
demo_Shell:
任务名称:demo_Shell
任务类型:Shell(默认)
配置方式:自动创建
?
将 demo_ETL 与 demo_Shell 创建完成后,在 demo_workflow 工作流的画布中即可得到三个计算任务。

?
步骤三:工作流编排
将任务节点按数据处理过程进行顺序编排。
WeData 数据开发过程通过编排计算任务,将不同类型,使用不同的任务节点按一定的先后顺序进行流程化编排,形成数据工作流。
把画布中的三个计算任务进行编排,使其按照 demo_HiveSQL > demo_ETL > demo_Shell 的顺序执行数据处理流程。具体编排方式如下:
将三个任务节点在画布中拖动,使其按需要的执行顺序从上至下依次排列,并在节点前后的连接点上拖出连接线,再将连接线拖拽到另一个任务节点上。如下图所示完成开发任务的工作流编排。

?
步骤四:配置任务节点
节点配置:
?demo_HiveSQL:使用 Hive SQL 语句在 demo_hive 数据库中创建名为 hive_etl_write 的 Hive 类型数据表。
?demo_ETL:使用 mysql_etl_read 表作为数据读取节点,hive_etl_write 表作为数据写入节点进行数据同步的操作,将 mysql_etl_read 表中的数据同步到 hive_etl_write 表中。
?demo_Shell:使用 Shell 语句输出 demo_workflow 工作流执行完成的时间。
任务节点的具体配置如下:
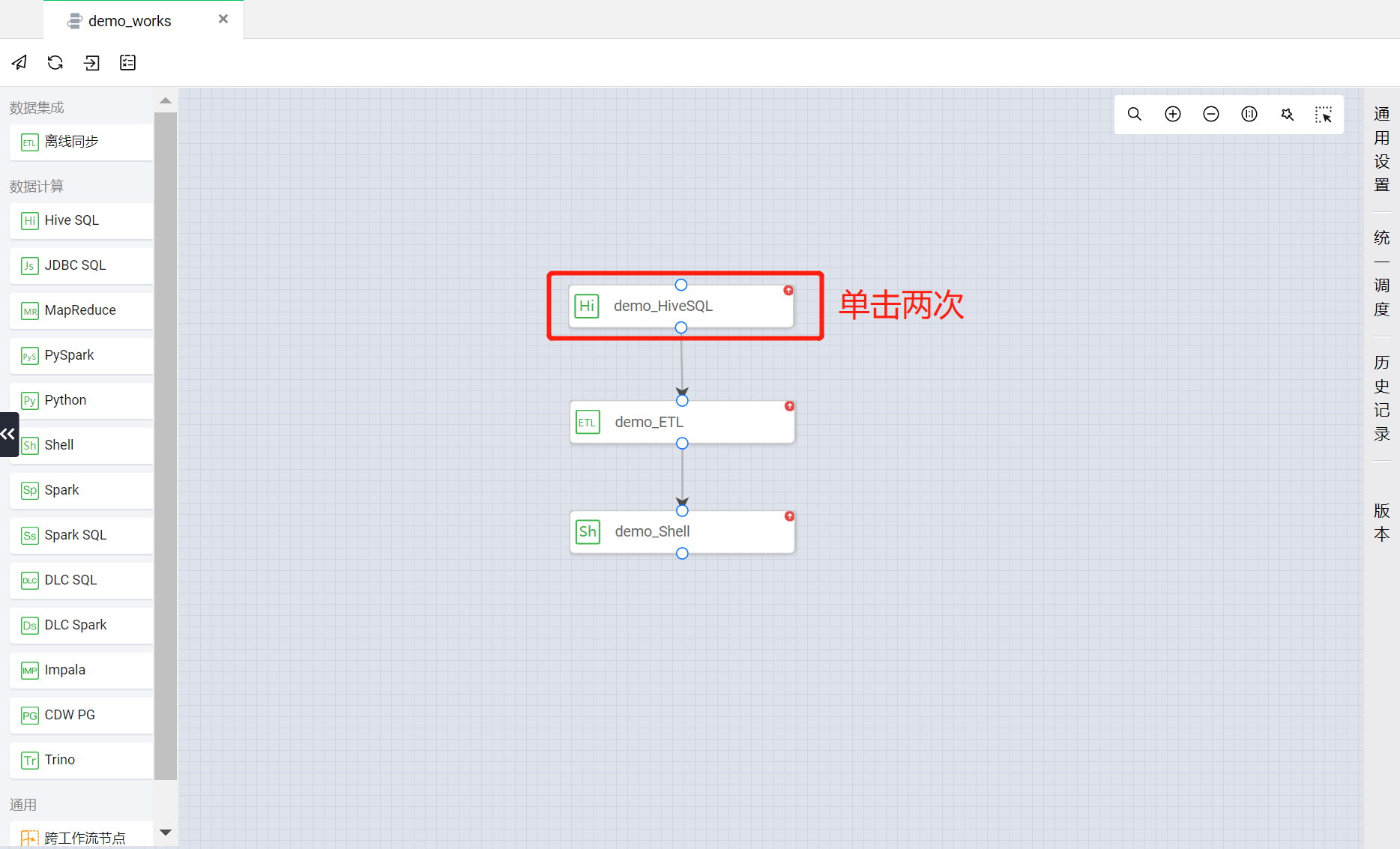
?demo_HiveSQL 节点?
在 demo_workflow 工作流画布中,单击两次 demo_HiveSQL 节点即可进入对应任务节点的配置页面。
?
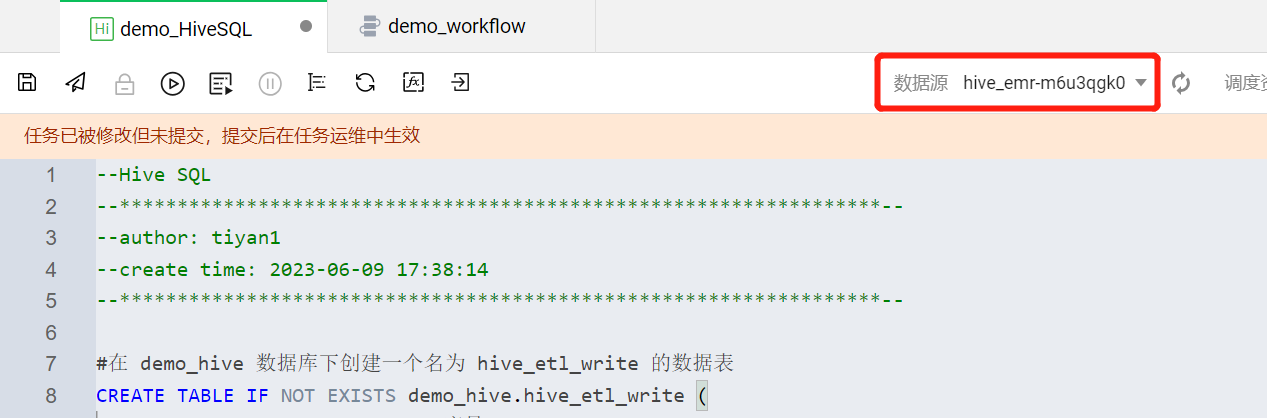
将 Hive SQL 语句写入 demo_HiveSQL 代码编辑区域。demo_hive 数据库与 hive_etl_write 数据表的创建语句示例如下:
#在 demo_hive 数据库下创建一个名为 hive_etl_write 的数据表CREATE TABLE IF NOT EXISTS demo_hive.hive_etl_write (id STRING COMMENT '序号',order_id STRING COMMENT '订单编号',user_id STRING COMMENT '用户编号 ',gender STRING COMMENT '性别',address STRING COMMENT '地址 ',vip STRING COMMENT '用户等级标识 ',telephone STRING COMMENT '电话',id_card STRING COMMENT '用户身份证')ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','LINES TERMINATED BY '\\n'STORED AS TEXTFILE;
?
?
?
语句写入后,需要确保把 hive_etl_write 数据表创建在 demo_hive 数据库所在的 Hive 系统源下,这里需要关注下数据源的选取是否合适。
?
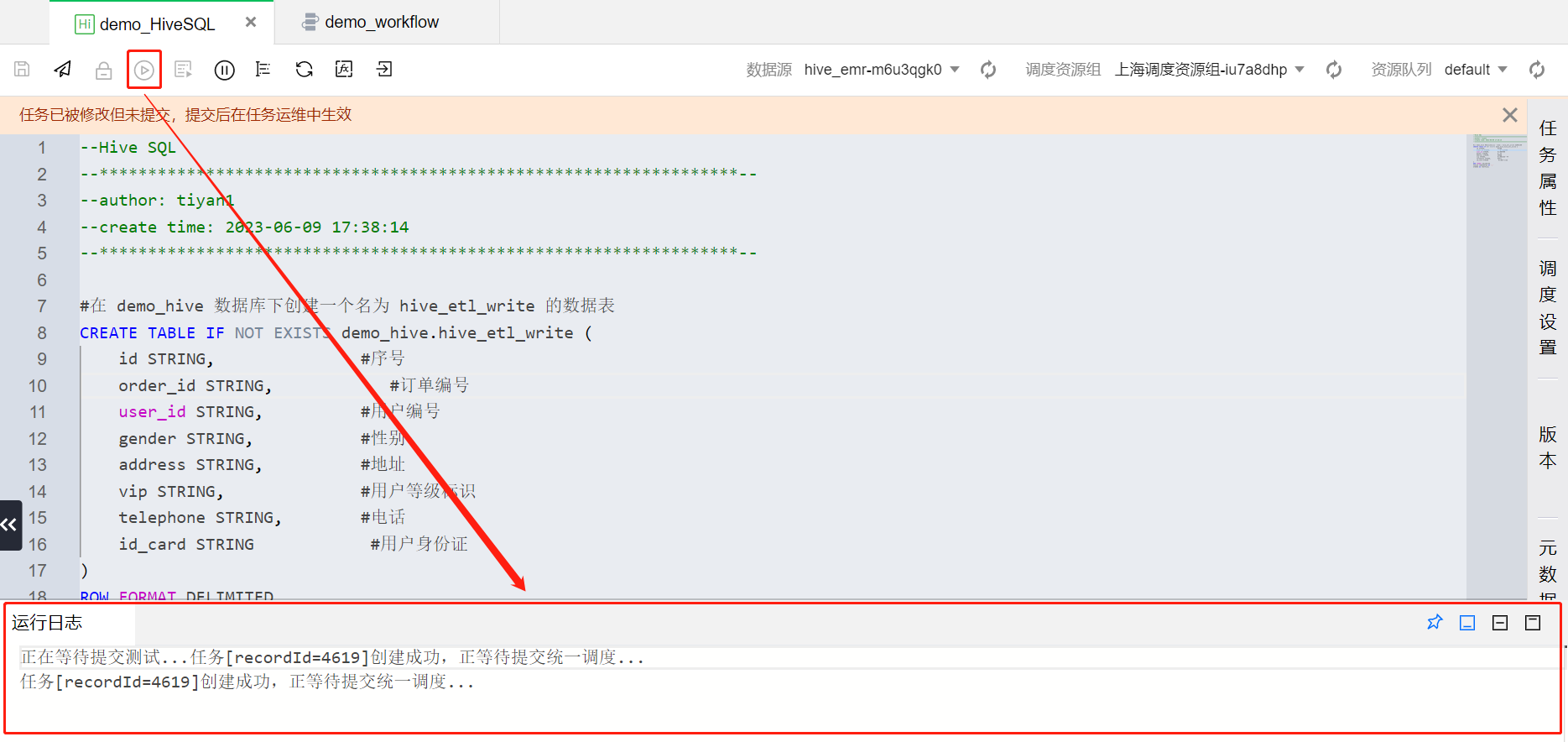
语句写入完成、数据源选择完成后,点击左上角
?
运行过程与结果可以通过运行日志查看,方便关注脚本执行进展与排查问题。执行成功后 demo_hive 数据库与 hive_etl_write 数据表就创建完成了。至此 demo_HiveSQL 任务节点配置完毕。
?
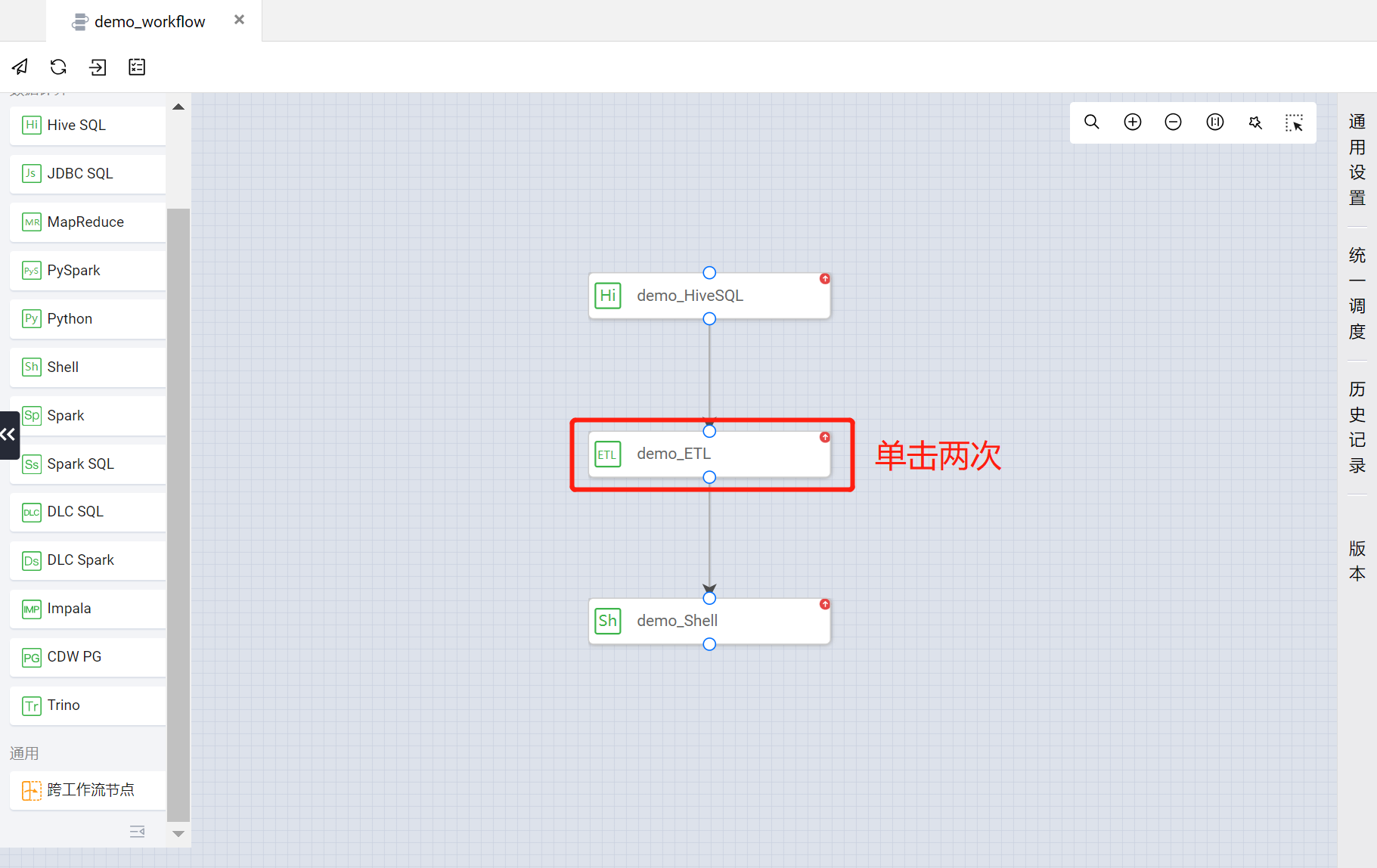
?demo_ETL 节点?
在 demo_workflow 工作流画布中,单击两次 demo_ETL 节点进入对应任务节点的配置页面。
?
读取节点
在左侧读取类型中选择 MySQL 类型,建立一个读取 MySQL 数据表的 ETL 读取节点。
?
单击 MySQL 类型,在新建读取节点弹框中将其命名为 read。

