


本文为您介绍如何为普通数据库新建集合、查看集合详情和删除集合。
前提条件
已 登录实例。
新建集合前请确认存在已创建的普通数据库。具体操作请参见 创建数据库。
新建集合
1. 在左侧库表栏,鼠标悬停至已创建的普通数据库名称处,在右侧单击
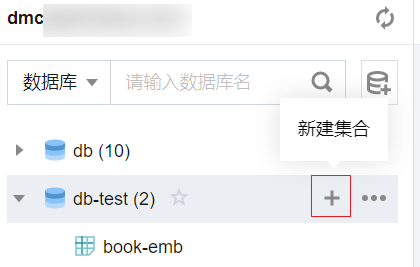
?
2. 在右侧页面,按照页面提示配置参数。

?

?
具体的参数说明如下表所示。
参数名称 | 说明 |
数据库 | 展示当前所选中的数据库名称。可根据实际修改。 |
集合名称 | 自定义集合名称。 命名要求:支持输入1~128个字符,只能使用英文字母,数字,下划线(_),中划线(-),并以英文字母开头。 |
副本数 | 自定义集合的副本数。副本数是指每个主分片有多个相同的备份,用来容灾和负载均衡。 取值范围: 单可用区实例:0。 两可用区实例:[1,节点数-1]。 三可用区实例:[2,节点数-1]。 配置建议:搜索请求量越高的索引,建议设置越多的副本数,避免负载不均衡。 |
分片数 | 自定义集合的分片数。分片是把大数据集切成多个子数据集。 取值范围:[1,100]。例如:5。 配置建议:在搜索时,全部分片是并发执行的,分片数量越多,平均耗时越低,但是过多的分片会带来额外开销而影响性能。 单分片数据量建议控制在300万以内,例如500万向量,可设置2个分片。 如果数据量小于300万,建议使用1分片。系统对1分片有特定优化,可显著提升性能。 |
备注 | 支持输入1~256个字符。 |
开启Embedding | 可勾选是否开启 Embedding。默认不开启。
Embedding 模型提供文本到向量的转换能力,开通后即可在插入、更新和相似性检索时直接传入原始文本,提高业务接入效率。 开启后需配置的参数如下: Embedding 模型:指定使用的 Embedding 模型的名称。您需根据业务的语言类型、数据维度要求等综合选择合适的模型。
取值如下所示: bge-base-zh:适用中文,768 维,推荐使用 m3e-base:适用中文,768 维 e5-large-v2:适用英文,1024 维 text2vec-large-chinese:适用中文,1024 维 multilingual-e5-base:适用于多种语言类型,768 维 原始文本字段:请输入文本字段名称,当前仅支持文本到向量的 Embedding 能力。 写入、更新或者检索数据时,Embedding 模型会自动将该字段的文本内容转换成向量数据。 |
索引 | 索引会占用内存空间,您只需对检索时需要过滤的字段定义索引,向量数据库支持动态 Schema,其余字段可在插入数据时直接写入。 支持三种索引类型,包括主键索引、向量索引、Filter索引。 主键索引:用于快速查找特定行。 向量索引:用于快速查找相似向量。 Filter 索引:是基于用户自定义的标量字段建立的索引,用于在向量检索时根据指定的条件表达式进行过滤查询和范围查询。 |
?
索引参数配置说明如下表所示。
?索引参数名 | 说明 |
字段名 | 主键索引:该参数固定为 id。向量索引:该参数固定为 vector。Filter 索引:单击添加 Filter 索引,可添加一个或多个 Filter 索引,可设置字段名和字段类型。 |
字段类型 | 主键索引:该参数固定为 string。向量索引:该参数固定为 vector。Filter 索引:可选择字段类型。取值如下: string:字符型。 uint64:指无符号整数(unsigned integer)。 array:数组类型,数组元素为 string。 |
向量维度 | 仅向量索引涉及。 若选择开启 Embedding,向量维度为已选 Embedding 模型固定的维度,不可修改。 若选择不开启 Embedding,可自定义向量维度。 取值范围:[1,4096]。 配置建议:维度建议为4的整数倍,字节对齐有助于提升搜索性能。维度越高,存储成本越高,检索效率越低。 |
索引类型 | 主键索引:该参数固定为 primaryKey。向量索引:支持选择 FLAT、HNSW、IVF_FLAT、IVF_PQ、IVF_SQ4、IVF_SQ8、IVF_SQ16。 FLAT:暴力检索,召回率100%,但检索效率低。 HNSW:可通过参数调整召回率,检索效率高,但数据量大后写入效率会变低。 IVF_FLAT、IVF_PQ、IVF_SQ4, IVF_SQ8, IVF_SQ16:IVF 系列索引,适用于上亿规模的数据集,检索效率高,内存占用低,写入效率高。 Filter 索引:该参数固定为 filter。 |
索引参数 | 仅向量索引涉及。 不同索引类型索引参数配置不同。 FLAT:不涉及。 HNSW M:表示每个节点在检索构图中可以连接多少个邻居节点。 默认值16,取值范围[4,64] efConstruction:表示搜索时指定寻找节点邻居遍历的范围。数值越大构图效果越好,构图时间越长。 默认值200,取值范围[8,512] IVF_FLAT、IVF_SQ4、IVF_SQ8、IVF_SQ16 nlist:表示索引中的聚类中心数量。 默认值100,取值范围[1,65536] IVF_PQ nlist:表示索引中的聚类中心数量。 默认值100,取值范围[1,65536] M:表示乘积量化中每个子向量的维度。原始向量会被拆分成多个子向量,每个子向量的维度为 M。 默认等于向量维度,取值范围[1,向量维度],且向量的维度(即向量中元素的个数)必须能够被 M 整除。 |
相似性方法 | 仅向量索引涉及。 指定向量之间距离度量的算法。取值如下: L2:全称是 Euclidean distance,指欧几里得距离,它计算向量之间的直线距离,所得的值越小,越与搜索值相似。L2在低维空间中表现良好,但是在高维空间中,由于维度灾难的影响,L2的效果会逐渐变差。 IP:全称为 Inner Product,是一种计算向量之间相似度的度量算法,它计算两个向量之间的点积(内积),所得值越大越与搜索值相似。 COSINE:余弦相似度(Cosine Similarity)算法,是一种常用的文本相似度计算方法。它通过计算两个向量在多维空间中的夹角余弦值来衡量它们的相似程度,所得值越大越与搜索值相似。 |
3. 在页面下方单击提交。
查看集合详情
1. 在左侧库表栏,鼠标悬停至已创建的集合名称处,在右侧单击

