


进入任务开发页面
1. 登录 数据开发治理平台 WeData 控制台。
2. 单击左侧菜单中的项目列表,找到需要使用任务开发功能的目标项目。
3. 选择项目后,单击进入数据开发模块。
4. 单击左侧菜单中的编排空间。
任务开发概述
WeData 的任务开发是将计算任务编排为数据工作流进行流程化数据处理,并通过调度策略、监听事件、任务参数、自依赖和函数库等功能来支持灵活的数据开发流程。它能够满足用户对数据处理、加工和转换的需求,并提供可视化的配置界面,使用户能够方便地构建和管理复杂的数据处理流程。
流程化数据处理
定义数据在不同任务之间的流转和转换规则,实现数据的加工、清洗、转换等操作。
数据工作流编排
将计算任务作为数据处理节点,以数据工作流的形式进行编排和组织,形成一个完整的数据处理过程。
调度策略
调度策略用于确定何时执行任务。基于周期性的调度时间与其他条件自动触发工作流执行,确保任务按照预定的顺序和时间进行处理,以满足不同的业务需求。
监听事件
监听事件适用于计算任务依赖某个事件触发执行的场景,由触发程序、触发事件和监听任务组成,首先在项目下需要根据业务定义触发事件,然后编写触发程序发送事件,任务监听到事件触达后即可运行。
任务参数和参数传递
支持在数据工作流设计与计算任务配置中使用变量参数,并支持参数在任务之间的传递。可以为每个计算任务设置不同的输入参数,并将任务的输出参数传递给下一个任务,实现数据在不同任务之间的共享和交互。
自依赖
计算任务运维时支持自依赖,即任务在调度运行时,可以依赖其前一个周期的执行状态。
函数库
提供函数库功能,其中包含了 Hive SQL、Spark SQL、DLC 的常用函数和算法,例如数学函数、数据转换函数、聚合函数等,并且支持 UDF 自定义函数,以帮助用户进行数据处理和计算操作,为用户提供更灵活和丰富的数据处理能力。
数据开发协作
WeData 数据开发中创建、编写和调试开发脚本与数据工作流协同使用。在开发空间中配置完成的即席开发的脚本可以直接参与到数据工作流的编排中,成为其中的一个任务节点,实现代码复用和整体流程的优化。
工作流介绍
编排空间提供了数据工作流的编排与配置功能,支持用户根据工作流组织开发不同类型的任务代码,并提交到调度系统进行周期性运行。一个项目下可包含多个工作流,WeData 支持将不同的工作流归放在同一个文件夹下以进行方便高效的管理。工作流是多种类型任务对象的集合,包括数据集成、计算任务(Hive SQL 、JDBC SQL 、MapReduce 、PySpark 、Python 、Shell 、Spark 、Spark SQL 、DLC SQL、DLC Spark 、Impala 、TCHouse-P 、Trino ),通用任务。
工作流目录
?
目录功能:
功能 | 描述 |
搜索 | 支持搜索文件夹、工作流和任务名称。 ?  |
全局搜索 |  ? 支持目录全局搜索,提供丰富的检索维度,可以使用关键词搜索编排空间、开发空间的计算任务与开发脚本。 ?  |
刷新 | ?  刷新:刷新目录树,获取编排目录的最新状态。 定位所在树节点:可一键定位到当前所在树节点。 收起所在树节点:可一键收起展开的所有目录。 |
批量 | ?  导入、导出:在指定目录下批量导入、导出数据工作流与计算任务。 批量操作:支持对编排目录中所有计算任务进行批量操作,操作项包括提交任务(可批量)、删除任务、修改资源组、修改责任人、修改数据源、修改任务参数、修改调度周期、修改调度高级设置、修改调度参数。可查看批量操作记录。 显示隐藏:支持显示/隐藏工作流中的任务分类文件夹。 |
新建 | 支持新建文件夹和数据工作流。 ?  |
工作流画布
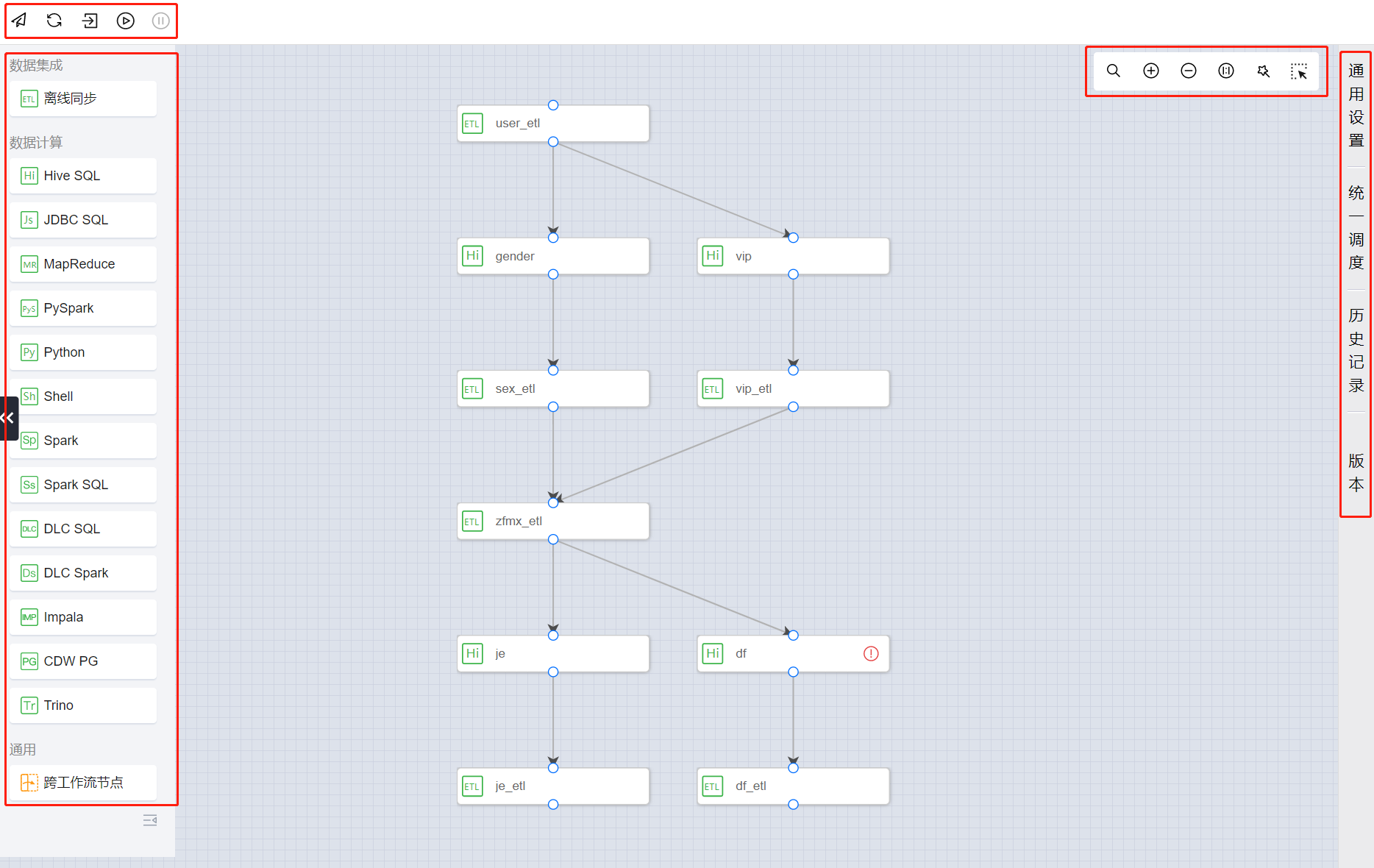
?
画布功能:
功能 | 描述 |
提交 | 单击  单击  单击  单击  ?  |
刷新 | ? |
前往运维 | ? |
工作流测试 | ? |
任务类型目录 | 在任务类型目录中,单击计算任务类型,向工作流画布中添加任务节点。 ?  |
定位 | 单击图标,在弹出的筛选框中可自由选择并定位至对应任务。 ?  |
画布缩放 | 单击图标,可以缩放工作流画布。 ?  |
格式化 | 单击图标,可以标准化工作流中各任务的排布格式。 ?  |
框选 | 单击图标,鼠标变为框选模式,可同时框选多个任务并执行批量操作。 ?  |
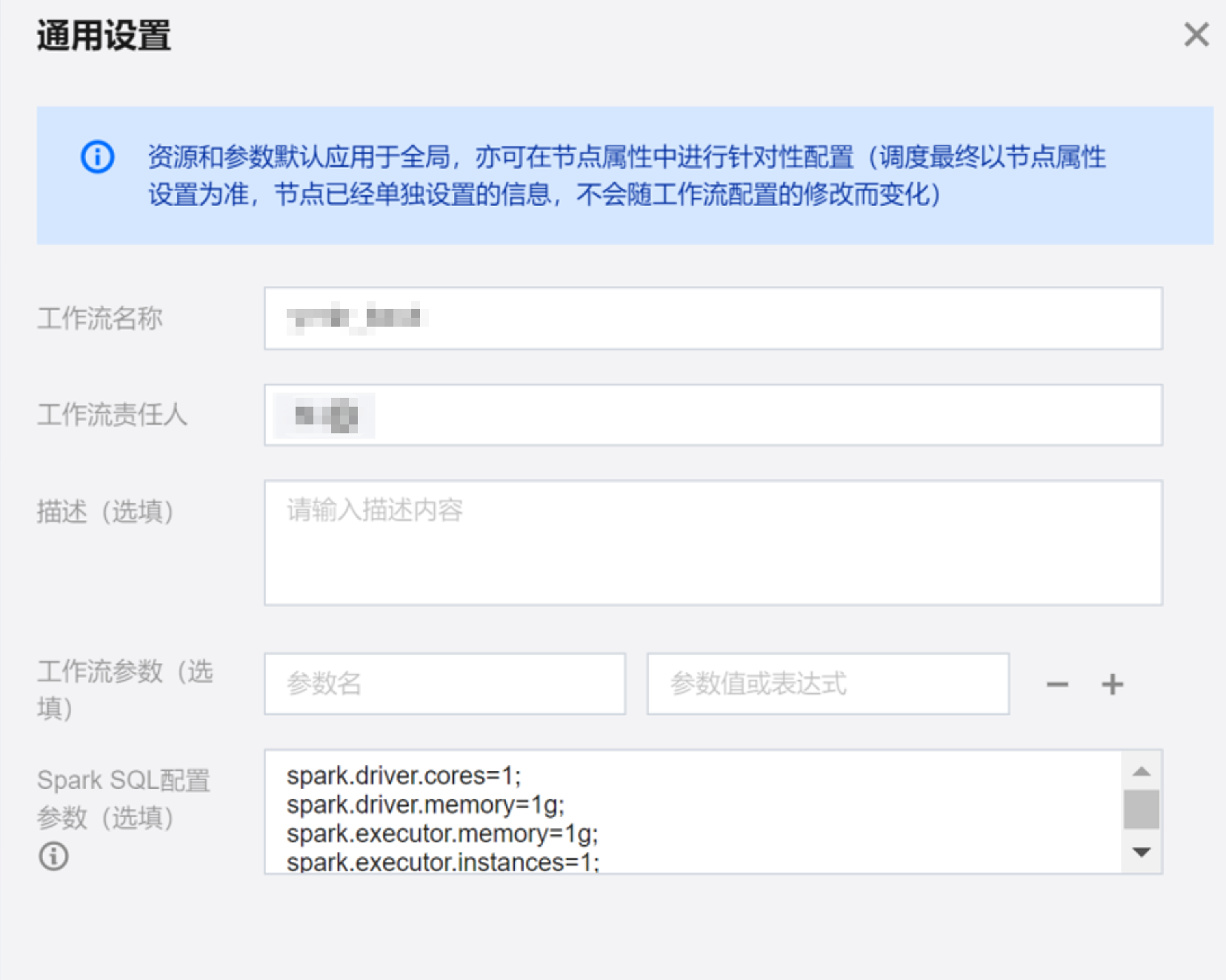
通用设置
单击右边栏通用设置,可编辑当前工作流的名称、责任人、添加描述信息、工作流变量以及 Spark SQL 配置参数(选填)。其中 Spark SQL 配置只针对工作流任务中的 Spark SQL 任务生效。
?
功能说明:
功能 | 描述 |
工作流名称 | 自定义工作流的名称。 |
工作流责任人 | 指定工作流责任人,在后续工作流提交、变更时相关权限与申请、审批等操作由负责人处理。 |