?
读取节点创建后,即可在 demo_ETL 的画布中看到 read 读取节点 。
?
双击读取节点,在画布右侧即可弹出节点的配置项。
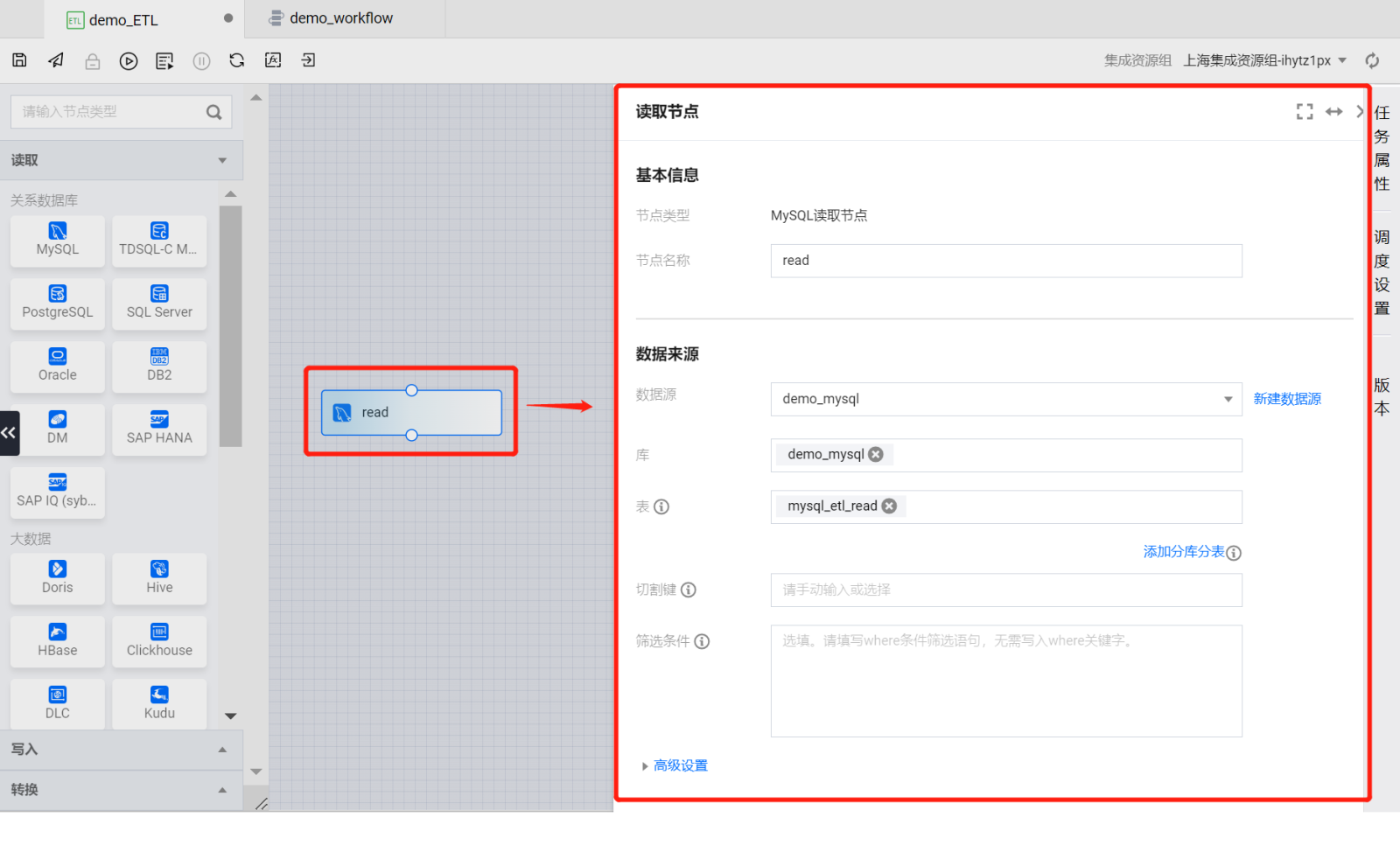
?
按照如下属性进行配置:
基本信息
节点名称:read(默认)
数据来源
数据源:demo_mysql
库:demo_mysql
表:mysql_etl_read
切割键:无(默认)
筛选条件:无(默认)
高级设置:无(默认)
数据字段(默认)
将读取节点的配置项操作完成后,单击右上角关闭按钮,在关闭节点的确认弹框中选择保存即可完成读取节点配置。
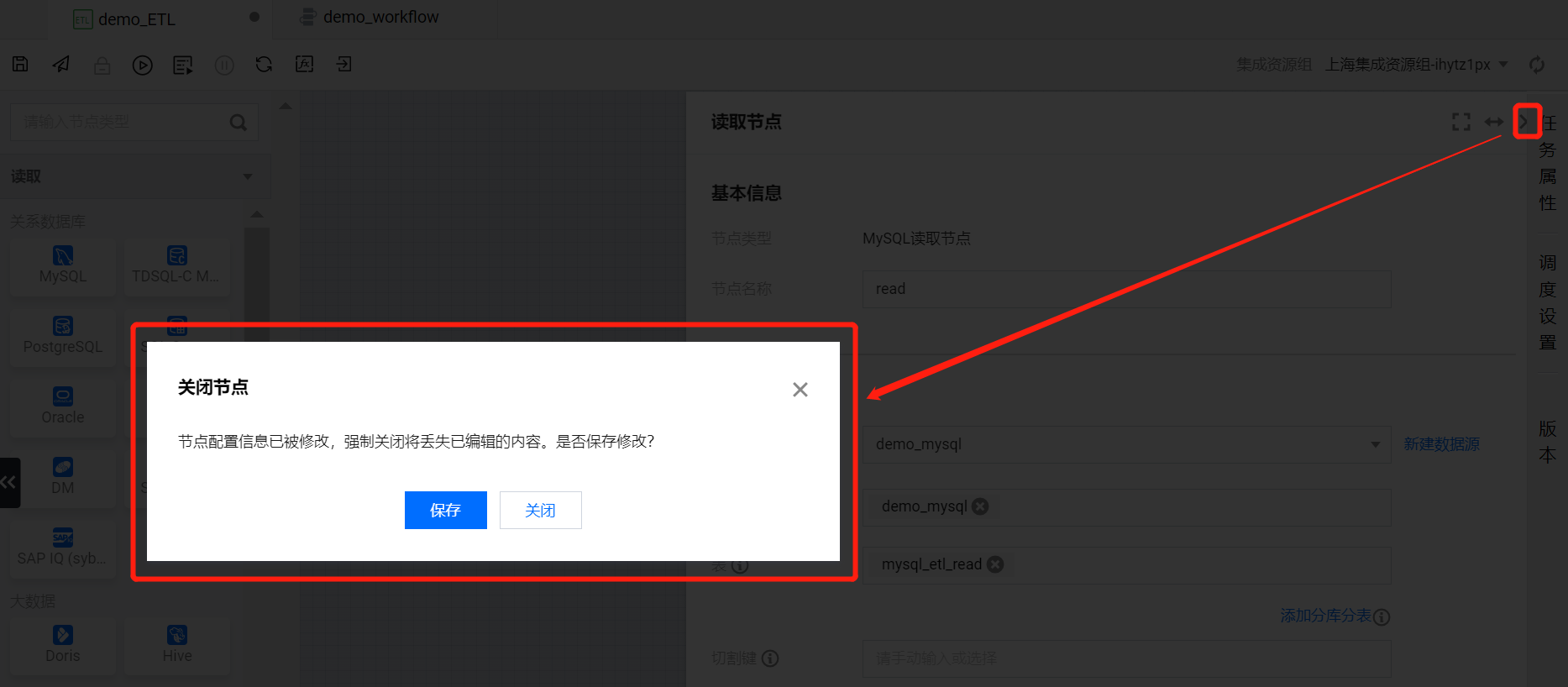
?
接下来回到 demo_ETL 画布页面,再进行写入节点的配置。
写入节点
在左侧写入类型中选择 Hive 类型,建立一个可以将数据写入 Hive 数据表的 ETL 写入节点。
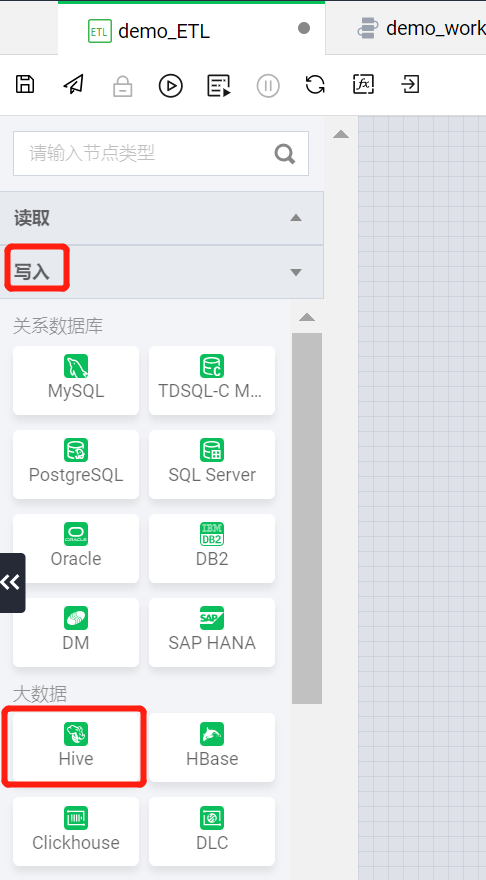
?
单击 Hive 类型,在新建读取节点弹框中将其命名为 write。

