


本文提供了腾讯云向量数据库(Tencent Cloud VectorDB)采用开源工具 ann-benchmark 进行性能测试的详细数据。吞吐量 QPS 是指系统在单位时间内能够处理的查询请求数量,是衡量系统查询处理能力的重要指标。该性能测试集中测试不同维度的 QPS 数据、不同召回率下的 QPS 数据、不同数据规模的 QPS 数据。
不同维度最大 QPS 对比
测试目标:检索不同维度的数据集,向量索引选择 HNSW 类型,在召回率达到 99% 的情况下,获取最相似的 Top10的文档,对比某开源向量数据库与腾讯云向量数据库的 QPS 数据。
测试规格:向量数据库 P.MEDIUM(4CPU、8GB内存)、节点数量为 3。
测试数据集:数据量级100w,128、768、960三档维度的数据集
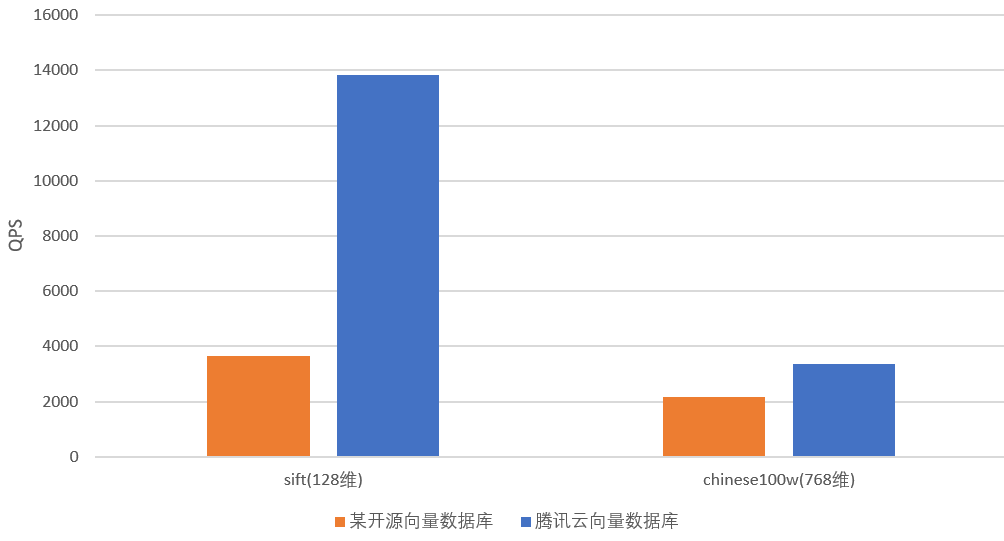
测试结论:数据集128维与768维某开源向量数据库与腾讯云向量数据库的 QPS 对比测试数据,如下所示。通过如下对比视图,可看出腾讯云的 QPS 性能具有显著优势。通过该项测试,可得出如下结论:
在不同维度的数据集下,HNSW 索引都可以达到99%以上的召回率。
在数据量相同的情况下,随着向量维度的增加,检索时资源开销增加,腾讯云向量数据库 QPS 会有所降低。
同一数据集,与某开源自建向量数据库对比,腾讯云向量数据库的 QPS 有36%到279%的提升。对比视图,如下所示。
?
数据集 | 分片和副本 | 索引类型 | 召回率 | QPS | ? |
? | ? | ? | ? | 某开源向量数据库 | 腾讯云向量数据库 |
sift-128-euclideam | shardNum=1 replicaNum=2 | HNSW(m=16,efConstruntion=200) | 99% | 3653 | 13843 (↑279%) |
? | ? | ? | chinese100w-768-angular | 2166 | 3346 (↑54%) |
? | ? | ? | gist-960-euclidean | 480 | 651 (↑36%) |
不同召回率下的 QPS 对比
测试目标:检索100w数据量级,向量索引类型为 HNSW,设置不同的查询参数 ef(指定寻找节点邻居遍历的范围),分析召回率的变化,对比 QPS 数据。
测试规格:向量数据库 P.MEDIUM(4CPU、8GB内存)、节点数量为 3。
测试数据集:chinese100w-768-angular,数据量级100w,768维度的数据集。
测试结论:测试数据,如下表所示。分析可得出如下结论。
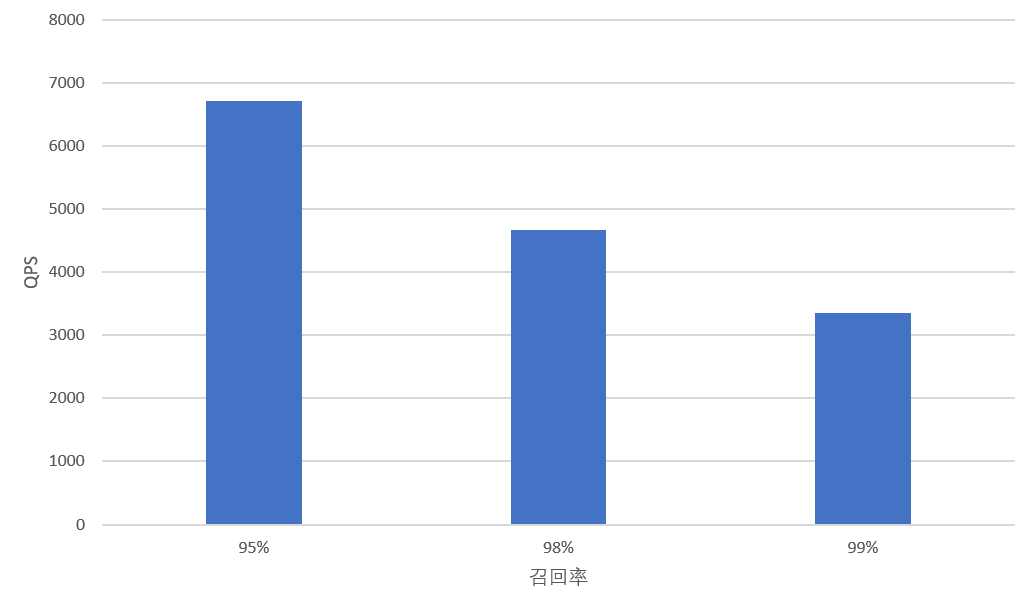
同一数据集,召回率要求越高,即 ef 参数设置越大时,QPS越低。 不同召回率 QPS 的对比视图,如下所示。
同一数据集,在其他配置不变的情况下,若需提高召回率,可适当增加查询参数 ef。
?