描述(选填) | 自定义工作流描述信息。 |
工作流参数(选填) | 工作流参数(选填) 作用范围是当前工作流内任务的参数,通过工作流的通用设置参数项来设定,设定规则为:变量名=变量值,多个可用“;”分隔,例如 a=${yyyyMMdd};b=123;c=456;支持填写常量和调度日期变量,详见工作流级别变量使用流程。 |
Spark SQL 配置参数(选填) | 用于配置优化参数(线程、内存、CPU 核数等),仅作用于 Spark SQL 节点。多个参数用英文分号分隔。 |
统一调度
工作流调度支持常规和 crontab 两种周期调度配置方式。常规配置可参见调度设置中的一次性、分钟、小时、天、周、月、年调度配置,crontab 配置方式更灵活,仅支持在工作流统一调度进行配置,并且 crontab 配置方式下的所有任务调度时间(crontab 表达式)必须相同,不支持配置跨工作流依赖任务,也不支持与常规配置任务建立依赖。
注意:
统一调度的操作类似于批量操作,会将当前工作流下面所有的任务周期改成统一的调度周期。建议在工作流内任务的调度周期都一致的时候使用。
常规配置方式

?
配置说明:
功能 | 描述 |
调度周期 | 任务调度的执行周期单位,支持分钟、小时、天、周、月、年和一次性。 |
生效时间 | 调度时间配置的有效时间段,系统会在该时间范围内按照时间配置自动调度,超过有效期将不会再自动调度。 |
执行时间 | 用户可自行设定该任务每次执行间隔的时长以及任务开始执行的具体时间。 如周期间隔为10分钟,则调度任务将在2022年3月27日到2022年4月27日中每天的00:00到23:59分之间每隔10分钟运行一次。 |
调度计划 | 会根据周期时间的设置自动生成。 |
自依赖 | |
工作流自依赖 | 开启后表示当前工作流中的计算任务依赖当前工作流上个周期的所有计算任务。工作流自依赖功能仅在当前工作流中的任务是同一调度周期,并且是天周期的时候生效。 |
crontab 配置方式
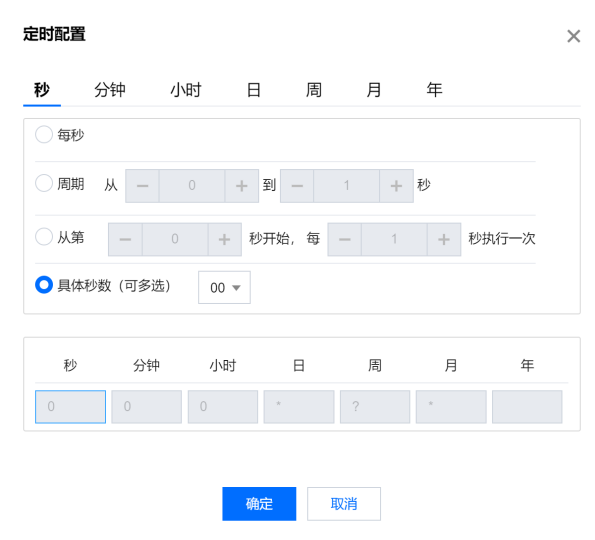
crontab 配置支持年、月、周、日、小时、分钟到秒细粒度的配置,配置完成后支持查看具体的执行时间。
?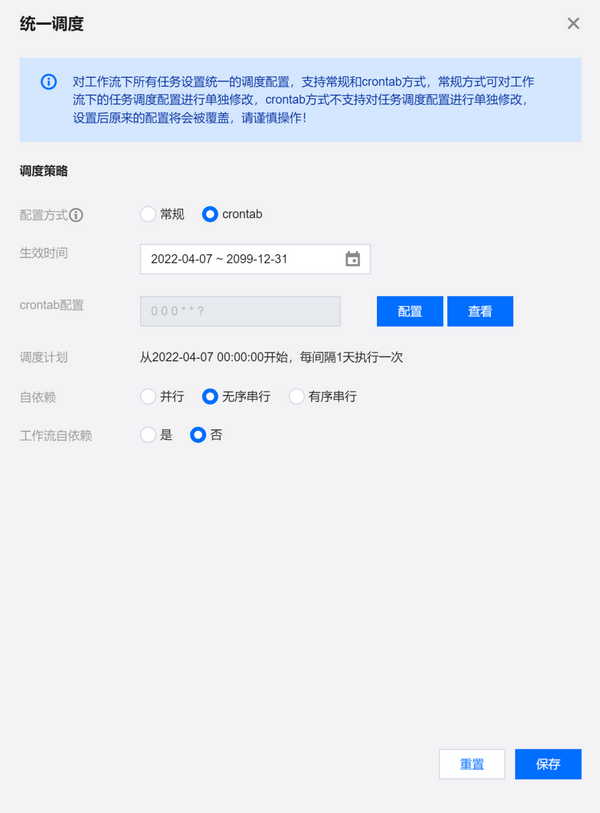
支持使用 crontab 语句配置调度周期,单击配置即可进入配置页面。
?