?
写入节点创建后,即可在 demo_ETL 的画布中看到 write 写入节点 。
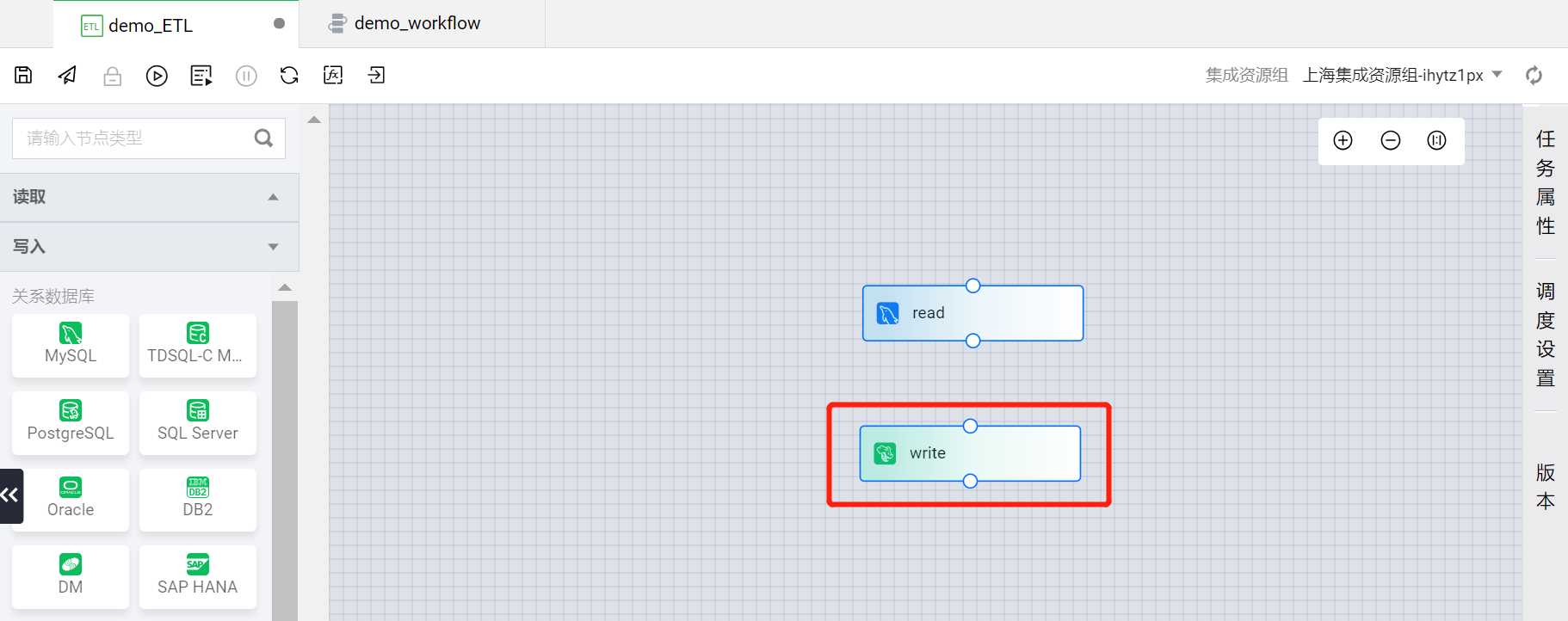
?
在 read 读取节点下方的连接点上拖出连接线,连接在 write 写入节点上方的连接点上。这样就可以建立读取节点与写入节点的数据同步链路。

?
读取节点与写入节点连接完成后,双击写入节点,在画布右侧弹出的节点配置项。
?
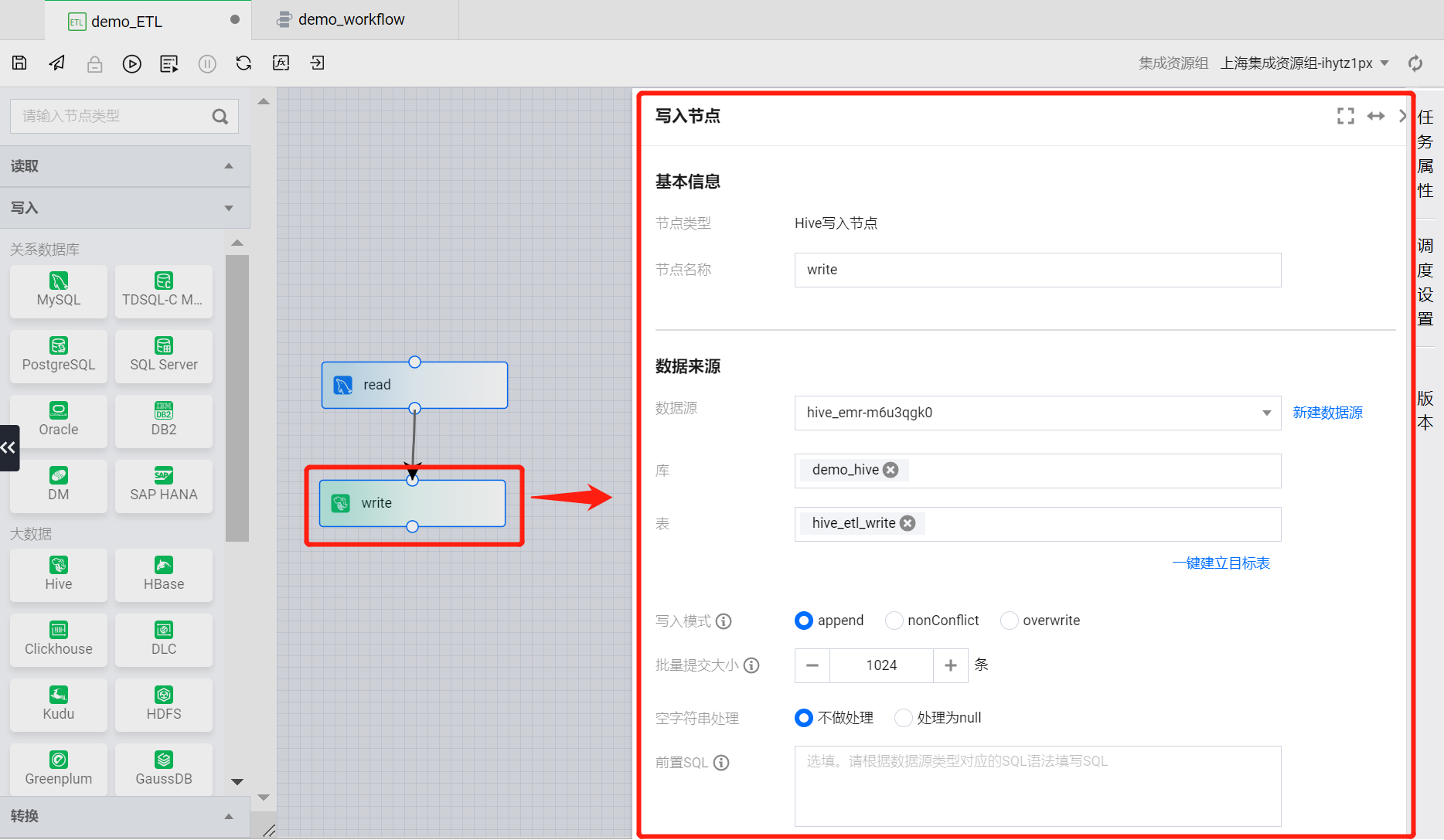
按照如下属性对写入节点配置项进行配置:
基本信息
节点名称:write(默认)
数据来源
数据源:( EMR 的 Hive 系统源)
库:demo_hive
表:hive_etl_write
写入模式:append(默认)
批量提交大小:1024(默认)
空字符串处理:不做处理(默认)
前置 SQL:无(默认)
后置 SQL:无(默认)
高级设置:无(默认)
数据字段(默认)
字段映射
单击配置字段映射,会弹出读取节点与写入节点的数据表字段映射配置弹框。
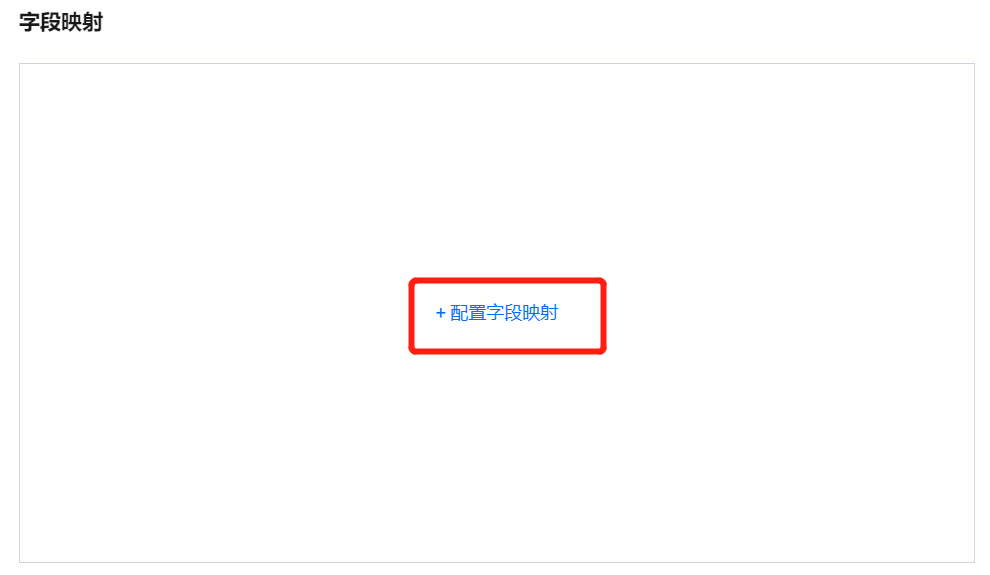
?
在字段映射配置中,选择同名映射,即可将读取节点与写入节点依据相同的字段名称建立字段映射关系,依此来匹配读取与写入的数据同步关系。

