Hi,我是Johngo~
今天看到一个帖子,分享给大家~

不读(博)的人永远不知道这个过程的酸涩苦辣,也只有读过的人才能共情它的价值和营养。 科研可以不做,博士尽量还是要读。从挺直腰杆子的底气到社会信任的基石。 不多几年修行,怎么经风踏浪,怎么破除所谓的“钝感力(其实是不上心)”,怎么有效应对所谓的“精神内耗(其实是听不得别人建议的心底抗拒)”,怎么摩掉新式的“情绪价值(奈何只是彩虹屁的大量诉求)”...... 年轻人无数次的自省与自我独白,才能真的脱掉纸尿裤”,换上耐受的“千层底”呀,才能从你张嘴只会夸夸拍马屁变成气自华、言有力的腹有诗书呀~
我觉得,任何事情,不经历整个过程,就无法理解每件事的价值和意义。无论是读博士、还是硕士、本科等等。不仅是学术学业上的修行,更是一种社会认可和信任的基础。
通过读书,大家可以培养自我自信和承担责任的能力,同时也能够更好地面对困难和挑战,提高自己的心理素质。
总之,走在人生路上,最重要的就是:不畏艰难,砥砺前行,多进行自我反省,这是成长的关键,只有经过反复思考和磨砺,才能摆脱幼稚和浮躁,变得更加成熟和有深度。
最近很多同学反映,论文太让人头疼了,每天吃饭睡觉都是在一个不知名的状态中,寻找那一点思路。
坚持就好,不怕走的慢,时间能够证明一切。
该论文提出了一种名为Transformer的新型神经网络架构,用于解决序列到序列(sequence-to-sequence)的任务,如机器翻译、文本摘要等。传统的序列模型如循环神经网络(Recurrent Neural Networks, RNNs)和卷积神经网络(Convolutional Neural Networks, CNNs)在处理长序列时面临着记忆问题和并行计算效率低下的困扰。而Transformer则采用了完全不使用循环和卷积的机制,仅依赖于自注意力机制(self-attention)来建模序列之间的关联。
Transformer具有以下几个方面的优势:

该论文提出了一种扩展Transformer模型的方法,用于解决传统Transformer模型在长距离依赖建模上的局限性。传统Transformer模型在处理长句子时,由于自注意力机制的影响,会出现信息的丢失和模糊。为了解决这个问题,论文提出了一种可扩展的Transformer模型。
论文的主要贡献包括:

在Fnet中,作者提出了一种新颖的注意力机制,称为"Soft Position Embedding"。该机制旨在解决自注意力机制中存在的一些问题,例如对序列长度的敏感性以及计算复杂度的增加。此外,Fnet还引入了一种新颖的位置编码方案,以更好地捕捉序列中的位置信息。
主要贡献:

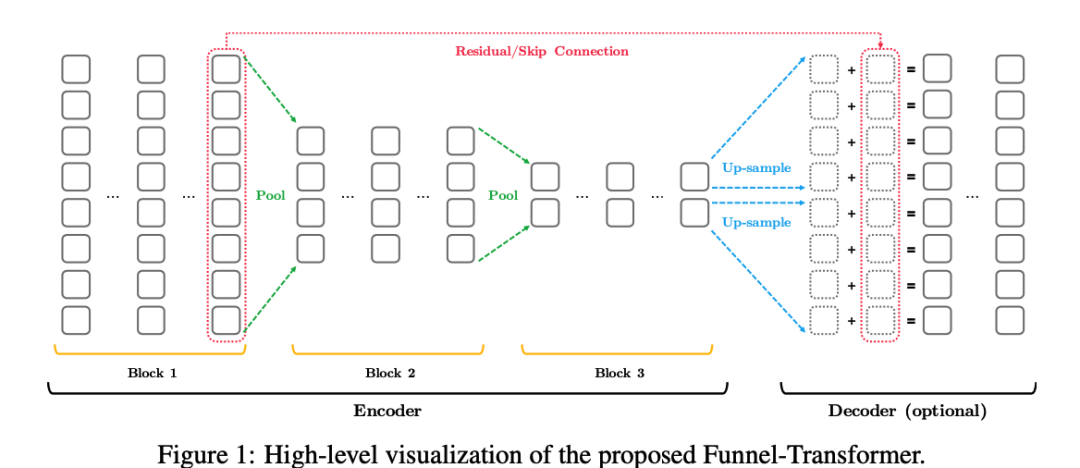
Funnel-Transformer 旨在解决传统 Transformer 模型在处理长文本时的效率问题。传统 Transformer 模型在处理长序列时需要消耗大量的计算资源,并且容易受到序列长度的限制。Funnel-Transformer 提出了一种新的结构,通过引入分层结构和跨层信息传递的方式来减少冗余计算,提高长序列处理效率。
主要贡献:
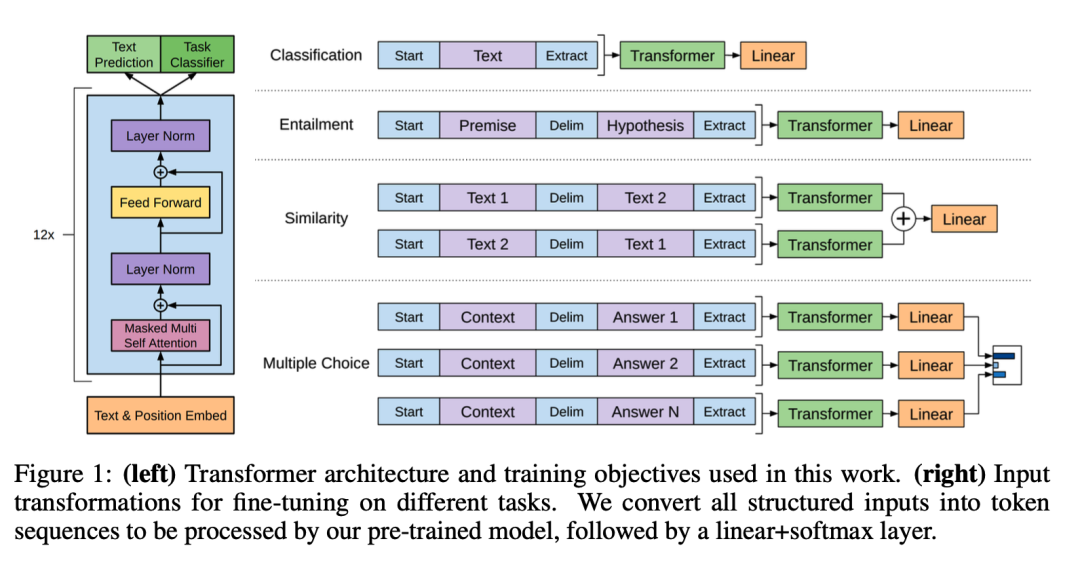
GPT是一种基于Transformer架构的预训练语言模型,其核心思想是通过大规模的无监督学习来学习语言表示,并将这些表示应用于各种下游自然语言处理(NLP)任务中。GPT采用了Transformer的编码器架构,其中包括多头自注意力机制和位置编码,以便有效地建模长距离依赖关系。
论文的主要贡献包括: