


≈≈–ρΕ®÷Τ‘ –μ”ΟΜßΉ‘Ε®“εΥ―ΥςΫαΙϊ≈≈–ρΖΫ ΫΘ§Ά®Ιΐ…η÷Ο≥θ≈≈Ή÷ΕΈΚΆΨΪœΗ≈≈–ρ±μ¥ο ΫΘ§Η…‘ΛΉν÷’’Ι ΨΫαΙϊΒΡ≈≈–ρΓΘ
≥θΦΕ≈≈–ρΕ®÷Τ
- –ßΙϊΘΚ ≈δ÷ΟΗΟΉ÷ΕΈΘ§Φ¥Ω…‘Ύ”ΟΜßΦλΥς«ΑΘ§‘Λœ»Α― ΐΨίΑ¥’’ΗΟΉ÷ΕΈ÷ΒΒΡ”≈Ν”Ϋχ––≈≈–ρΓΘ“ρ¥Υ«κ―Γ‘ώΉνΡή¥ζ±μ“ΜΧθ ΐΨί”≈Ν”ΒΡ ΐ÷ΒΉ÷ΕΈΓΘ
- Ής”ΟΘΚ“ρΈΣ”ΟΜßΥ―Υς ±Θ§Ε‘Υ―ΥςΫαΙϊΫχ––ΒΙ≈≈Υς“ΐΚΆ«σΫΜ“‘ΦΑœύΙΊ–‘ΦΤΥψ «“ΜΗω±»ΫœΚΡ ±ΒΡΙΐ≥ΧΘ§ΧΊ±π «”ωΒΫ ΐΨίΙφΡΘΚήΨό¥σΒΡ“ΒΈώΓΘ≈δ÷ΟΗΟΉ÷ΕΈΚσΘ§Ω…“‘±Θ÷Λ‘Ύ“ΜΕ®ΒΡ ±ΦδΡΎΘ§ΨΓΝΩ’ΌΜΊ”≈÷ ΒΡΈΡΒΒ’Ιœ÷Ηχ”ΟΜßΓΘ
- œό÷ΤΘΚ≥θ≈≈Ή÷ΕΈ÷ΜΡή…η÷ΟΈΣ ΐ÷Βάύ–ΆΒΡΉ÷ΕΈΘ§≤Μ÷ß≥÷ΤδΥϊάύ–ΆΒΡΉ÷ΕΈΓΘ
- ≈δ÷ΟΙΐ≥ΧΘΚ«κΑ¥’’œ¬ΆΦΫχ––≈δ÷ΟΘΚ
ΓΨ≥θ≈≈Ή÷ΕΈΓΩΩ…―Γ‘ώ“ΜΗωΡή¥ζ±μΈΡΒΒ÷ ΝΩΒΡ ΐ÷ΒΉ÷ΕΈΘ§”Ο”Ύ≥θ≈≈Θ§»ΜΚσΒΞΜςΓΨΧαΫΜΓΩΘ§œΒΆ≥ΜαΧα Ψ÷ΊΫ®Υς“ΐΓΘ»τ–η“ΣΙΊ±’≥θ≈≈Θ§Ω…÷±Ϋ”―Γ‘ώΓΨΙΊ±’ΓΩΓΘ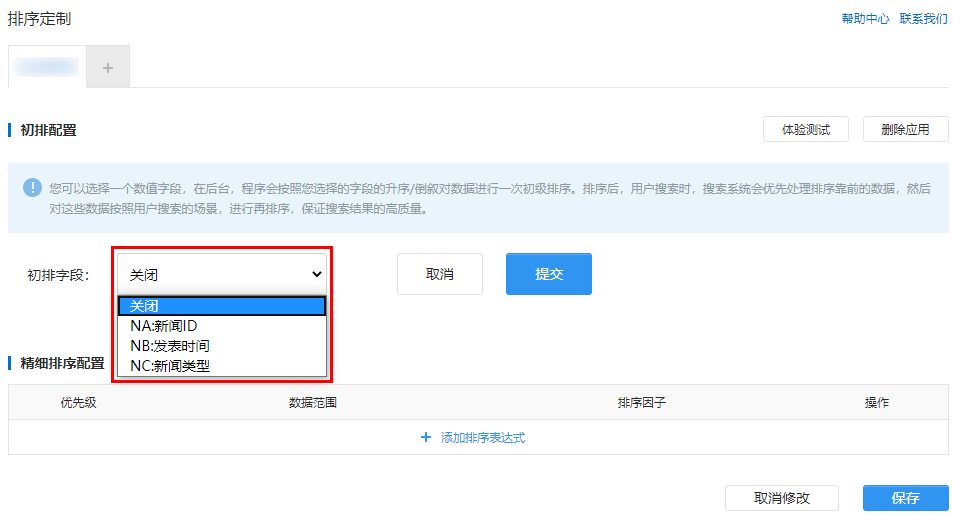
Υς“ΐ÷ΊΫ®Άξ≥…ΚσΘ§≥θΦΕ≈≈–ρΝΔΦ¥…ζ–ßΓΘ ΥΒΟςΘΚ
ΥΒΟςΘΚ»γΙϊΡζ”–ΕύΗω≈δ÷Ο“Σ–όΗΡΘ§Ϋ®“ι―Γ‘ώ…‘Κσ÷ΊΫ®Θ§Β»»Ϊ≤Ω–όΗΡΆξ≥…ΚσΘ§‘Ό ÷Ε·‘ΎΓΑ ΐΨί¥ΠάμΓ±¥ΠΒΞΜς÷ΊΫ®Υς“ΐΘ§ΫΎ‘ΦΖ―”ΟΓΘ
ΨΪœΗ≈≈–ρΕ®÷Τ
ΨΪœΗ≈≈–ρ «÷±Ϋ””ΑœλΈΡΒΒ’Ι ΨΥ≥–ρΒΡΉνΚσ“ΜΦΕ≈≈–ρΘ§‘ –μΩΣΖΔ’ΏΉ‘÷ςΕ‘Υ―ΥςΫαΙϊΫχ––ΗϋΗω–‘Μ·’ϊΚœΚΆΜλΚœ≈≈–ρΓΘΒ±«Α÷ς“ΣΩΦ¬«ΝΥΦΗΗωΈ§Ε»ΒΡΜλ≈≈“ρΉ”Θ§άΐ»γΘ§Ψύάκ“ρΉ”ΓΔΨΪ»ΖΤΞ≈δ“ρΉ”ΓΔ≥« –“ρΉ”ΓΔœύΙΊ–‘“ρΉ”ΓΔ»®ΆΰΕ»“ρΉ”“‘ΦΑΗς ΐ÷Β”ρΉ÷ΕΈ“ρΉ”ΓΘ