?
将写入节点的配置项操作完成后,单击右上角关闭按钮,在关闭节点的确认弹框中选择保存即可完成写入节点配置。

?
至此 demo_ETL 任务节点配置完毕。
?demo_Shell 节点?
在 demo_workflow 工作流画布中,单击两次 demo_Shell 节点进入对应任务节点的配置页面。
?
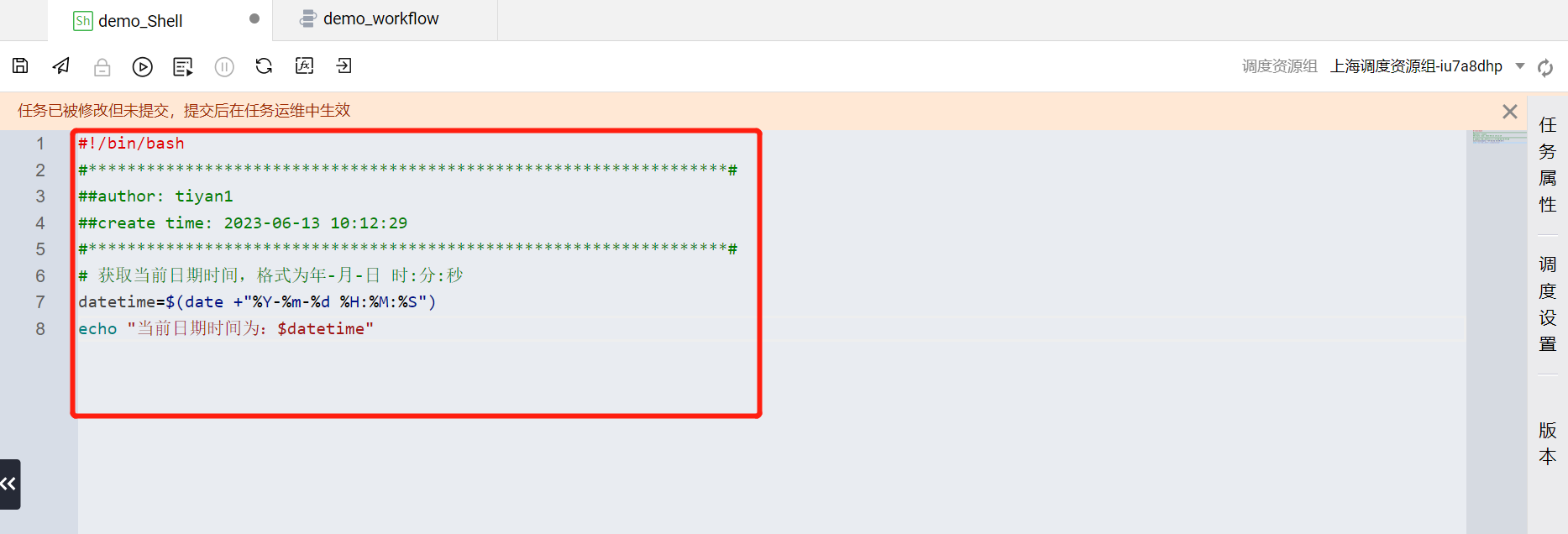
将 Shell 语句写入 demo_Shell 代码编辑区域。获取 demo_workflow 工作流执行完成的日期时间语句示例如下:
# 获取当前日期时间,格式为年-月-日 时:分:秒datetime=$(date +"%Y-%m-%d %H:%M:%S")echo "当前日期时间为:$datetime"
?
语句写入完成后,点击左上角
?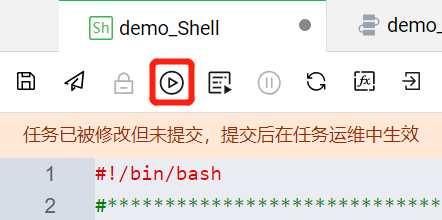
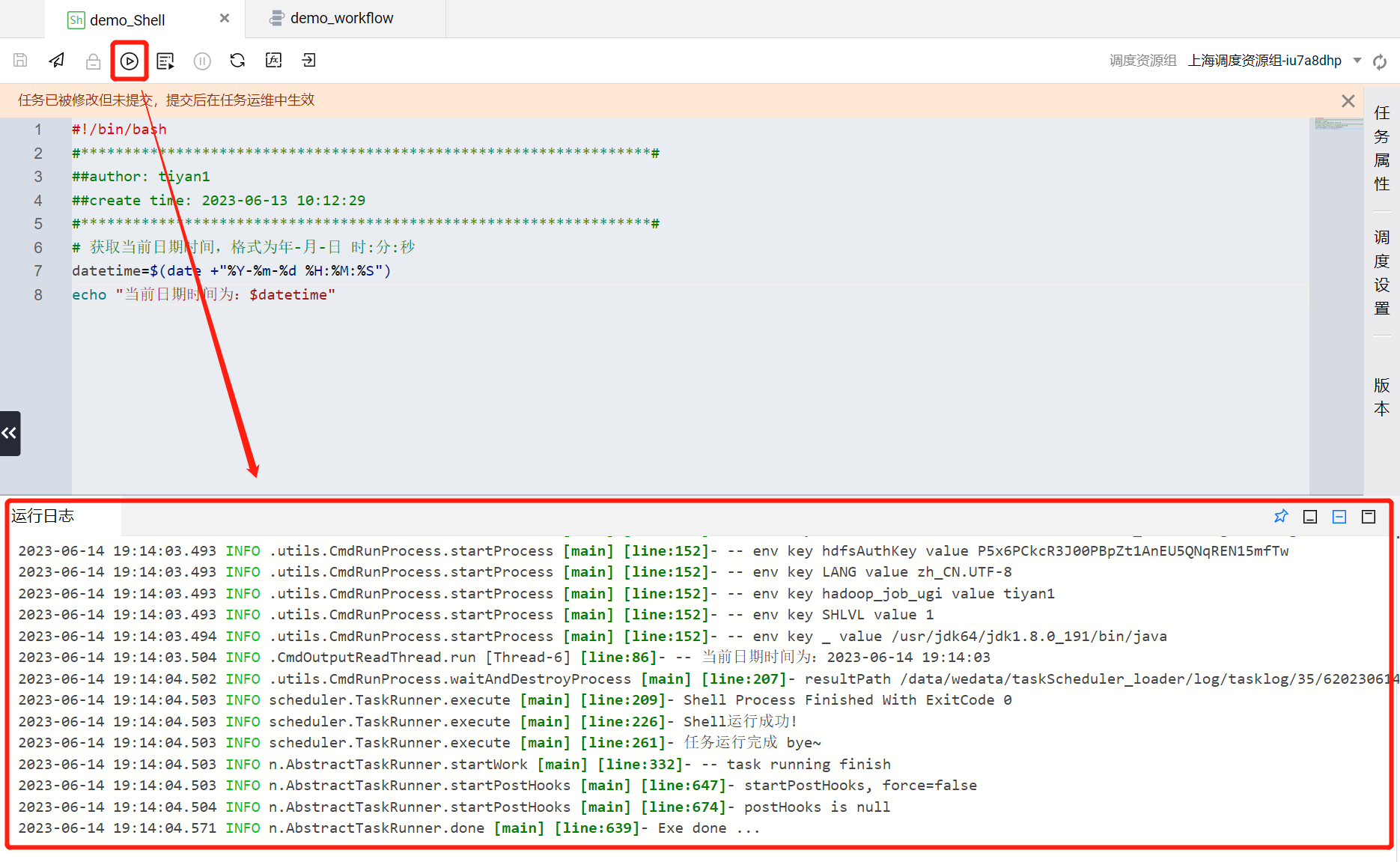
运行过程与结果可以通过运行日志查看,方便关注脚本执行进展与排查问题。执行成功后在运行日志中会输出当前Shell任务执行完成的时间。至此 demo_Shell 任务节点配置完毕。
?
现在三个任务节点按照规划都已经配置完毕,那么接下来就可以为工作流配置调度策略了。
步骤五:配置调度
WeData 提供任务调度可以为每个任务节点单独配置调度策略。这里的 demo_workflow 工作流选择任务调度的方式进行配置。为三个任务节点分别配置调度策略。
demo_HiveSQL
进入 demo_HiveSQL 任务节点的配置页面,单击右侧边栏的调度设置,为该任务节点配置调度策略。