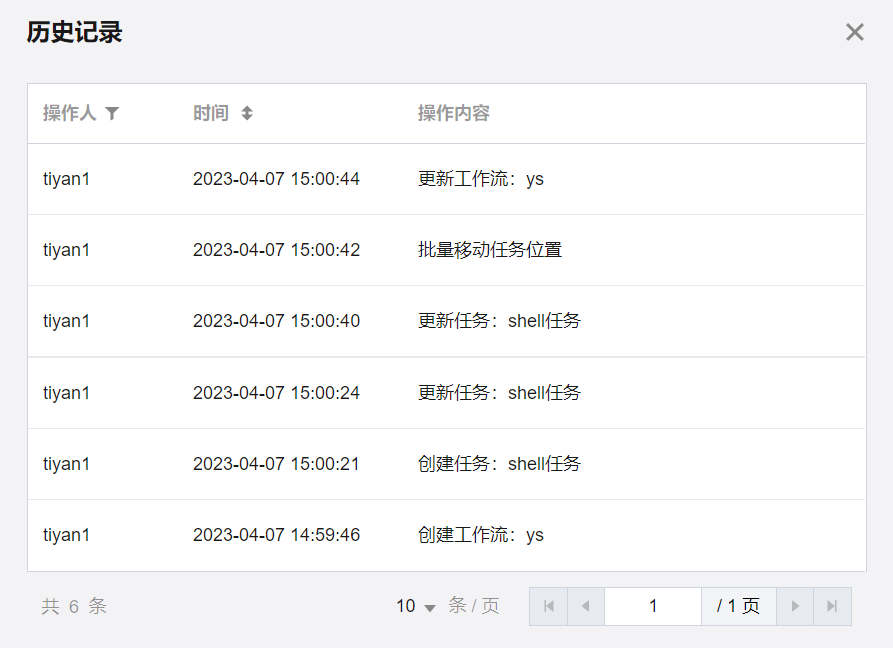
历史记录
单击右侧边栏历史记录,可查看当前工作流的历史操作信息,包括操作人(执行账号)、操作时间以及具体操作内容。
?
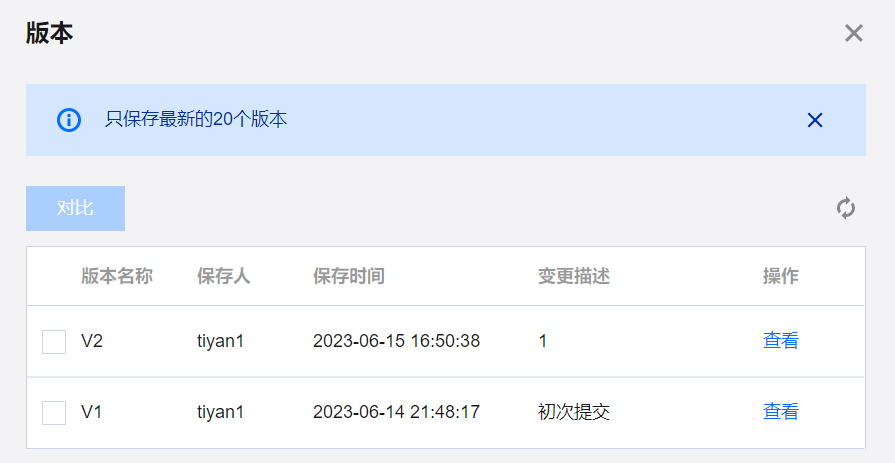
版本
数据工作流每次编辑后提交运维,相应的就会生成一个工作流版本。单击右侧边栏版本,可以查看当前工作流的历史版本信息,包括版本名称(版本号)、保存人(版本提交人)、保存时间(提交时间)、变更描述。
注意:
只有在工作流上提交的时候会产生工作流版本,单个任务提交不会产生工作流的版本。
?