ΨΪœΗ≈≈–ρ «ΕΰΈ§≈≈–ρΖΫ ΫΘ§ Ήœ»ΗυΨί“ΒΈώ«ιΩωΑ―ΈΡΒΒΫγΕ®≥ωΦΗΗωΒΒΈΜΘ®Φ¥”≈œ»ΦΕΘ§»γœ¬ΆΦ”≈œ»ΦΕ1ΓΔ2ΓΔ3Θ©Θ§”≈œ»ΦΕΗΏΒΡ ΐΨί’ϊΧε≈≈‘Ύ”≈œ»ΦΕΒΆΒΡ ΐΨί«ΑΟφΘ§“‘¥ΥάύΆΤΓΘ
ΟΩΗω”≈œ»ΦΕΕΦΕ‘”Π“ΜΗω ΐΨίΖΕΈß±μ¥ο ΫΘ§ΗΟ±μ¥ο ΫΉν÷’ΫαΙϊΈΣ“ΜΗω bool άύ–ΆΒΡ÷ΒΘ§ΦΤΥψΫαΙϊΈΣ true Μρ’Ώ > 0ΒΡΫαΙϊΒΡΥυ”–ΈΡΒΒΕΦ τ”ΎΗΟ”≈œ»ΦΕΓΘ
‘ΎΆ§“ΜΗω”≈œ»ΦΕΖΕΈßΡΎΘ§Ά®Ιΐ÷ΗΕ®≈≈–ρ“ρΉ”Θ®Ω…“‘”–ΕύΗω“ρΉ”Θ§”Οœ¬Μ°œΏ_ΗτΩΣΘ©ΒΡΖΫ ΫΘ§ΨωΕ®ΡΎ≤ΩΒΡ≈≈–ρΓΘ≈≈–ρΖΫ ΫΈΣœ»Α¥’’ΒΎ“ΜΗω“ρΉ”¥σ–Γ≈≈–ρΘ§«Α“ΜΗω“ρΉ”œύΒ»ΒΡ«ιΩωœ¬Θ§‘ΌΆ®ΙΐΚσ“ΜΗω“ρΉ”Ϋχ––≈≈–ρΘ§“‘¥ΥάύΆΤΘ§Ρ§»œ «Α¥’’ΫΒ–ρ≈≈–ρΘ§»γΙϊ“ΣΑ¥’’…ΐ–ρ≈≈–ρΘ§‘ρ÷±Ϋ”‘Ύ“ρΉ”«ΑΦ”“ΜΗωΦθΚ≈ΓΘ
άΐ»γΘΚ
- Ήν”≈ΈΡΒΒΈΣ”≈œ»ΦΕ1ΒΡΈΡΒΒΘ§Έ“»œΈΣΖϊΚœΨΪ»ΖΤΞ≈δΫαΙϊΒΡΈΡΒΒΈΣΉν”≈÷ ΒΡΈΡΒΒΘ§‘ρΗΟ”≈œ»ΦΕΕ‘”ΠΒΡ ΐΨίΖΕΈß±μ¥ο ΫΈΣ exactmatch > 0Θ§Υυ”–ΖϊΚœΗΟΧθΦΰΒΡΈΡΒΒΕΦ“ΜΕ®Μα”≈œ»”Ύ≤ΜΖϊΚœΗΟΧθΦΰΒΡΤδΥϊΈΡΒΒΘ§’β «“ΜΗωΈ§Ε»ΒΡ≈≈–ρΓΘ
- Ε‘”Ύ“‘…œΖϊΚœΨΪ»ΖΤΞ≈δΫαΙϊΒΡΈΡΒΒΘ§÷ΗΕ®Α¥’’»®ΆΰΕ»”≈œ»Θ§‘ΌΑ¥’’Ψύάκ”≈œ»Ϋχ––≈≈–ρΘ§‘ρ≈≈–ρ“ρΉ”ΈΣΘΚ
- ΓΨ”≈œ»ΦΕΓΩ”≈œ»ΦΕ‘ΫΩΩ«ΑΘ§ ΐΨί‘Ϋ”≈÷ Θ§≈≈–ρ‘ΫΩΩ«Α