?
按照如下属性对 demo_HiveSQL 执行的调度策略进行配置:
调度策略
调度周期:周期-天(默认,每天执行一次)
生效时间:(默认)
执行时间:00:00(默认,执行时间点)
事件调度
配置监听事件:无(默认)
依赖配置
自依赖:无序串行(默认)
工作流自依赖:否(默认)
上游依赖任务(默认)
参数传递(默认)
高级设置(默认)
配置完成后,在任务节点配置页面左上角单击
?
在后续步骤中将 demo_HiveSQL 任务发布后,将按照当前调度策略在每天00:00执行一次。
demo_ETL
进入 demo_ETL 任务节点的配置页面,单击右侧边栏的调度设置,为该任务节点配置调度策略。
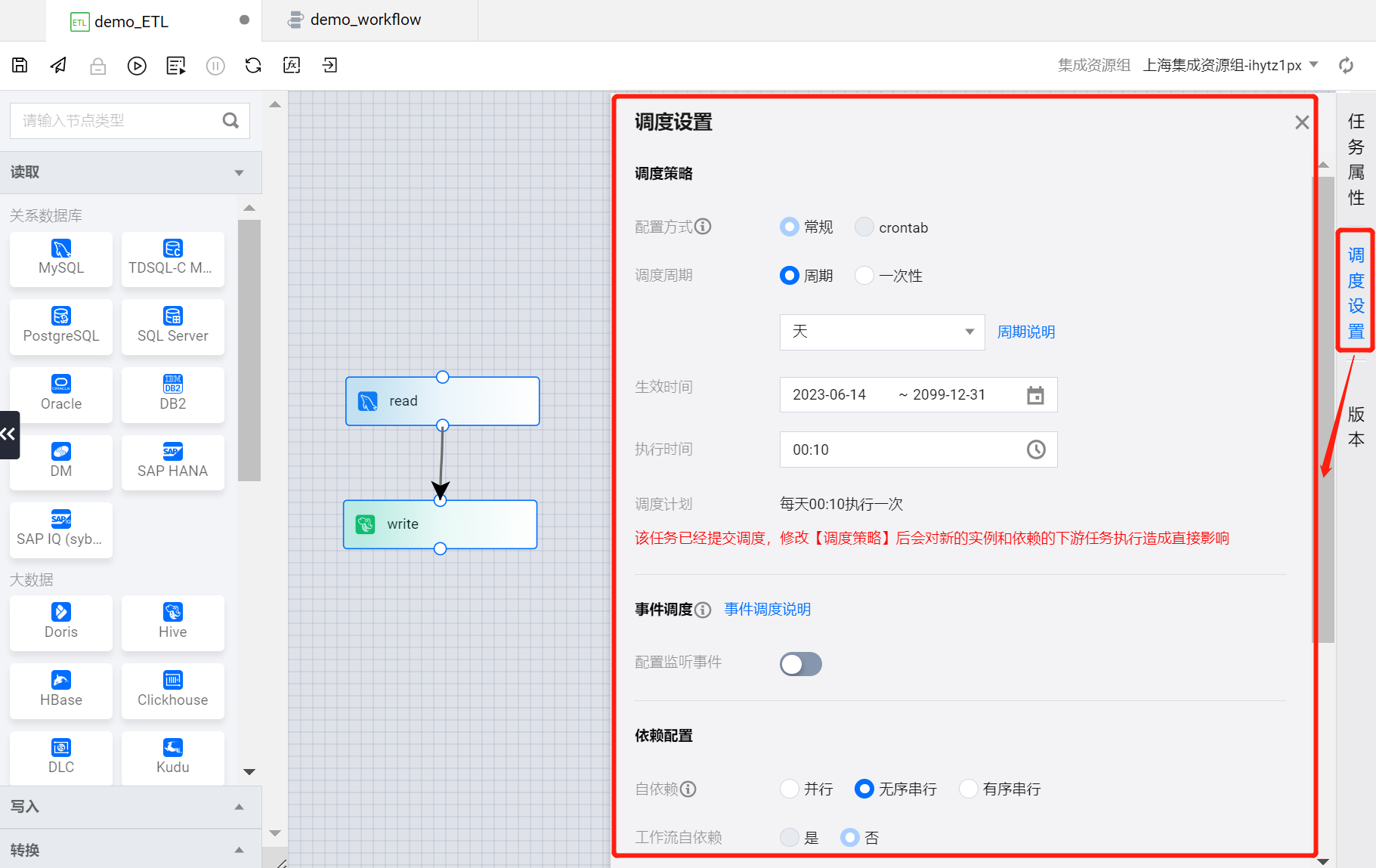
?
按照如下属性对 demo_ETL 执行的调度策略进行配置:
调度策略
调度周期:周期-天(默认,每天执行一次)
生效时间:(默认)
执行时间:00:10(执行时间点)
事件调度
配置监听事件:无(默认)
依赖配置
自依赖:无序串行(默认)
工作流自依赖:否(默认)
上游依赖任务(默认)
高级设置(默认)
配置完成后,在任务节点配置页面左上角单击

?
在后续步骤中将 demo_ETL 任务发布后,将按照当前调度策略在每天00:10执行一次。
demo_Shell
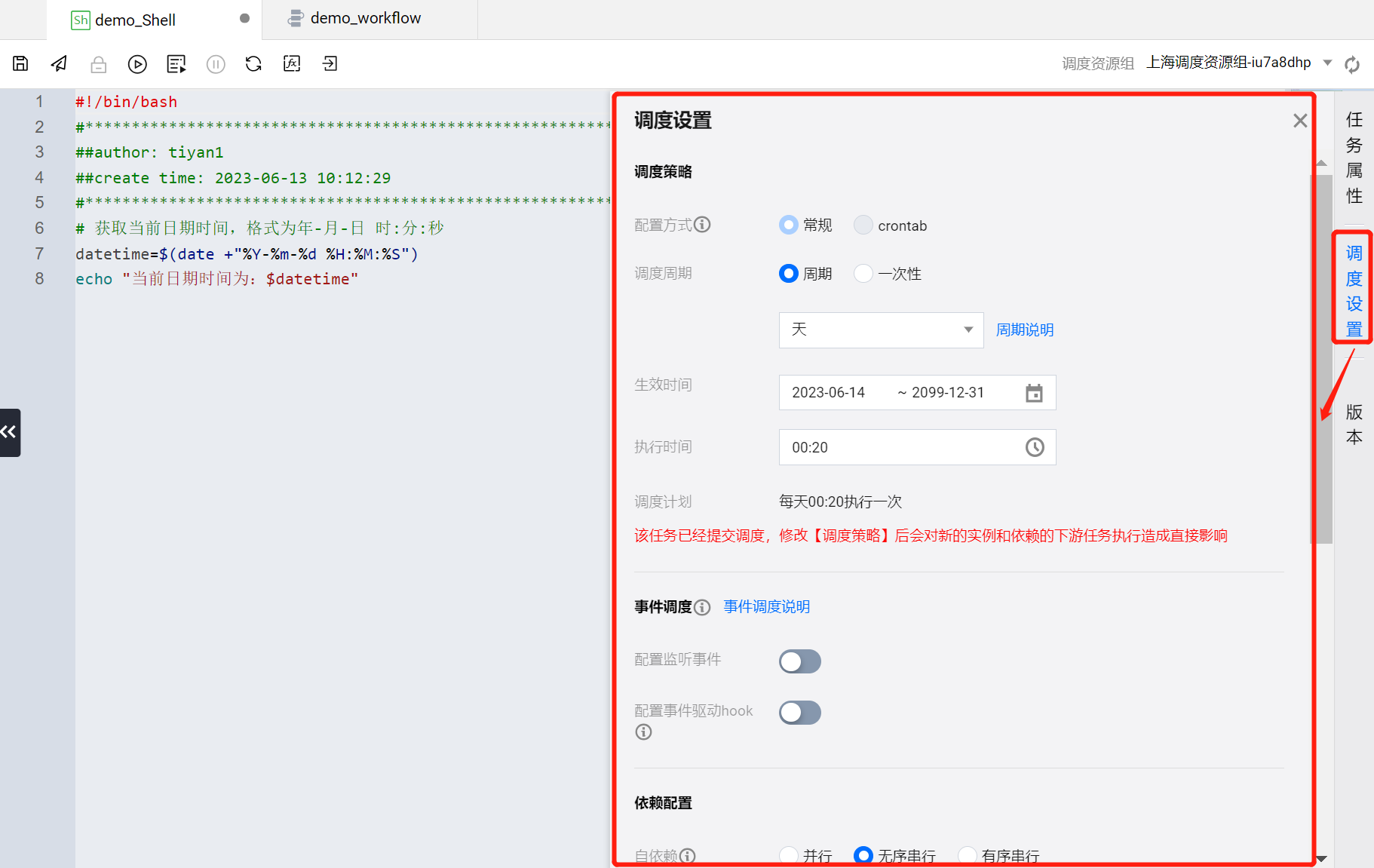
进入 demo_Shell 任务节点的配置页面,单击右侧边栏的调度设置,为该任务节点配置调度策略。
?
按照如下属性对 demo_Shell 执行的调度策略进行配置:
调度策略
调度周期:周期-天(默认,每天执行一次)
生效时间:(默认)
执行时间:00:20(执行时间点)
事件调度
配置监听事件:无(默认)
配置事件驱动hook(默认)
依赖配置
自依赖:无序串行(默认)
工作流自依赖:否(默认)
上游依赖任务(默认)
参数传递(默认)
高级设置(默认)
配置完成后,在任务节点配置页面左上角单击

