



我们将对单次目标检测器(包括SSD系列和YOLO系列等算法)进行综述。我们将分析FPN以理解多尺度特征图如何提高准确率,特别是小目标的检测,其在单次检测器中的检测效果通常很差。然后我们将分析Focal loss和RetinaNet,看看它们是如何解决训练过程中的类别不平衡问题的。
SSD有哪些创新点
不同于前面的R-CNN系列,SSD属于one-stage方法。SSD使用VGG16网络作为特征提取器(和Faster R-CNN中使用的CNN一样),将后面的全连接层替换成卷积层,并在之后添加自定义卷积层,在最后直接采用卷积进行检测。在多个特征图上设置不同缩放比例和不同宽高比的先验框以融合多尺度特征图进行检测,靠前的大尺度特征图可以捕捉到小物体的信息,而靠后的小尺度特征图能捕捉到大物体的信息,从而提高检测的准确性和定位的准确性。如下图是SSD的网络结构图。

1. 怎样设置default boxes
SSD中default box的概念有点类似于Faster R-CNN中的anchor。不同于Faster R-CNN只在最后一个特征层取Anchor,SSD在多个特征层上取default box,可以得到不同尺度的default box。在特征图的每个单元上取不同宽高比的default box,一般宽高比在{1,2,3,1/2,1/3}中选取,有时还会额外增加一个宽高比为1但具有特征尺度的box。
如下图所示,在8x8的feature map和4x4的feature map上的每个单元取4个不同的default box。原文对于 300x300 的输入,分别在conv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11_2的特征图上的每个单元取4,6,6,6,4,4个default box。由于以上特征图的大小分别是 38x38,19x19,10x10,5x5,3x3,1x1,所以一共得到38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4 = 8732个default box。对一张 300x300的图片输入网络将会针对这8732个default box预测 8732个边界框。
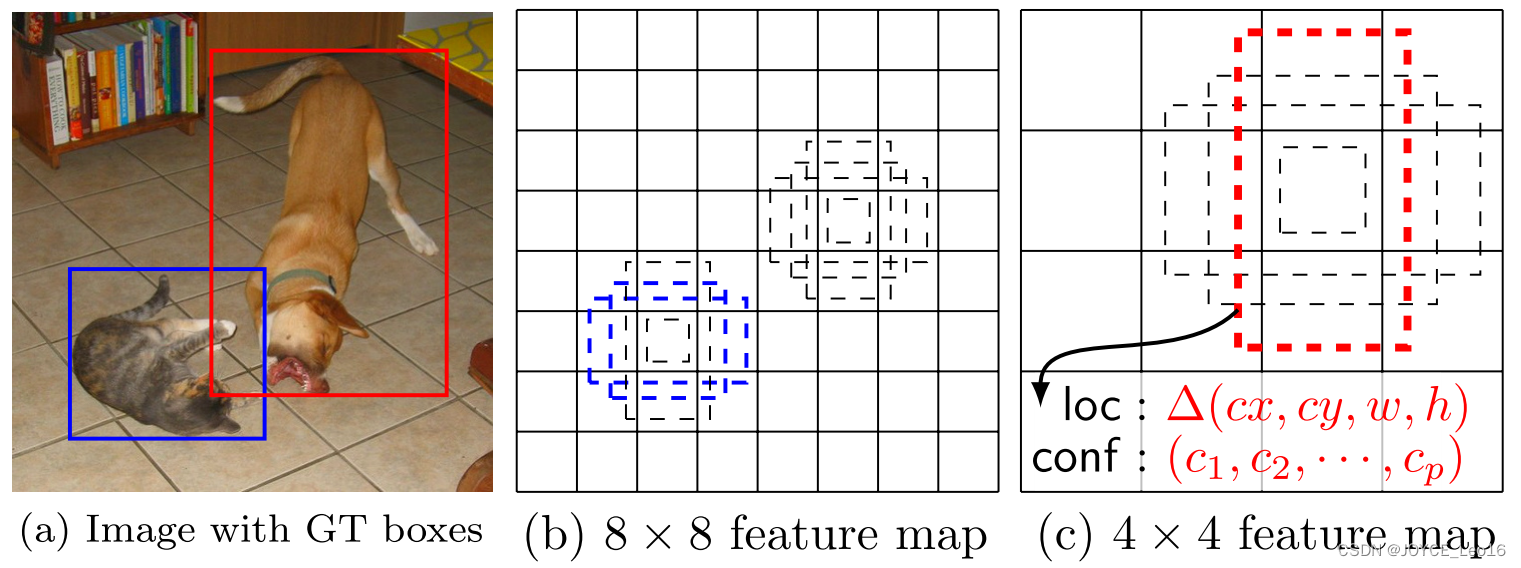
2. 怎样对先验框进行匹配
SSD在训练的时候只需要输入图像和图像中每个目标对应的ground truth。先验框与ground truth的匹配遵循两个原则:
(1)对图片中的每个ground truth,在先验框中找到与其IOU最大的先验框,则该先验框对应的预测边界框与ground truth匹配。