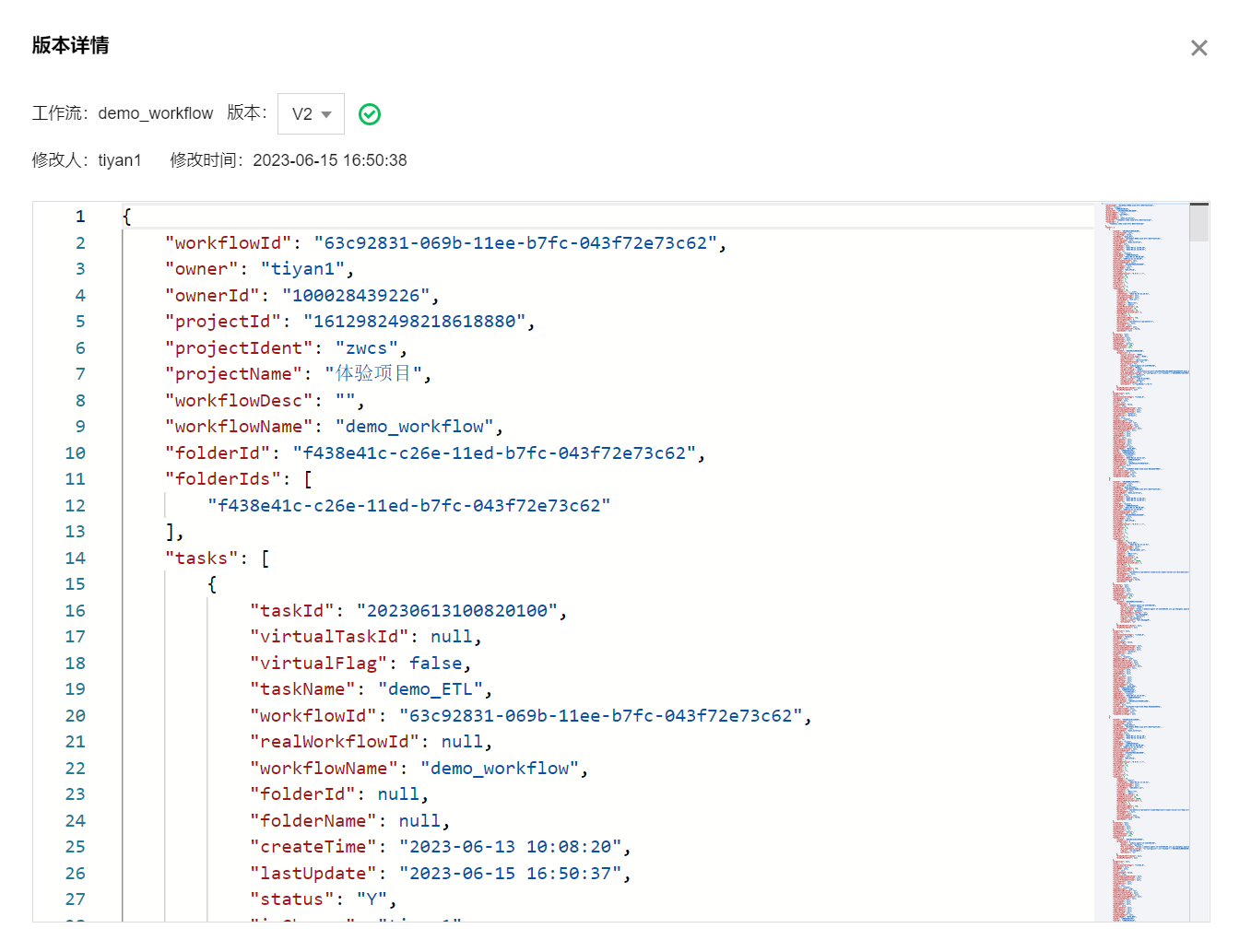
通过操作列下的查看功能,可以看到对应版本的配置信息。
?