- ΓΨ ΐΨίΖΕΈßΓΩ±ύΦ≠±μ¥ο Ϋ»Π≥ω τ”ΎΗΟ”≈œ»ΦΕΒΡ ΐΨί
- ΓΨ≈≈–ρ“ρΉ”ΓΩΕ‘”ΎΆ§“Μ”≈œ»ΦΕ ΐΨίΘ§÷ΗΕ®≈≈–ρ“ρΉ”
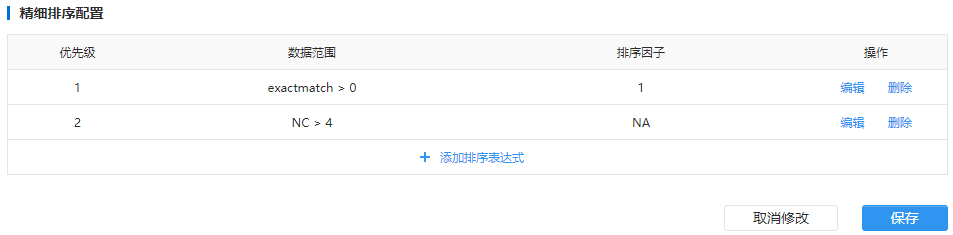
≈≈–ρ‘ΥΥψ±μ
ΐΨίΖΕΈßΚΆ≈≈–ρ“ρΉ”÷ß≥÷“‘œ¬ΥΡ‘ρ‘ΥΥψΙφ‘ρΘΚ
| Ζ÷άύ | Ή÷ΕΈΟϊ | Οη ω |
|---|---|---|
| ΡΎ÷ΟΧΊ’ςΉ÷ΕΈ | docWeight | ΈΡ±ΨœύΙΊ–‘Ζ÷ ΐΘ§”Ο”ΎΚβΝΩ query ”κΈΡΒΒΒΡΤΞ≈δΕ»ΚΆ÷ ΝΩ |
| exactmatch | «ΖώΨΪ»ΖΤΞ≈δΘ§query ΚΆΈΡΒΒ «ΖώΆξ»ΪΤΞ≈δΘ§0Μρ’Ώ1 | |
| authority | »®ΆΰΕ»Θ§“ΒΈώ÷ΤΕ®ΒΡ»®ΆΰΕ»÷Β | |
| textRelLevel | ΈΡ±ΨœύΙΊ–‘Ζ÷ΒΒΘΚ1:badΓΔ2:normalΓΔ3:goodΓΔ4:perfect | |
| “ΒΈώΧΊ’ςΉ÷ΕΈ | Υυ”– ΐ÷Βάύ–ΆΉ÷ΕΈΟϊ | Υυ”– ΐ÷Βάύ–ΆΉ÷ΕΈΟϊ |
| ΡΎ÷ΟΚ· ΐ | distance(xxx,yyy,longitude,latitude) | ΦΤΥψΝΫΒψ÷°ΦδΒΡΈΜ÷ΟΨύάκΘ§xxxΓΔyyy ΈΣΈΡΒΒΨ≠Έ≥Ε»÷ΒΘ§longitude ΚΆ latitude ΈΣΦλΥς query ΒΡΨ≠Έ≥Ε»÷Β |
| max(NA,NB,query_a,Γ≠) | ΦΤΥψΉν¥σ÷Β | |
| min(NA,NB,query_a,Γ≠) | ΦΤΥψΉν–Γ÷Β | |
| avg(NA,NB,query_a,Γ≠) | ΦΤΥψΤΫΨυ÷Β | |
| sum(NA,NB,query_a,Γ≠) | ΦΤΥψΉήΚΆ | |
| abs(NA): | ΦΤΥψΨχΕ‘÷Β | |
| ΡΎ÷ΟΚ· ΐ | + - * / | ΥΡ‘ρ‘ΥΥψ |
| ==(Β»”Ύ) !=(≤ΜΒ»”Ύ) >(¥σ”Ύ) <(–Γ”Ύ) >=(¥σ”ΎΒ»”Ύ) <=(–Γ”ΎΒ»”Ύ) | ΙΊœΒ‘ΥΥψΖϊ |

