


Logstash 是一个开源的日志处理工具,可以从多个源头收集数据、过滤收集的数据并对数据进行存储作为其他用途。
Logstash 灵活性强,拥有强大的语法分析功能,插件丰富,支持多种输入和输出源。Logstash 作为水平可伸缩的数据管道,与 Elasticsearch 和 Kibana 配合,在日志收集检索方面功能强大。
Logstash 工作原理
Logstash 数据处理可以分为三个阶段:inputs → filters → outputs。
1. inputs:产生数据来源,例如文件、syslog、redis 和 beats 此类来源。
2. filters:修改过滤数据, 在 Logstash 数据管道中属于中间环节,可以根据条件去对事件进行更改。一些常见的过滤器包括:grok、mutate、drop 和 clone 等。
3. outputs:将数据传输到其他地方,一个事件可以传输到多个 outputs,当传输完成后这个事件就结束。Elasticsearch 就是最常见的 outputs。
同时 Logstash 支持编码解码,可以在 inputs 和 outputs 端指定格式。
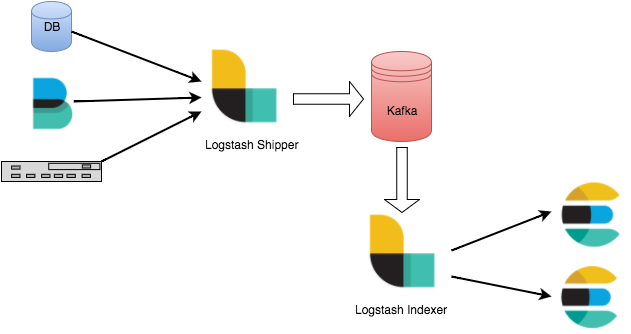
Logstash 接入 Kafka 的优势
可以异步处理数据:防止突发流量。
解耦:当 Elasticsearch 异常的时候不会影响上游工作。
注意
Logstash 过滤消耗资源,如果部署在生产 server 上会影响其性能。
?
操作步骤
准备工作
下载并安装 Logstash,参见 Download Logstash。
下载并安装 JDK 8,参见 Download JDK 8。
已 创建 CKafka 实例。
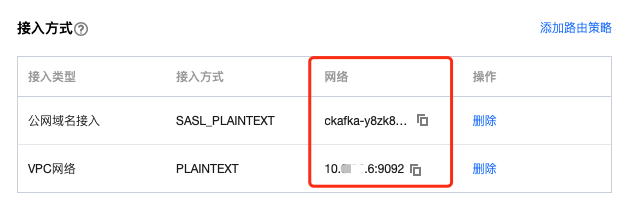
步骤1:获取 CKafka 实例接入地址
1. 登录 CKafka 控制台。
2. 在左侧导航栏选择实例列表,单击实例的“ID”,进入实例基本信息页面。
3. 在实例的基本信息页面的接入方式模块,可获取实例的接入地址。
步骤2:创建 Topic
1. 在实例基本信息页面,选择顶部Topic管理页签。
2. 在 Topic 管理页面,单击新建,创建一个名为 logstash_test 的 Topic。

步骤3:接入 CKafka
说明
您可以单击以下页签,查看 CKafka 作为 inputs 或者 outputs 接入的具体步骤。
1. 执行 
bin/logstash-plugin list,查看已经支持的插件是否含有 logstash-input-kafka。
2. 在 .bin/ 目录下编写配置文件 input.conf。
此处将标准输出作为数据终点,将 Kafka 作为数据来源。
input {kafka {bootstrap_servers => "xx.xx.xx.xx:xxxx" // ckafka 实例接入地址group_id => "logstash_group" // ckafka groupid 名称topics => ["logstash_test"] // ckafka topic 名称consumer_threads => 3 // 消费线程数,一般与 ckafka 分区数一致auto_offset_reset => "earliest"}}output {stdout{codec=>rubydebug}}
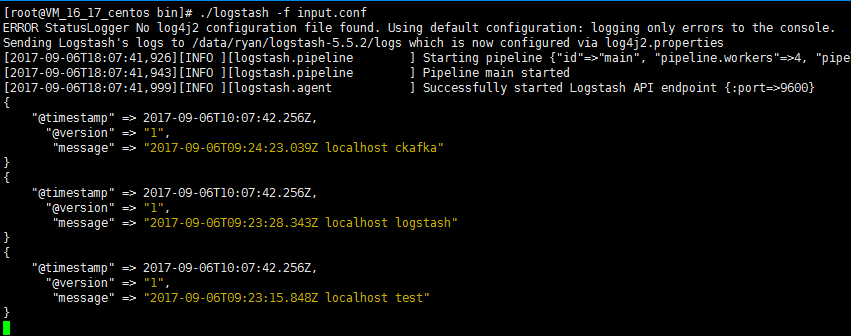
3. 执行以下命令启动 Logstash,进行消息消费。
./logstash -f input.conf
返回结果如下:
1. 执行 
bin/logstash-plugin list,查看已经支持的插件是否含有 logstash-output-kafka。
2. 在.bin/目录下编写配置文件 output.conf。此处将标准输入作为数据来源,将 Kafka 作为数据目的地。
input {stdin{}}output {kafka {bootstrap_servers => "xx.xx.xx.xx:xxxx" // ckafka 实例接入地址topic_id => "logstash_test" // ckafka topic 名称}}
3. 执行如下命令启动 Logstash,向创建的 Topic 发送消息。
./logstash -f output.conf
?
4. 启动 CKafka 消费者,检验上一步的生产数据。

?