计算任务介绍
?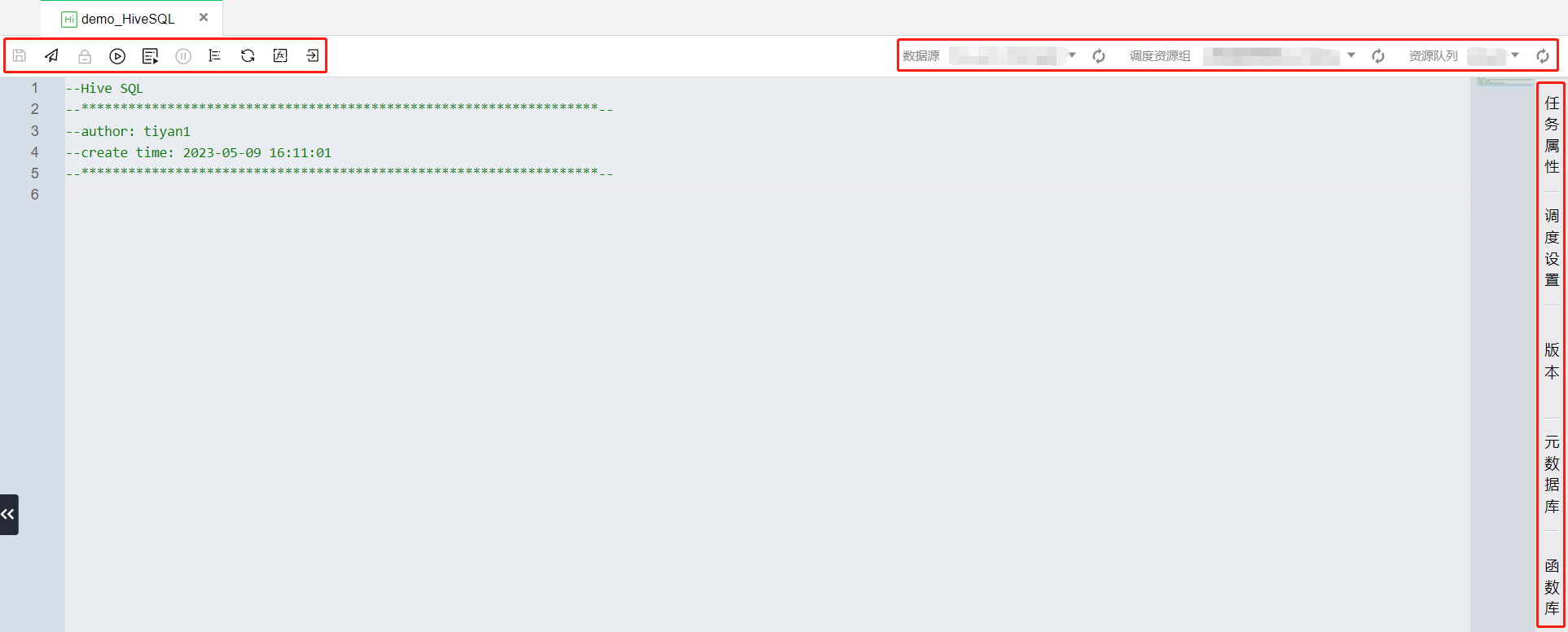
画布功能
功能 | 描述 |
保存 | 单击图标,可保存当前任务节点。 ?  |
提交 | 单击图标,可提交任务节点到调度系统(节点基础内容、调度配置属性),并生成一个新的版本记录。 功能限制:任务的数据源和调度条件设置完整以后才可以正常提交。 ?  |
锁定/解锁 | 单击图标,可锁定/释放当前文件的编辑,若任务已被他人锁定,则无法编辑。 ?  |
运行 | 单击图标,可调试运行当前任务节点。 ?  |
高级运行 | ?  单击图标,可运行当前带有变量的任务节点。系统会自动弹出代码中使用的时间参数和自定义参数。 ? 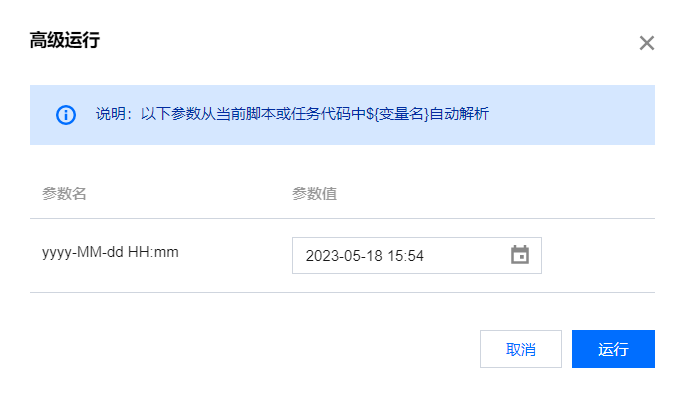 |
停止运行 | 单击图标,可停止调试运行当前任务节点。 ?  |
格式化 | 单击图标,可标准化任务中代码语句的格式。 ?  |
刷新 | 单击图标,刷新当前任务节点的内容。 ?  |
项目变量 | 单击图标,可查看项目全局变量,在任务中进行使用。 ?  |
前往运维 | 单击图标,可前往任务运维页面,并自动筛选当前任务。 ?  |
数据源 | 选择当前计算任务使用的数据源。 ?  |
执行资源组 | 选择当前计算任务执行时的执行资源组。 ?  |
资源队列 | 选择当前计算任务执行时使用的资源队列。 ?  |
任务属性
可以修改当前任务的任务名称、任务责任人、任务描述信息、定义任务调度参数、使用应用参数,提供自动解析代码变量的功能,提供参数说明文档辅助调度参数功能使用。
调度参数的使用方法详见:任务级别变量使用流程。
应用参数的使用方法详见:应用参数使用流程。
?
调度设置
版本
展示计算任务的历史提交记录,可以在版本面板查看节点历史版本、提交人、提交时间、变更类型、状态、备注等信息。可查看单个版本的信息,并支持两个版本之间的勾选对比。
?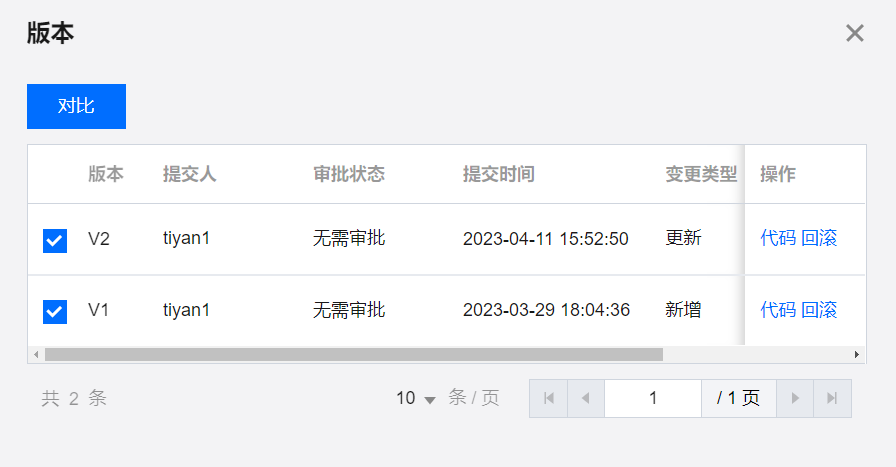
只有提交过的任务节点才会存在版本信息,否则版本信息为空。
每次提交都会生成一个新版本,并在版本面板产生一条新纪录。
对比:提供计算任务历史版本间的两两对比,以代码与任务配置参数的形式展示两者的关键信息。

?
