


Apache Druid 是一个分布式的、支持实时多维 OLAP 分析的数据处理系统,用于解决如何在大规模数据集下进行快速的、交互式的查询和分析的问题。
基本特点
Apache Druid 具有以下特点:
亚秒响应的交互式查询,支持较高;包括多维过滤、Ad-hoc 的属性分组、快速聚合数据等。
支持高并发、实时数据摄入,真正做到数据摄入实时、查询结果实时。
扩展性强,采用分布式 shared-nothing 的架构,支持 PB 级数据、千亿级事件快速处理,支持每秒数千查询并发。
支持多租户同时在线查询。
支持高可用,且支持滚动升级。
应用场景
Druid 最常用的场景就是大数据背景下、灵活快速的多维 OLAP 分析。另外,Druid 还有一个关键的特点,它支持根据时间戳对数据进行预聚合摄入和聚合分析。因此也有用户经常在有时序数据处理分析的场景中用到它,例如广告平台、实时指标监控、推荐模型、搜索模型。
体系架构
Druid 是一个基于微服务的架构。Druid 中的每个核心服务均可以单独或联合部署在不同硬件上。
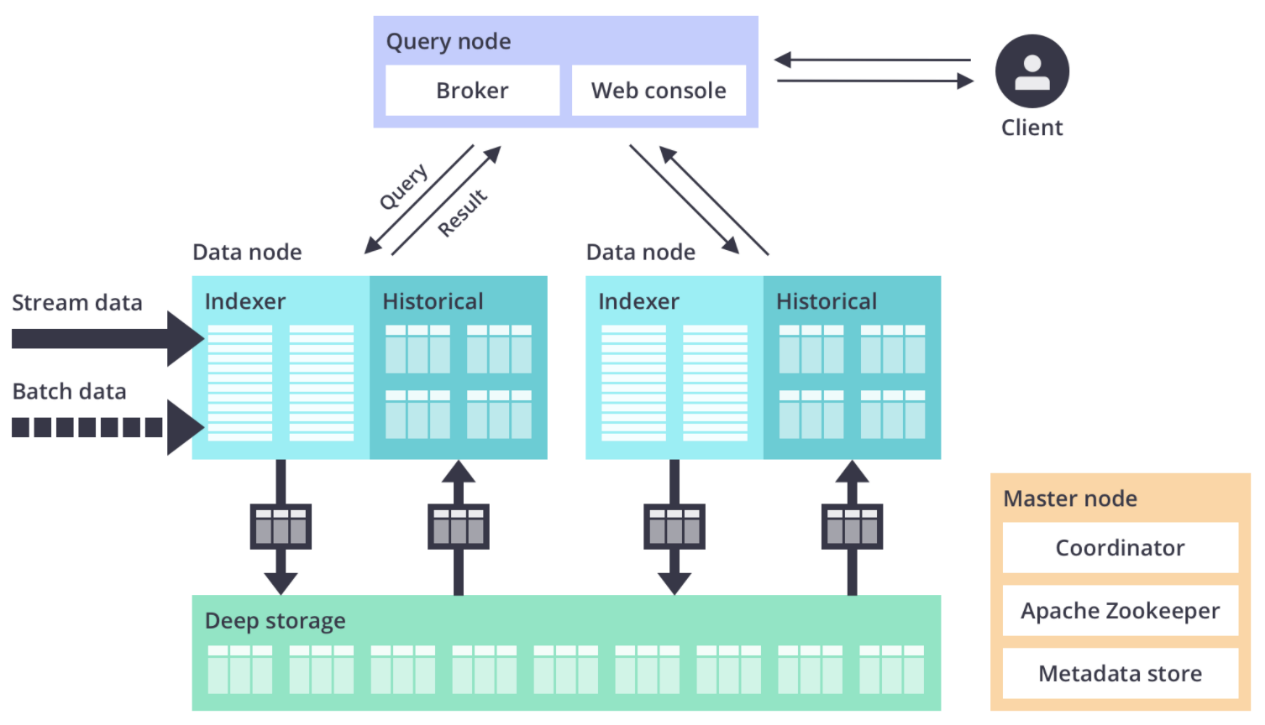
EMR 增强型 Druid
EMR Druid 基于 Apache Druid 做了大量的改进,包括与 EMR Hadoop 和云周边生态的集成、方便的监控与运维支持、易用的产品接口等,做到了即买即用和免运维。
EMR Druid 目前支持的特性如下所示:
方便和 EMR Hadoop 集群结合
方便快速弹性扩缩容
支持 HA
支持将 COS 作为 deep storage
支持将 COS 文件作为批量索引的数据源
支持将元数据存储到 TencentDB
集成了 Superset 等工具
丰富的监控指标和告警规则
故障迁移
高安全性