(2)对于(1)中每个剩下的没有与任何ground truth匹配到的先验框,找到与其IOU最大的ground truth,若与其该ground truth的IOU值大于某个阈值(一般设为0.5),则该先验框对应的预测边界框与该ground truth匹配。
按照这两个原则进行匹配,匹配到ground truth的先验框对应的预测边界框作为正样本,没有匹配到ground truth的先验框对应的预测边界框作为负样本。尽管一个ground truth可以与多个先验框匹配,但是ground truth的数量相对先验框还是很少,按照上面的原则进行匹配还是会造成负样本远多于正样本的情况。为了使正负样本尽量均衡(一般保证正负样本比例约为1:3),SSD采用hard negative mining,即对负样本按照其预测背景类的置信度进行降序排列,选取置信度较小的top-k作为训练的负样本。
3. 怎样得到预测的检测结果
最后分别在所选的特征层上使用3x3卷积核预测不同default boxes所属的类别分数及其预测的边界框location。由于对于每个box需要预测该box属于每个类别的置信度(假设有c类,包括背景,例如20class的数据集合,c=21)和该box对应的预测边界框的location(包含4个值,即该box的中心坐标和宽高),则每个box需要预测c+4个值。所以对于某个所选的特征层,该层的卷积核个数为(c+4)x该层的default box个数。最后将每个层得到的卷积结果进行拼接。
对于得到的每个预测框,取其类别置信度的最大值,若该最大值大于置信度阈值,则最大值所对应的类别即为该预测框的类别,否则过滤掉此框。对于保留的预测框,根据它对应的先验框进行解码得到其真实的位置参数(这里还需要注意防止预测框位置超出图片),然后根据所属类别置信度进行降序排列,取top-k个预测框,最后进行NMS,过滤掉重叠度较大的预测框,最后得到检测结果。
SSD优势是速度比较快,整个过程只需要一步,首先在图片不同位置按照不同尺度核宽高比进行密集抽样,然后利用CNN提取特征后直接进行分类与回归,所以速度比较快,但均匀密集采样会造成正负样本不均衡的情况使得训练比较困难,导致模型准确度有所降低。另外,SSD对小目标的检测没有大目标好,因为随着网络的加深,在高层特征图中小目标的信息丢失掉了,适当增大输入图片的尺寸可以提升小目标的检测效果。
DSSD有哪些创新点
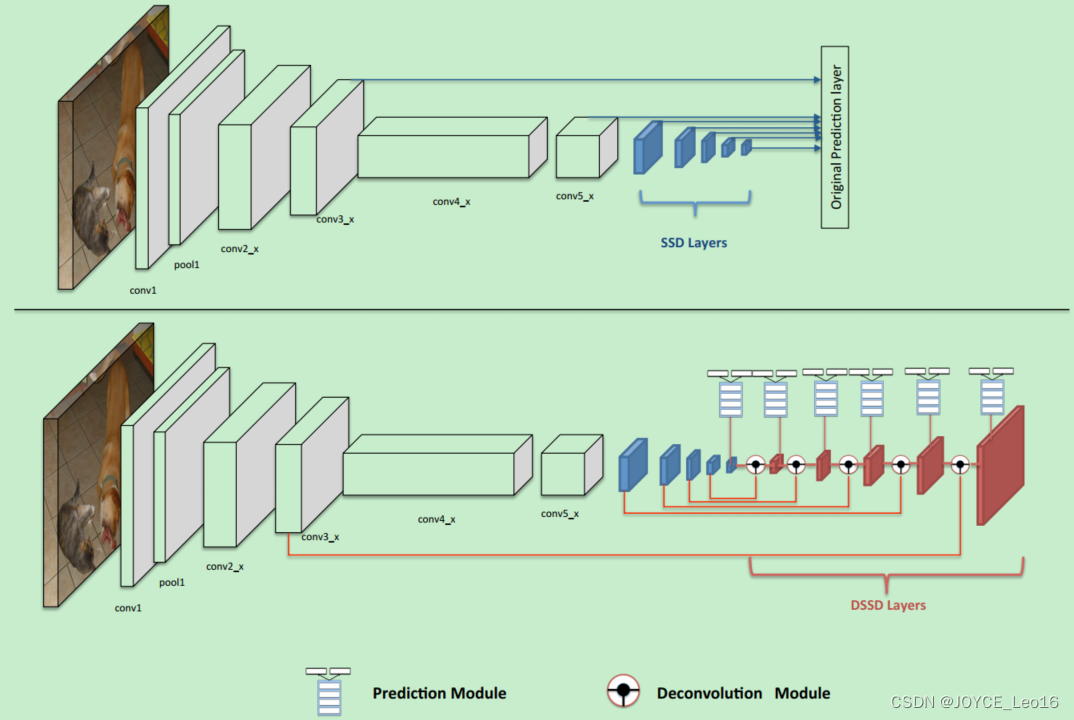
为了解决SSD算法检测小目标困难的问题,DSSD算法将SSD算法基础网络从VGG-16更改为ResNet-101,增强网络特征提取能力,其次参考FPN算法思路利用去Deconvolution结构将图像深层特征从高维空间传递出来,与浅层信息融合,联系不同层级之间的图像语义关系,设计预测模块结构,通过不同层级特征之间融合特征输出预测物体类别信息。
