本文方法主要针对ctr预估中的用户行为建模提出相应的模型,用户交互历史包含了不同的行为模式,反映用户的习惯性范式。本文所提方法利用用户行为模式,将目标注意力(TA)机制扩展到目标模式注意力(TPA)机制,以对行为模式之间的依赖关系进行建模。
本文引入了深度模式网络(DPN),利用用户行为模式的信息。DPN使用目标感知注意力机制检索与目标商品相关的用户行为模式。同时,通过基于自监督学习的预训练范式来细化用户行为模式,同时促进稀疏模式中的依赖性学习。

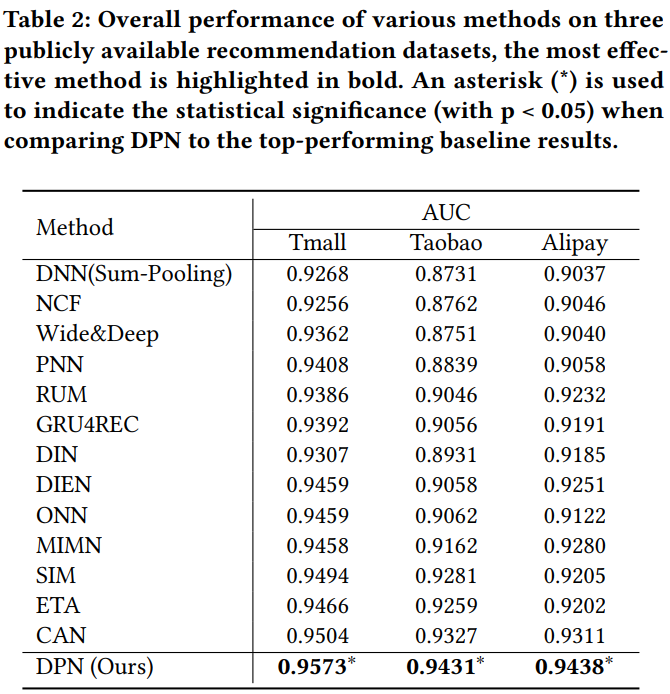
alt text
embedding层用于提取用户特征emb和行为emb,行为序列中包含了历史交互的item id和item的类型,得到两者的emb后进行拼接得到
,表示第k个行为的emb,则行为序列emb表示为
。
采用DIN作为用户兴趣提取的骨干网络,使用目标注意力机制来捕捉用户对目标商品
的兴趣表征
,表示如下,其中a()是attention函数(和DIN中一样这里不赘述),
是目标商品的emb和序列emb一样也是拼接了item id和类型的emb。
TPRM搜索用户相对于目标商品和类别的行为模式,前面计算出了不同历史交互和目标商品attn分数,现在根据这些分数检索出topN个最相关的,表示如下:
然后定义交互模式,所谓交互交互模式
,就是对于前面取出的topK个行为,以第k个为例,其对应的索引是
,则交互模式表示为当前索引和其之前的
次交互组成的行为序列,表示为

用户行为模式并不总是连续的,一些不相关的商品可能会被其他兴趣所误导或驱动。例如,如果用户依次与iPhone、T恤和Airpods交互,那么只有从iPhone到Airpods的过渡才是有意义的模式。本节提出了一个自监督模式细化网络,从检索到的原始用户行为模式中提取真实的用户行为模式,如图4所示。首先,通过自监督去噪任务对细化网络进行预训练。然后DPN应用预训练的细化网络来细化检索到的模式。
将一个用户行为模式,作为原始输入
。 然后,在序列中随机混合一些其他的交互,得到
。增广的行为模式序列的最后一个记录和原始行为模式序列应该一样,这向细化网络指示了行为模式的决策目标是什么。
使用两层Transformer来编码,从增广的序列中提取行为模式表征。表达如下,
因此,经过M层后得到表示向量
,文中是2。然后,通过mlp来预测
,本来是
维度的tensor,经过mlp之后得到
,在使用的时候(图4右边部分),选取top-s个logit对应的行为,相当于就是把低logit的去噪了。
这部分自监督训练采用交叉熵损失,表示为下式,
用户行为模式反映了用户隐含的心理决策范式。对历史行为模式和当前目标行为模式之间的依赖性进行建模,可以有效地帮助模型确定对目标商品和类别的点击是否符合用户的习惯范式,从而提高模型的推荐性能。
因此,可以将target attention扩展到target pattern attention,进行模式间依赖建模。通过前面的细化网络,我们可以得到和目标item相关的第k个行为模式序列的表征为
, 然后和目标item对应的模式做target attention。这里的目标模式
,笔者理解
要计算的候选item,然后前面的是距离当前最近的几次交互,一起构成目标模式行为序列。
预测点击和不点击的概率,如下是,然后构建交叉熵损失函数