大数据平台的资源管理组件主要涉及存储资源和计算资源管理两部分,属于大数据平台运维管理系统。基于资源管理系统,大数据平台的开发运维人员能够清晰掌控平台的资源使用情况和资源在不同时间段下的变化趋势,能对资源使用异常进行及时发现并定位处理,避免造成更严重的影响,如磁盘空间撑爆,计算资源无空余,任务长时间等待不运行等造成业务阻塞。
资源管理系统核心目的:对于大数据平台的资源管理,让一切人对机器的操作尽可能自动化,让一切人的决策基于数据,提供如下能力:
大数据平台的资源管理主要从两个维度出发:存储、计算;以增强和便捷大数据平台的运维能力,包括如下方面:
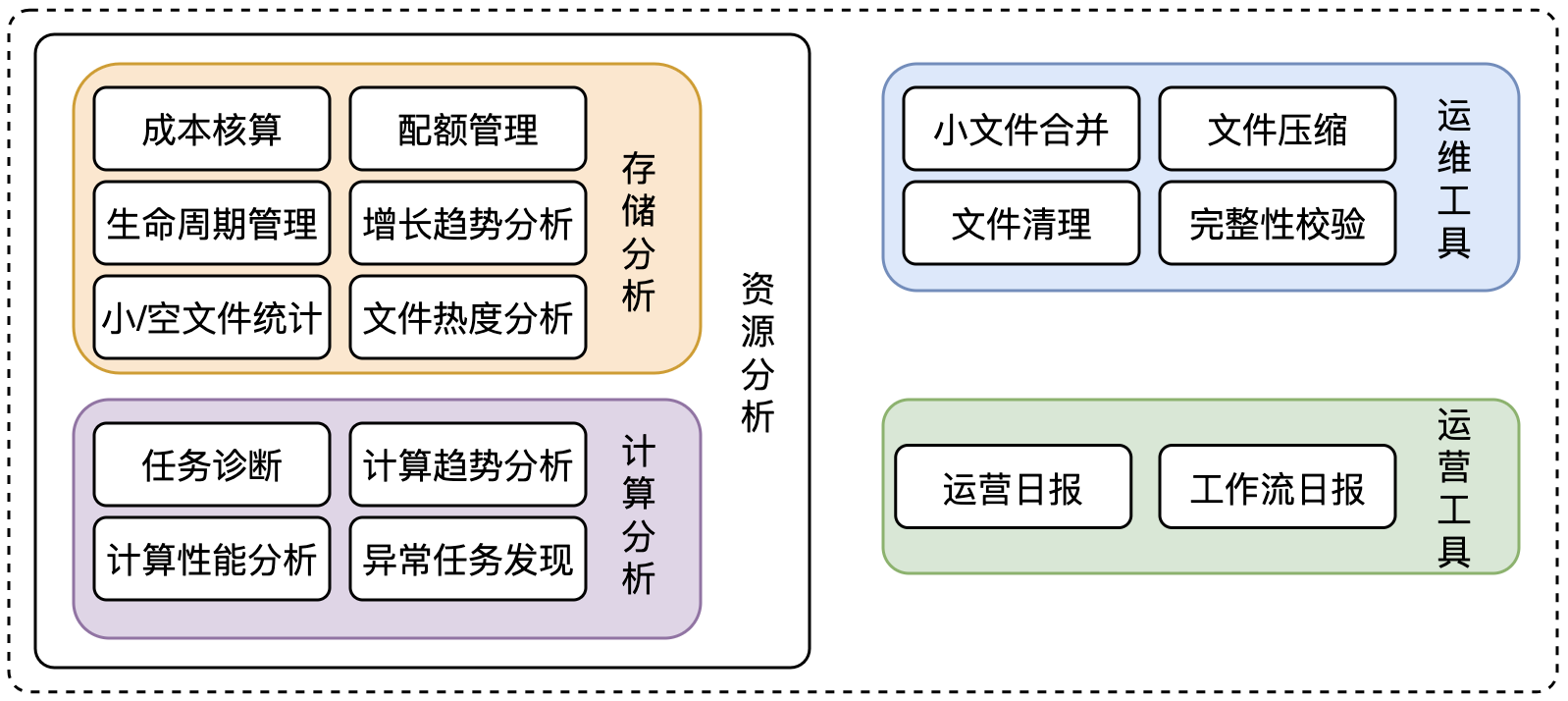
TBDS资源管理核心功能包括三部分:
大数据平台存储优化,主要基于HDFS实现,HDFS整体架构如下所示,属于主从(master-slave)架构,一个HDFS集群一般包括:
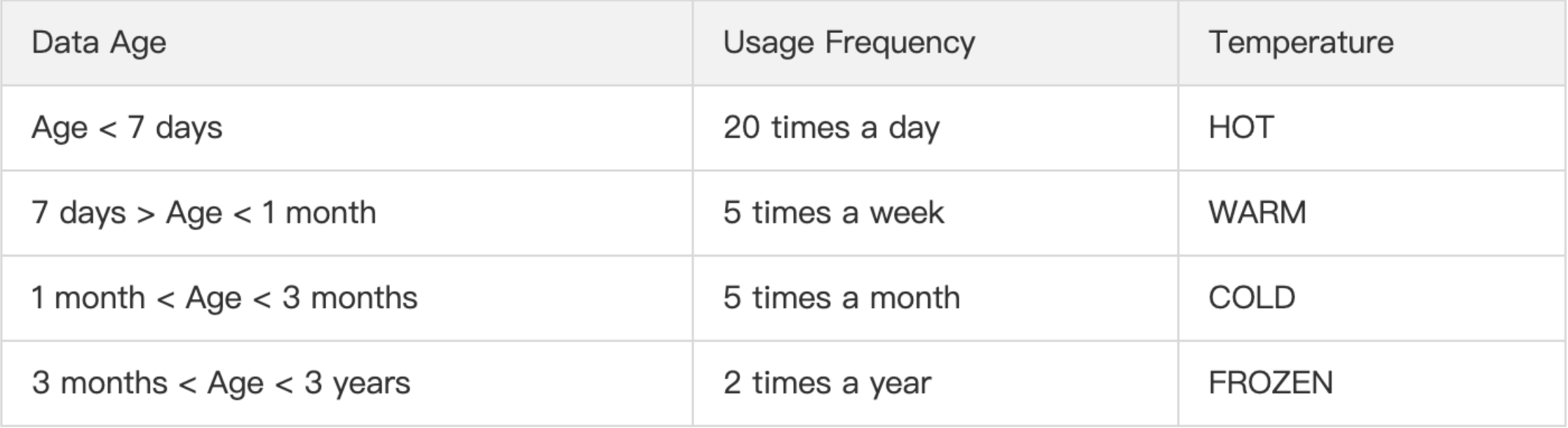
根据HDFS上存储数据的使用频率,将数据标记为不同的温度,数据温度标记示例如下:
HDFS从Hadoop2.3开始支持分层存储,可以基于不同的数据温度映射到不同的存储层,利用服务器不同类型的存储介质(HDD硬盘,SSD,内存等)提供更多的存储策略。
HDFS支持的分层存储介质,基于温度从低到高包括:

其中HDFS存储策略:
在Hadoop 2.x及以前的版本中,HDFS主要依靠数据副本来实现容错,通常会创建三个副本来保证数据可用性。
纠删码(erasure coding,EC):是一种数据保护技术,RAID的延伸,将数据分割为片段,把冗余数据块扩展、编码,并将其存储在不同的节点位置,是分布式存储中热门技术。纠删码基于数学函数来描述对象,以检查对象的准确性,若数据丢失和非准确,可以根据纠删码恢复,常用的纠删码技术:多项式插值(polynomial interpolation),过采样(oversampling)。