?
在后续步骤中将 demo_Shell 任务发布后,将按照当前调度策略在每天00:20执行一次。
至此,将 demo_HiveSQL、demo_ETL 和 demo_Shell 任务节点的调度策略都配置完成了,在步骤六中将工作流发布后,任务节点的调度策略即可生效。
步骤六:配置任务依赖
demo_HiveSQL、demo_ETL 与 demo_Shell 三个任务节点在工作流中使用连接线编排了上下游依赖关系。在这一步骤中,需要确认任务节点之间的依赖关系是否正确。
按照当前的编排,任务节点间的上下游关系应该是这样的:
任务节点 | 依赖上游任务 | 调度时间 |
demo_HiveSQL | 无 | 每天00:00执行一次 |
demo_ETL | demo_HiveSQL | 每天00:10执行一次 |
demo_Shell | demo_ETL | 每天00:20执行一次 |
那么可以通过下面的操作流程去管理依赖关系:
回到 demo_workflow 工作流的画布页面。任务节点的依赖关系配置方式都是相同的,这里以 demo_ETL 任务节点举例,选中 demo_ETL 进入任务节点配置页面。
?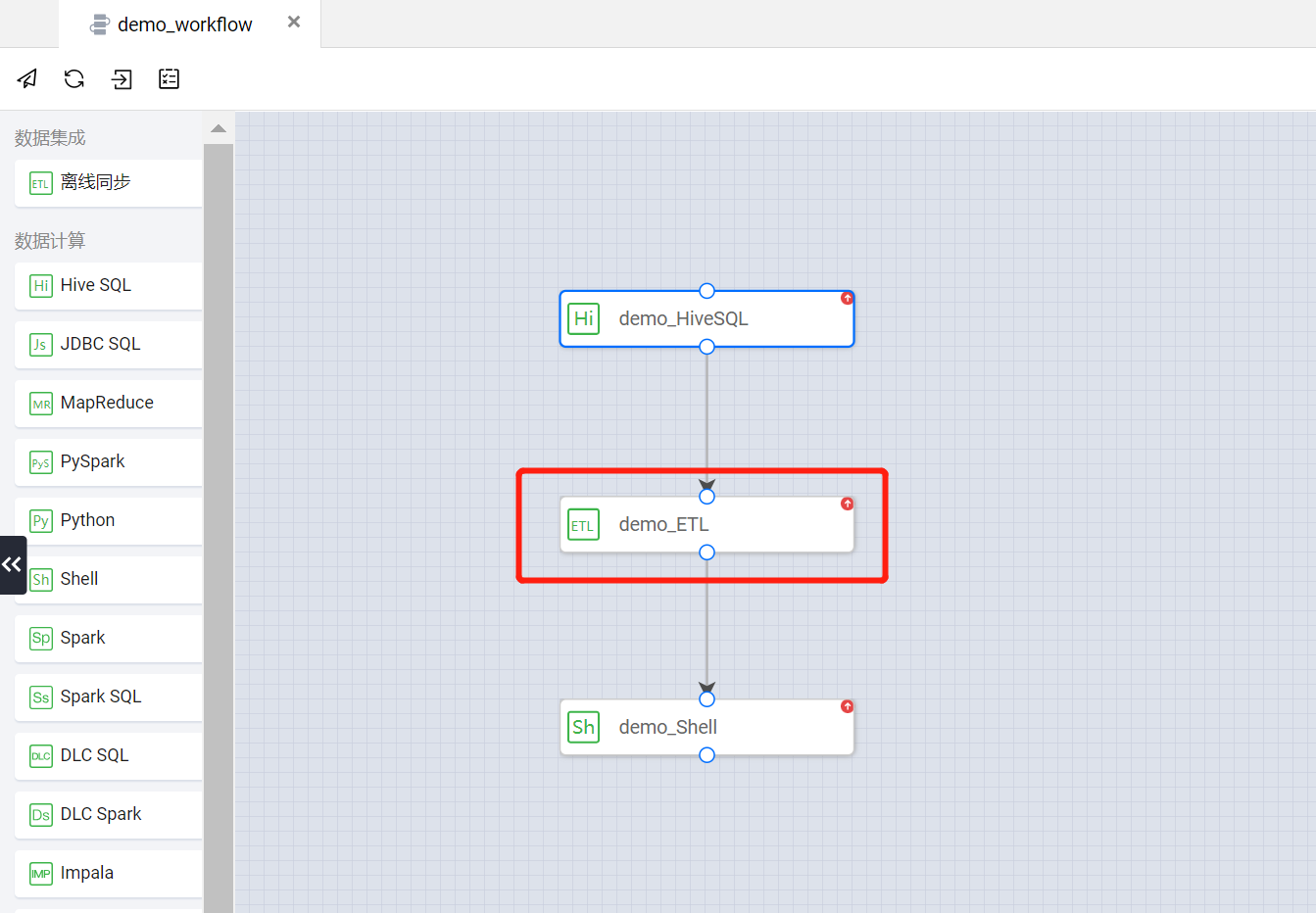
在 demo_ETL 任务节点中单击右侧的调度设置功能,在上游依赖任务区域可以查看当前任务节点的上游依赖任务,也可以手动添加或删除依赖关系。通过该功能可以管理工作流中任务节点的上下游依赖关系,并且支持跨工作流的任务节点依赖关系配置。