代码:支持查看计算任务任意版本状态下的代码与配置参数。
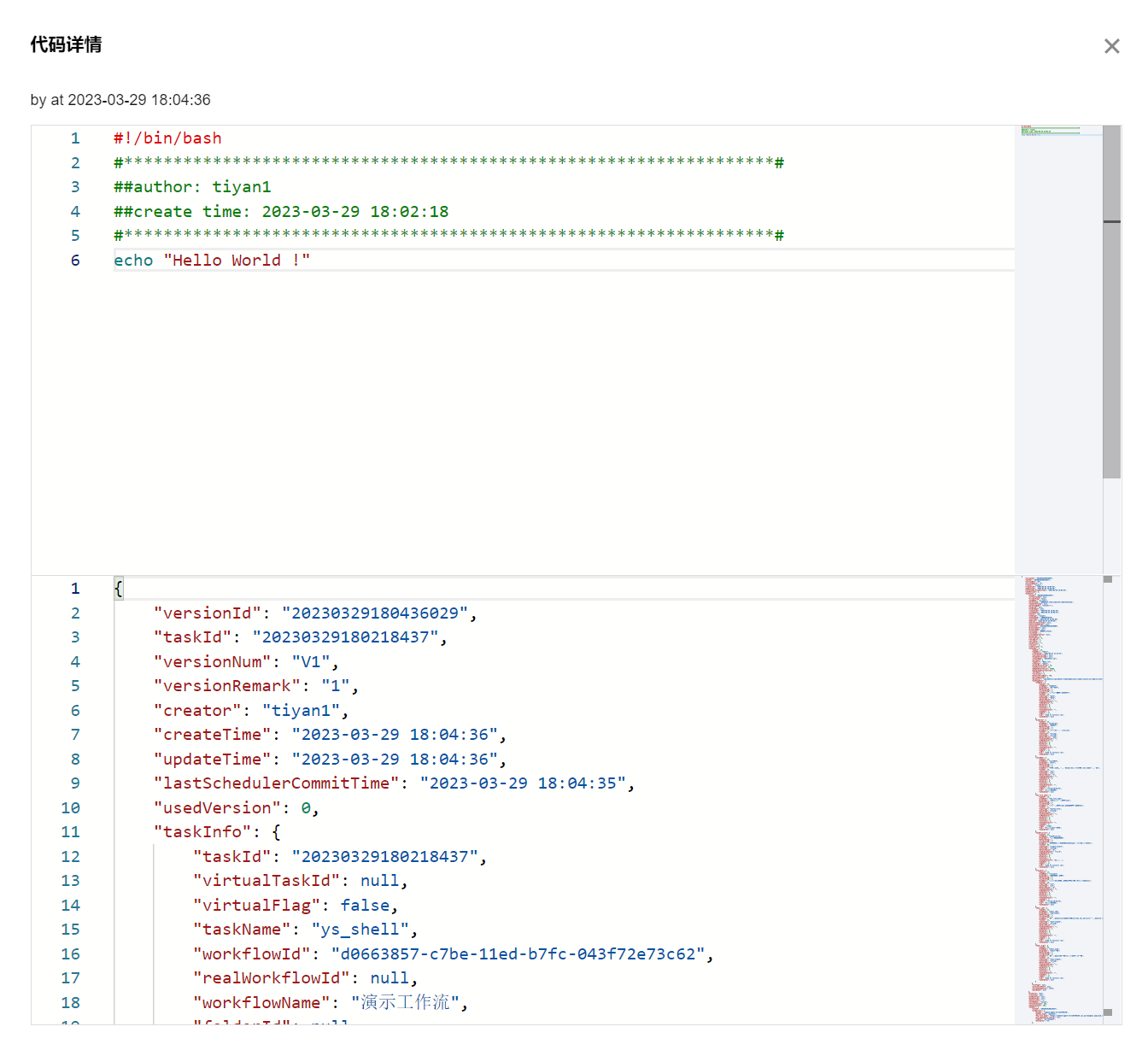
?