?
2. 在右侧页面查看集合的基本信息和别名管理信息。
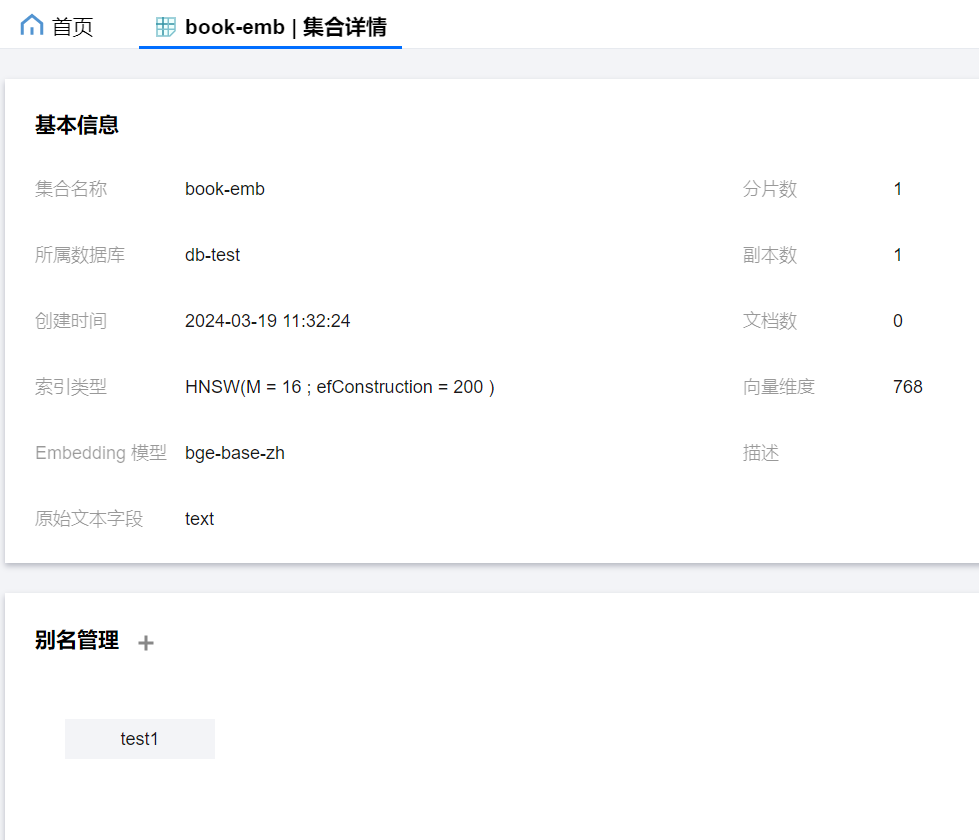
?
集合详情页面还支持以下操作:
新增别名:可在别名管理区域单击
删除别名:鼠标悬停至待删除的别名处,单击
删除集合
说明:
删除后数据无法找回,请谨慎操作。
1. 在左侧库表栏,鼠标悬停至已创建的集合名称处,在右侧单击
2. 在弹出的对话框中,单击确定。
?