?
提交运维
通过以上步骤的配置,设计出了一个简单的数据开发工作流程,接下来提交发布后,即可将该工作流纳入运维阶段进行管理。
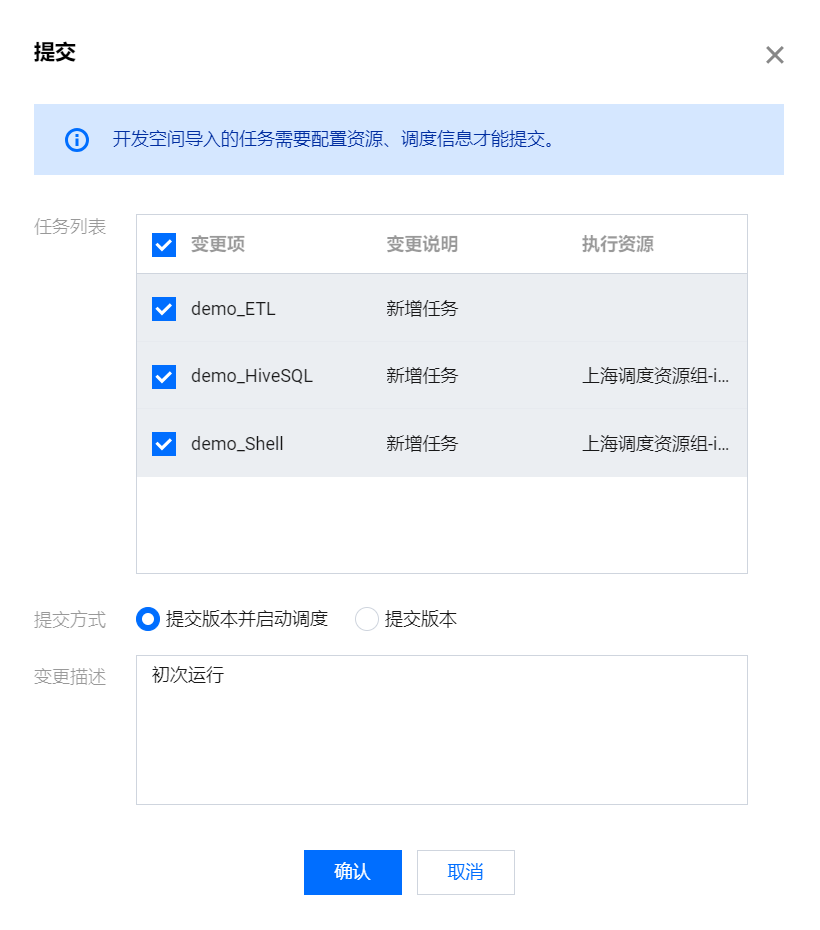
在 demo_workflow 画布页面,单击左上角
?
在提交确认的弹框中,可以看到本次工作流涉及运维的任务节点,确认无误后,提交方式选择提交版本并启动调度,并且在变更描述栏填写任意内容,即可将 demo_workflow 工作流发布到运维阶段。
?
后续可以在任务运维中对数据工作流与任务节点进行运维管理。
在任务运维>工作流列表中关注 demo_workflow 工作流的运行情况。
?
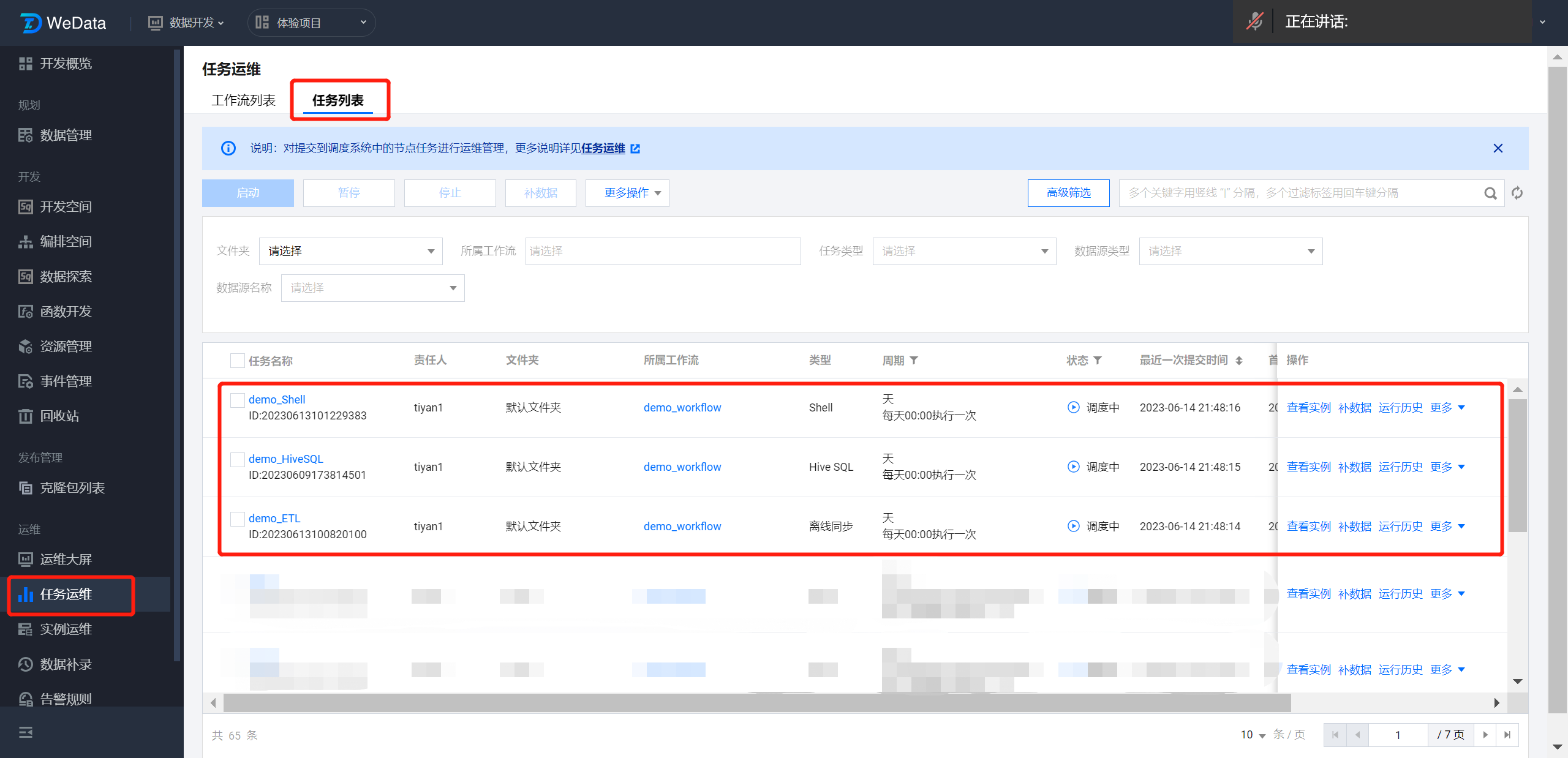
在任务运维>任务列表中关注 demo_HiveSQL、demo_ETL 与 demo_Shell 任务节点的运行情况。
?
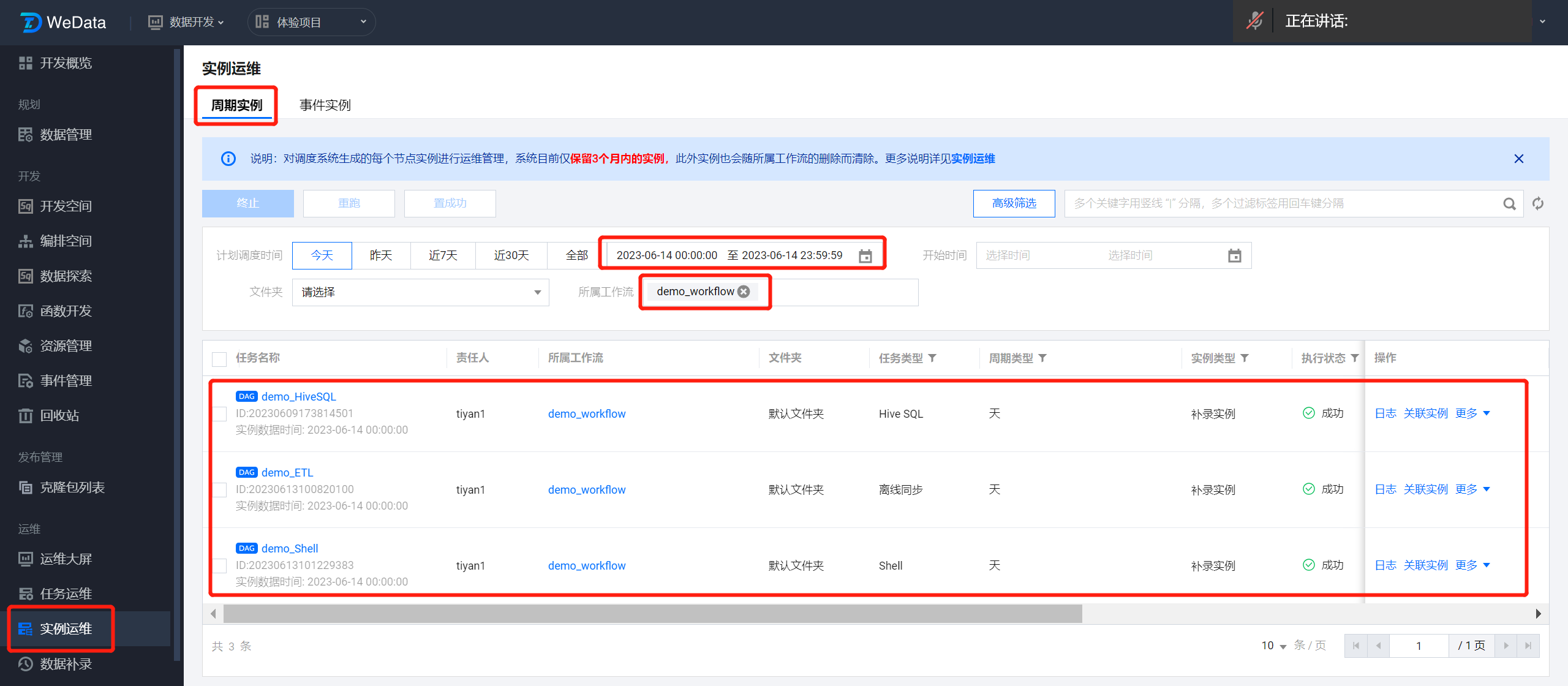
demo_workflow 工作流依据调度策略在每天 00:00 执行后,三个任务节点会生成相应的任务实例,通过实例运维>周期实例可以关注任务实例的执行情况。
使用筛选器查找 demo_workflow 工作流中任务节点的生成的实例,筛选内容如下:
计划调度时间:(选择工作流提交运维后的下一天日期,因为按 demo_workflow 的调度策略,他会在次日 00:00 执行生成任务实例)
所属工作流:demo_workflow
?
实例运行成功后,任务节点中的数据处理脚本都已经生效,可以验证一下:
验证一:验证 demo_ETL 任务节点执行结果,读取节点 mysql_etl_read 数据表中的数据是否已同步到写入节点 hive_etl_write 数据表。
进入开发空间,在左侧开发空间目录上方单击
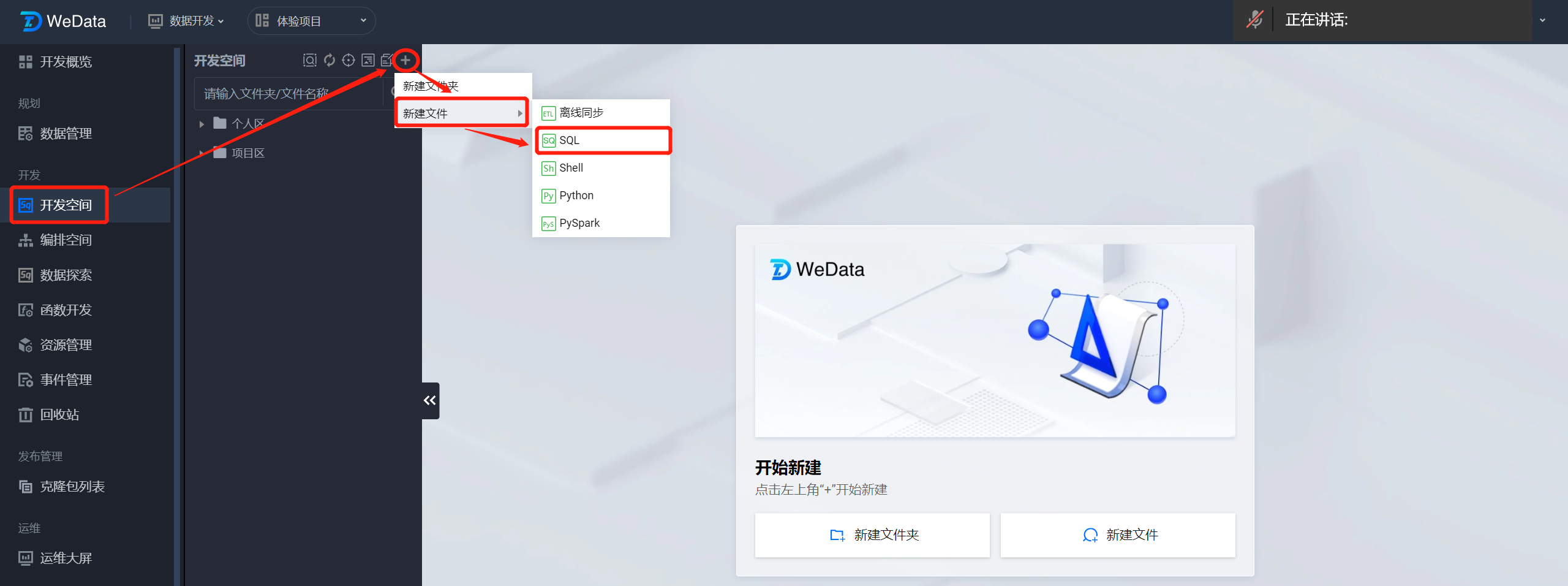
?
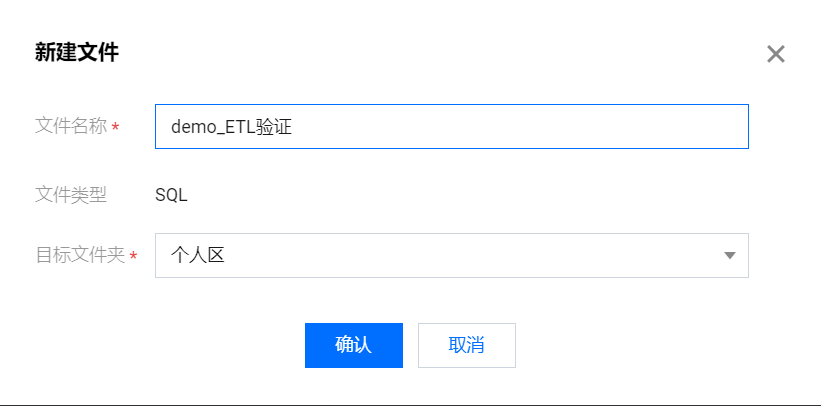
将 SQL 开发文件命名为 demo_ETL 验证,将该文件创建在个人区。
?
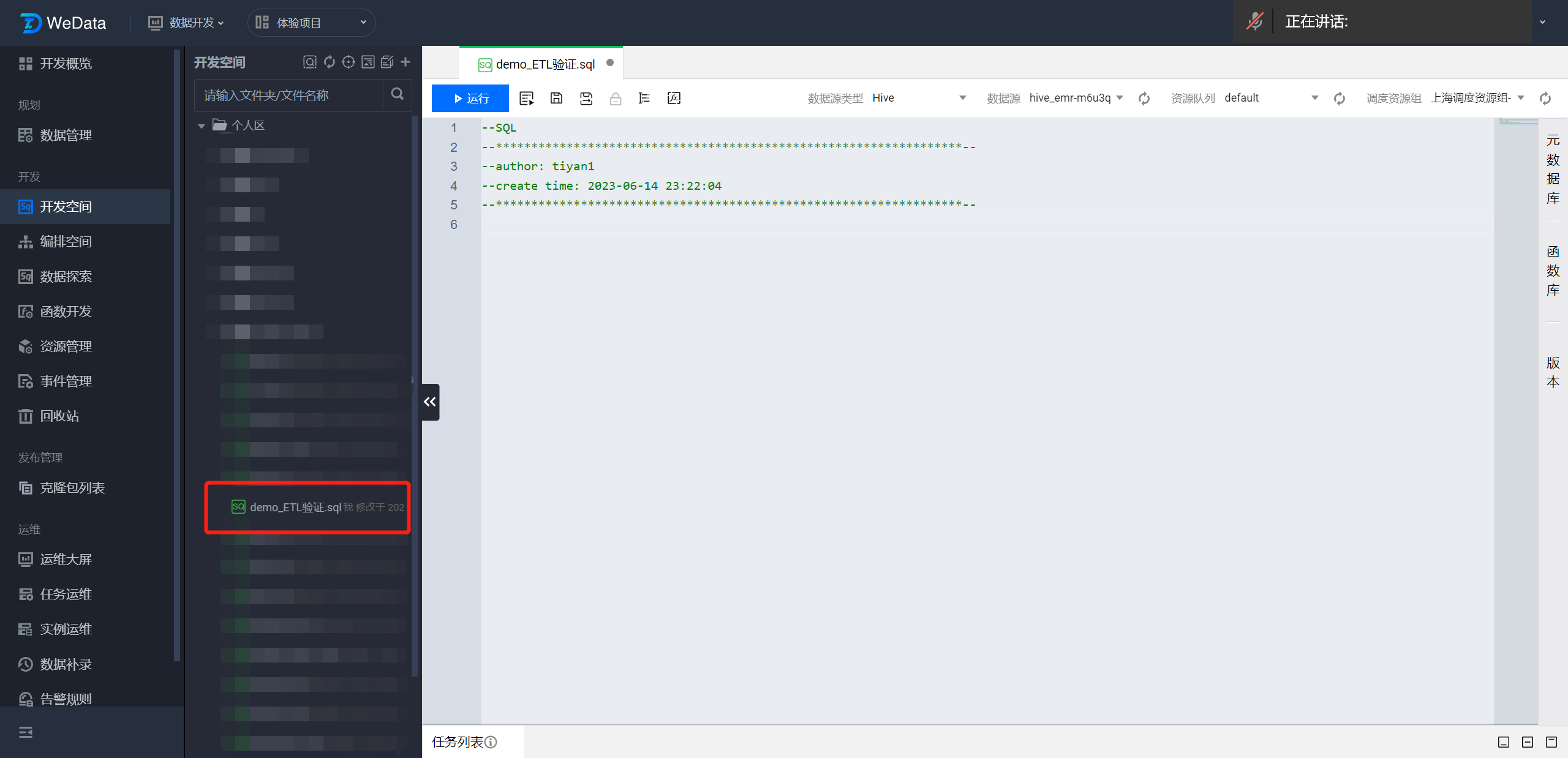
开发空间目录的个人区内找到 demo_ETL 验证 SQL 文件双击打开,然后在 SQL 编辑区域输入查询语句查看 hive_etl_write 数据表中的数据是否符合预期。
?
查询示例语句如下:
select * from demo_hive.hive_etl_write
在写入查询语句后,确保查询的数据源是数据表所在的数据源。比如本章示例中是将 hive_etl_write 数据表创建到了 EMR 提供的 Hive 系统源,那么在数据源这里选择系统源。确认 SQL 语句与数据源无误后,单击运行。