DSSD算法中有两个特殊结构:Prediction模块;Deconvolution模块。前者利用提升每个子任务的表现来提高准确性,并且防止梯度直接流入ResNet主网络。后者则增加了三个Batch Normalization层和三个 3x3 卷积层,其中卷积层起到了缓冲的作用,防止梯度对主网络影响太剧烈,保证网络的稳定性。
SSD和DSSD的网络模型如下图所示:
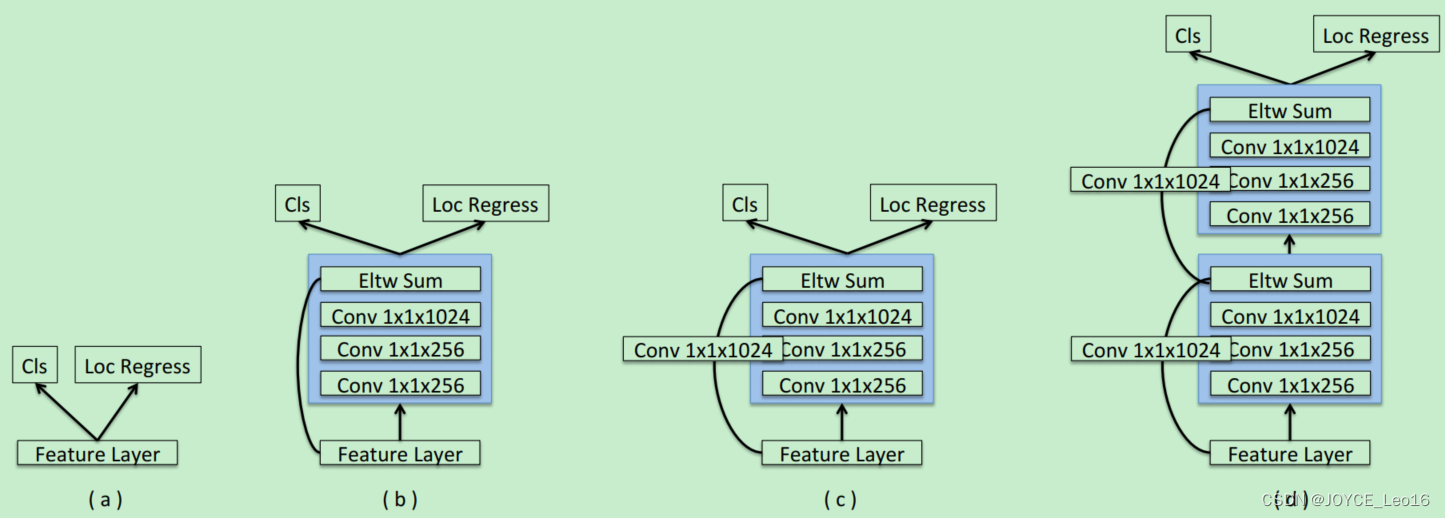
Prediction Module
SSD直接从多个卷积层中单独要引出预测函数,预测量多达7000多,梯度计算量也很大。MS-CNN方法指出,改进每个子任务的子网可以提高准确性。根据这一思想,DSSD在每一个预测层后增加残差模块,并且对于多种方案进行了对比,如下图所示。结果表明,增加残差预测模块后,高分辨率图片的检测精度比原始SSD提升明显。
Deconvolution 模块
为了整合浅层特征图和deconvolution层的信息,作者引入deconvolution模块,如下图所示。作者受到论文Learning to Refine Object Segments的启发,认为用于精细网络的deconvolution模块的分解结构达到的精度可以和复杂网络一样,并且更有效率。
作者对其进行了一定的修改:其一,在每个卷积层后添加批归一化(batch normalization)层;其二,使用基于学习的deconvolution层而不是简单地双线性上采样;其三,作者测试了不同的结合方式,元素求和(element-wise sum)与元素点积(element-wise product)方式,实验证明元素点积计算能得到更好的精度。

YOLOv1有哪些创新点
YOLOv1介绍
YOLO(You Only Look Once:Unified,Real-Time Object Detection)是one-stage detection的开山之作。之前的物体检测方法首先需要产生大量可能包含待检测物体的先验框,然后用分类器判断每个先验框对应的边界框是否包含待检测物体,以及物体所属类别的概率或者置信度,同时需要后处理修正边界框,最后基于一些准则过滤掉置信度不高和重叠度较高的边界框,进而得到检测结果。这种基于先产生候选区再检测的方法虽然有相对较高的检测准确率,但运行速度较慢。
YOLO创造性的将物体检测任务直接当作回归问题(regression problem)来处理,将候选区和检测两个阶段合二为一。只需一眼就能知道每张图像中有哪些物体以及物体的位置。下图展示了各物体检测系统的流程图。