回滚:仅针对任务的脚本内容和配置进行回滚,不包含依赖关系,回滚后执行提交方可生效。回滚后,当前未提交的修改内容(包括代码和任务配置)将会丢失。
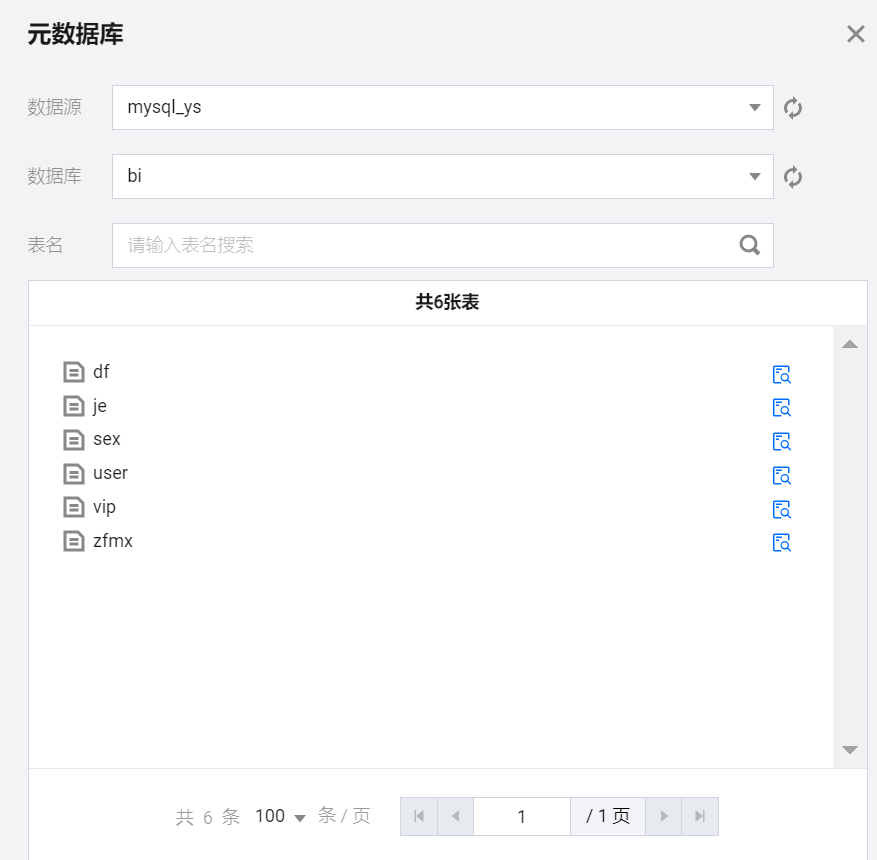
元数据库
展示当前项目下接入数据源的元数据信息,可以通过检索数据源、数据库、数据表的方式获取库表信息,方便在任务开发过程中快速使用,提供复制表查询 SQL、表 DDL、表名的快捷功能。
注意:
当前复制表查询 SQL、表 DDL 的能力仅支持系统数据源。
?
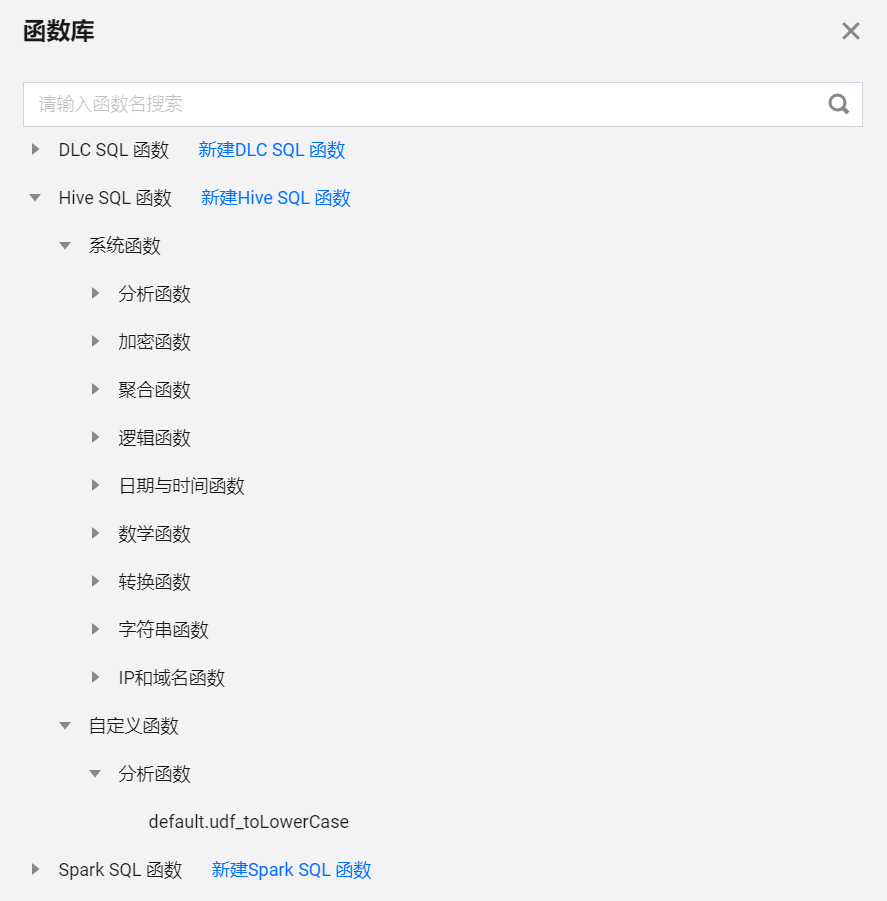
函数库
展示在任务开发中可以使用的函数,目前支持 DLC SQL、Hive SQL、Spark SQL 函数,根据开发任务针对的引擎进行选择。函数库内置了常用的系统函数,例如分析函数 corr、covar_pop,加密函数 hash、md5,逻辑函数 decode、nvl 等。另外支持使用自定义函数,通过资源管理上传的函数包经过函数开发功能创建后,即可在该函数库中展示出来,开发任务中即可调用。自定义函数创建详见:函数开发。
?
?