?
SQL 语句运行后会在 SQL 文件界面下方弹出 SQL 任务列表,可以查看 SQL 语句的运行情况。
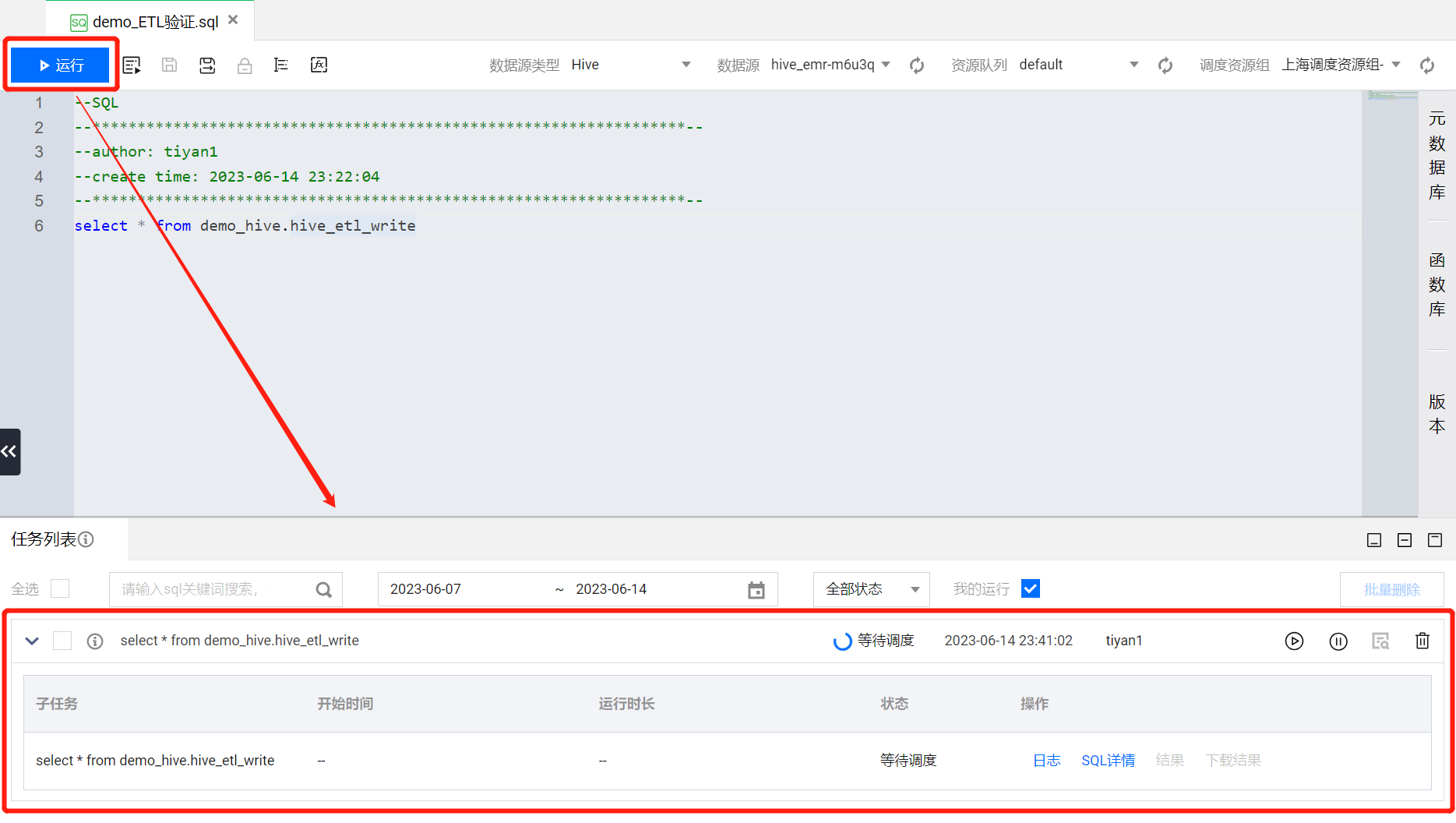
?
等待 SQL 运行成功后,可以单击 SQL 任务操作列下的结果按钮,查看查询结果。

?
可以发现 mysql_etl_read 数据表中的数据已经成功同步到了 hive_etl_write 数据表中。

?
验证二:验证 demo_Shell 任务节点执行结果,获取工作流执行的日期时间。
进入实例运维>周期实例页面,通过筛选找到 demo_Shell 任务节点生成的实例,单击对应实例操作列下的日志,即可进入实例运行日志页面。

?
在日志页面中,翻阅日志可以看到 Shell 任务的执行过程,以及获取到的工作流执行的日期时间。
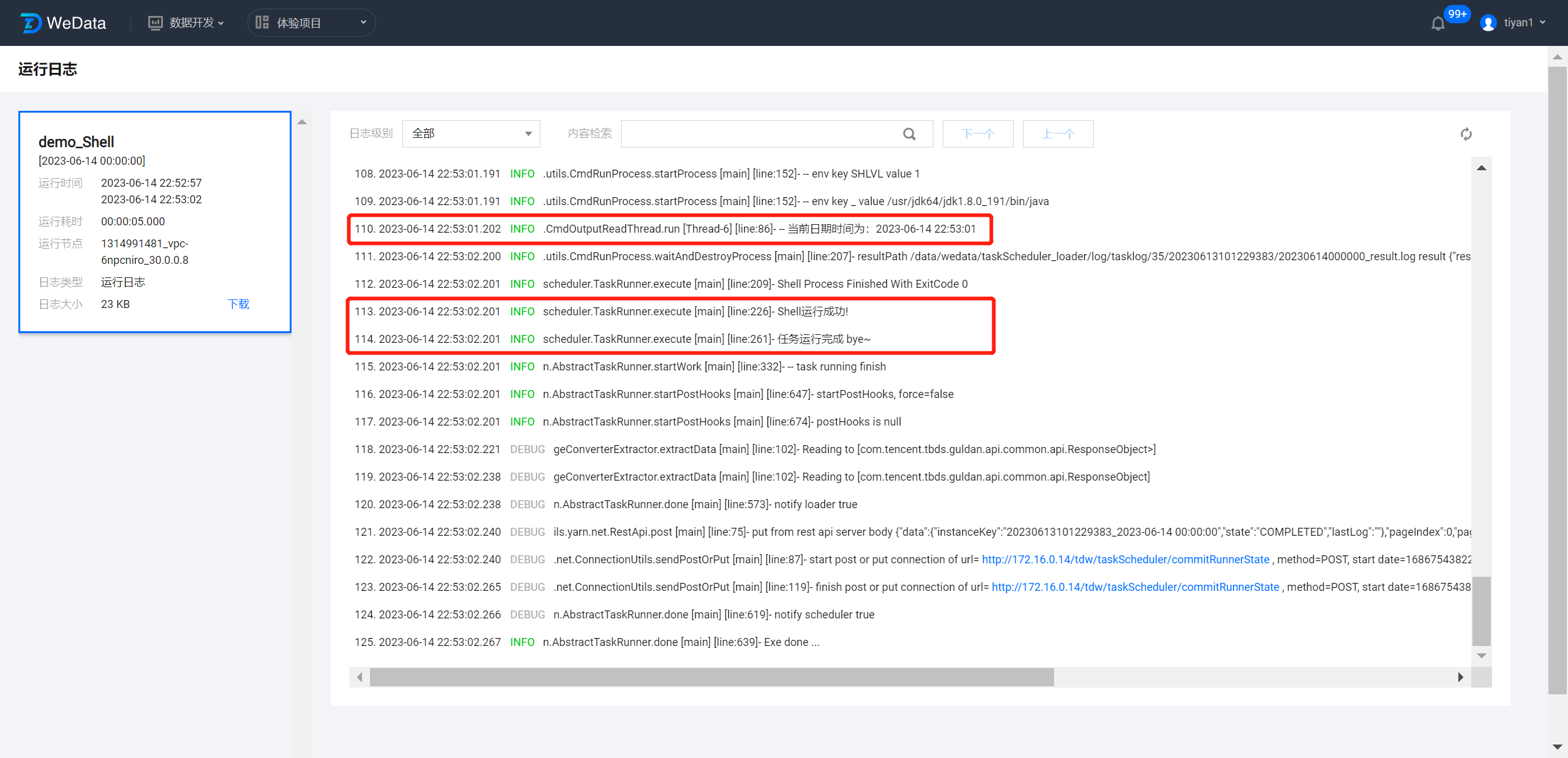
?