事实上,YOLO也并没有真正的去掉候选区,而是直接将输入图片划分为 7x7=49 个网格,每个网格预测两个边界框,一共预测 49x2=98 个边界框。可以近似理解为在输入图片上粗略的选取98个候选区,这98个候选区覆盖了图片的整个区域,进而用回归预测这98个候选框对应的边界框。
1. 网络结构是怎样的
YOLO网络借鉴了GoogLeNet分类网络结构,不同的是YOLO使用 1x1 卷积层和 3x3 卷积层替代inception module。如下图所示,整个检测网络包括24个卷积层和2个全连接层。其中,卷积层用来提取图像特征,全连接层用来预测图像位置和类别概率值。

2、YOLO的输入、输出、损失函数分别是什么
前面说到YOLO将输入图像分成 7x7 的网格,最后输出的是 7x7xk 的张量。YOLO网络最后接了两个全连接层。全连接层要求输入是固定大小的,所以YOLO要求输入图像有固定大小,论文中作者设计的输入尺寸是 448x448。
YOLO将输入图像分成 7x7 的网格,每个网格预测2个边界框。若某物体的ground truth的中心落在该网格,则该网格中与这个ground truth IOU最大的边界框负责预测该物体。对每个边界框会预测5个值,分别是边界框的中心x,y(相对于所属网格的边界),边界框的宽高w, h(相对于原始输入图像的宽高的比例),以及这些边界框的confidence scores(边界框与ground truth box的IOU值)。同时每个网格还需要预测 c 个类条件概率(是一个c维向量,表示某个物体 object 在这个网格中,且该object分别属于各个类别的概率,这里的c类物体不包含背景)。
论文中的c=20,则每个网格需要预测 2x5+20=30 个值,这些值被映射到一个30维的向量。为了让边界框坐标损失、分类损失达到很好的平衡,损失函数设计如下图所示。
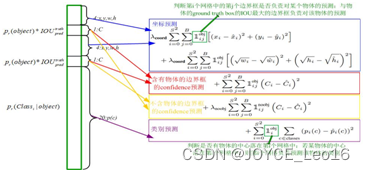
如上图所示,损失函数分为坐标预测(蓝色框)、含有物体的边界框的confidence预测(红色框)、不含有物体的边界框的confidence预测(黄色框)、分类预测(紫色框)四个部分。
由于不同大小的边界框对预测偏差的敏感度不同,小的边界框对预测偏差的敏感度更大。为了均衡不同尺寸边界框对预测偏差的敏感度的差异。作者巧妙的对边界框的 w,h 取均值再求 L2 loss。YOLO中更重视坐标预测,赋予坐标损失更大的权重,记为coord,在pascal voc训练中 coodd=5,classification error部分的权重取1。