数据集 | 分片和副本 | 索引类型 | 查询参数 | 召回率 | QPS |
chinese100w-768-angular | shardNum=1 replicaNum=2 | HSNW(m=16,efConstruction=200) | ef=85 | 95% | 6708 |
? | ? | ? | ef=149 | 98% | 4671 |
? | ? | ? | ef=200 | 99% | 3346 |
不同数据规模 QPS 对比
测试目标:检索不同数据规模的数据集,在召回率达到95%的情况下,获取最相似的 Top10的文档,分析不同数据量级的 QPS 数据。
测试规格:向量数据库 P.LARGE(8CPU、16GB内存)、节点数量为 3。
测试数据集:chinese100w-768-angular、chinese500w-768-angular、chinese1000w-768-angular 768维度不同数据量级的数据集。
测试结论:测试数据,如下表所示。分析可得出如下结论。
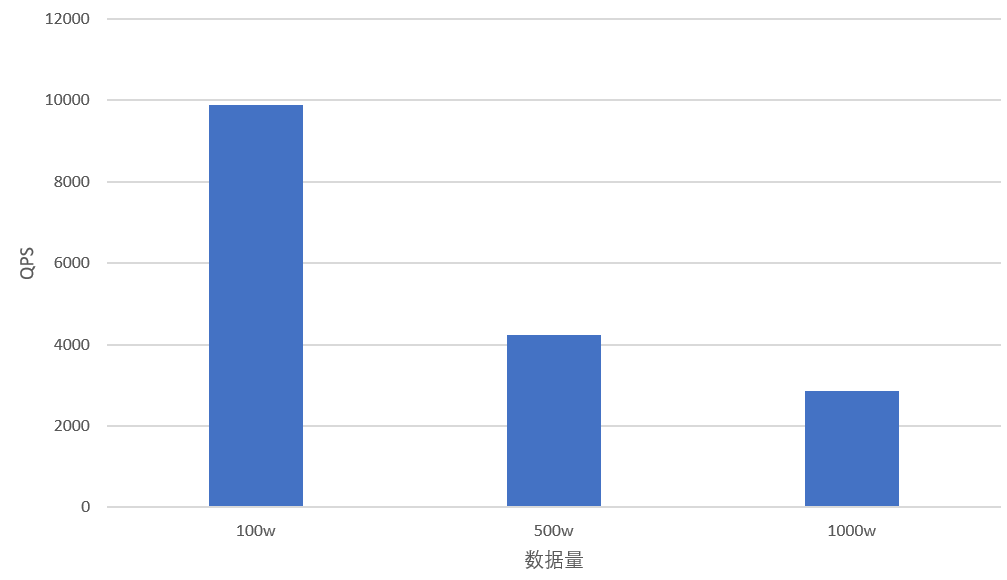
向量维度相同时,随着数据规模量级增加,检索时资源开销增加,QPS 有所降低。具体对比视图,如下所示。
从数据中可以看出,数据量越大,达到相同召回率时,需要设置的查询参数 ef 就会越大,检索过程中便需要遍历更大的搜索范围。因此,在实际应用HNSW 索引时,需要根据业务规模和召回率要求,提前测试并设置合理的 ef 参数。
?
数据集 | 数据量 | 分片和副本 | 索引类型 | 查询参数 | 召回率 | QPS |
chinese100w-768-angular | 1,000,000 | shardNum=1 replicaNum=2 | HNSW(m=16,efConstruntion=500) | ef=112 | 95% | 9891 |
? | ? | chinese500w-768-angular | 5,000,000 | HNSW(m=16,efConstruntion=500) | ef=193 | 4223 |
? | ? | chinese1000w-768-angular | 10,000,000 | HNSW(m=16,efConstruntion=500) | ef=224 | 2864 |
?

