


数据湖计算DLC(Data Lake Compute,DLC)提供了敏捷高效的数据湖分析与计算服务。服务采用无服务器架构(Serverless),开箱即用。使用标准 SQL 语法即可完成数据处理、多源数据联合计算等数据工作,有效降低用户数据分析服务搭建成本及使用成本,提高企业数据敏捷度。
?
用户无需进行传统的数据分层建模,大幅缩减了海量数据分析的准备时间,并可更进一步联合数据开发治理平台 WeData、数据集成(DataInLong)等腾讯大数据生态产品,快速构建企业级云原生实时湖计算平台。
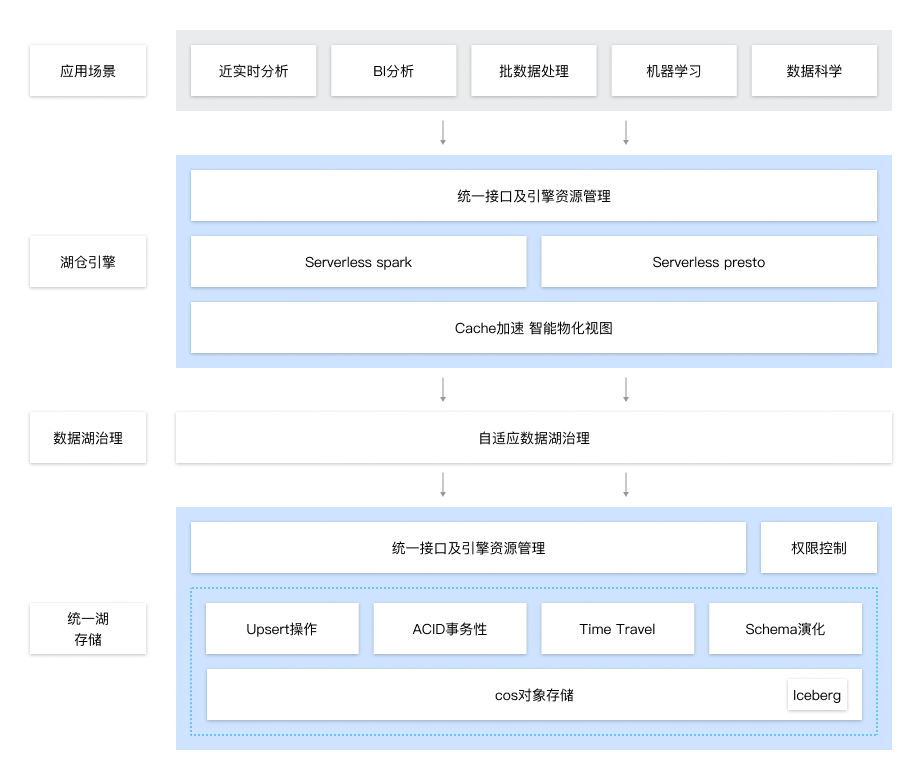
统一数据开发:对接腾讯云数据开发治理平台 WeData,实现数据湖的统一集成、开发、治理及应用。
高性能湖仓分析引擎:同时支持 Spark 和 Presto 两种引擎,统一多引擎 SQL 语法,查询缓存加速,更加敏捷、高效完成数据查询分析。
统一元数据服务:提供元数据统一管理、完善的权限体系,满足多租户使用场景。
自适应数据治理:具备湖格式智能治理能力,高效处理流式写入下的小文件合并,历史版本的过期快照删除。
统一湖存储:基于 COS 及 Iceberg 增强的数据存储,保障数据 ACID 事务性,支持物化视图缓存加速层。
主要功能
数据探索: SaaS 化开箱即用的数据湖分析
使用标准 SQL 即可完成对数据湖的轻松查询,兼容 SparkSQL,无需理解不同数据设施的数据构造,帮助客户实现由数据库场景无缝升级到大数据场景。同时支持对多源异构数据进行联合查询分析,包括MySQL、EMR Hive(COS)、EMR Hive(HDFS)等。
数据作业:极致弹性、高效降本的spark批处理
面向大数据 + AI 场景,基于原生 Spark 的批处理、流计算能力支持用户通过数据任务进行复杂的数据处理、ETL 等操作。支持机器学习及AI场景常用依赖包管理,快速构建 AI 场景的大数据基座,同时具备完善的数据访问策略管理功能,支持配置数据访问策略,保障数据安全。
数据管理:易用、全面的数据湖综合治理能力
提供数据湖统一元数据管理视图,可创建、编辑数据湖整体数据目录,及新建、查询、删除数据库表及数据视图,消除数据孤岛。同时支持备湖格式智能数据治理,用户无需关注复杂的数据湖格式治理与优化,DLC 将智能处理各种因频繁碎片写入而产生的海量小文件以及孤儿快照,综合提升数据湖查询性能。
数据引擎:超大规模计算扩展,弹性降本增效
提供灵活、高效的 Spark 和 Presto 云原生计算引擎弹性管理,支持多种扩缩容规则配置,显著降低数据湖查询分析综合成本,充分贴合业务真实使用曲线。DLC 以低成本、高弹性的云原生数据湖解决方案,助力企业建立统一数据资产,最大化发挥性能优势,赋能业务应用敏捷创新。