某边界框的置信度定义为:某边界框的confidence = 该边界框存在某类对象的概率pr(object) * 该边界框与该对象的 ground truth 的IOU值,若该边界框存在某个对象pr(object)=1,否则pr(object)=0。由于一幅图中大部分网络中是没有物体的,这些网格中的边界框的confidence置为0,相比于有物体的网络,这些不包含物体的网格更多,对梯度更新的贡献更大,会导致网络不稳定。为了平衡上述问题,YOLO损失函数中对没有物体的边界框的confidence error 赋予较小的权重,记为 noobj,对有物体的边界框的 confidence error赋予较大的权重。在pascal VOC训练中 noobj=0.5,有物体的边界框的confidence error的权重设为1。
3. YOLO怎样预测
YOLO最后采用非极大值抑制(NMS)算法从输出结果中提取最有可能的对象和其对应的边界框。
输入一张图片到YOLO网络将输出一个7730的张量表示图片中每个网格对应的可能的两个边界框以及每个边界框的置信度和包含的对象属于各个类别的概率。由此可以计算某对象 i 属于类别同时在第 j 个边界框中的得分:
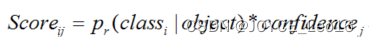
每个网格有20个类条件概率,2个边界框置信度,相当于每个网格有40个得分,7x7个网格有1960个得分,每类对象有 1960/20=98个得分,即98个候选框。
NMS步骤如下:
1. 设置一个Score的阈值,一个IOU的阈值;
2. 对于每类对象,遍历属于该类的所有候选框。
① 过滤掉Score低于Score阈值的候选框;
② 找到剩下的候选框中最大的Score对应的候选框,添加到输出列表;
③ 找到剩下的候选框与②中输出列表中每个候选框的IOU,若该IOU大于设置的IOU阈值,将该候选框过滤掉,否则加入输出列表中;
④ 最后输出列表中的候选框即为图片中该类对象预测的所有边界框。
3. 返回步骤2继续处理下一类对象。
YOLO将识别与定位合二为一,结构简便,检测速度快,更快的Fast YOLO可以达到155FPS。相对于R-CNN系列,YOLO的整个流程中都能看到整张图像的信息,因此它在检测物体时能很好的利用上下文信息,从而不容易在背景上预测出错误的物体信息。同时YOLO可以学习到高度泛化的特征,能将一个域上学到的特征迁移到不同但相关的域上,如在自然图像上训练的YOLO,在艺术图片上可以得到较好的测试结果。
由于YOLO网格设置的比较稀疏,且每个网格只预测2个边界框,其总体预测精度不高,略低于Fast R-CNN。其对小物体的检测效果较差,尤其是对密集的小物体表现比较差。