基本结构:总数据块(n) = 原始数据库(k) + 校验块(m),即n=k+m;
纠删码主要使用两类编码:
1. RS编码
RS(Reed-Solomon)编码,是一种常用的向前纠错(forward error correction, FEC)的纠错编码,是MDS种常用的一类。是一类纠能力很强的多进制BCH码。RS编码涉及三个主要问题:
2. LRC编码
LRC(locally repairable codes)编码:是基于RS编码改进,可有效减少数据修复时的系统负载,即:在可靠性与RS编码大致相同的情况下,减少恢复损坏数据所需的数据块数量。
在Hadoop3.0开始引入支持HDFS文件块级别的纠删码,底层采用Reed-Solomon(k,m)算法。在不牺牲太多计算性能的情况下,以更小的存储空间提供与传统副本相当的数据冗余能力。
HDFS Federation为HDFS系统提供了NameNode水平扩容能力,避免NameNode中的存储元数据丢失,造成单点故障。社区最早从Apache Hadoop 0.23.0版本开始引入了HDFS federation。HDFS Federation是指 HDFS集群可同时存在多个NameNode/Namespace,每个Namespace之间是互相独立的;单独的一个Namespace里面包含多个 NameNode,其中一个是主,剩余的是备,这个和上面我们介绍的单Namespace里面的架构是一样的。这些Namespace共同管理整个集群的数据,每个Namespace只管理一部分数据,之间互不影响。
迭代1:ViewFs
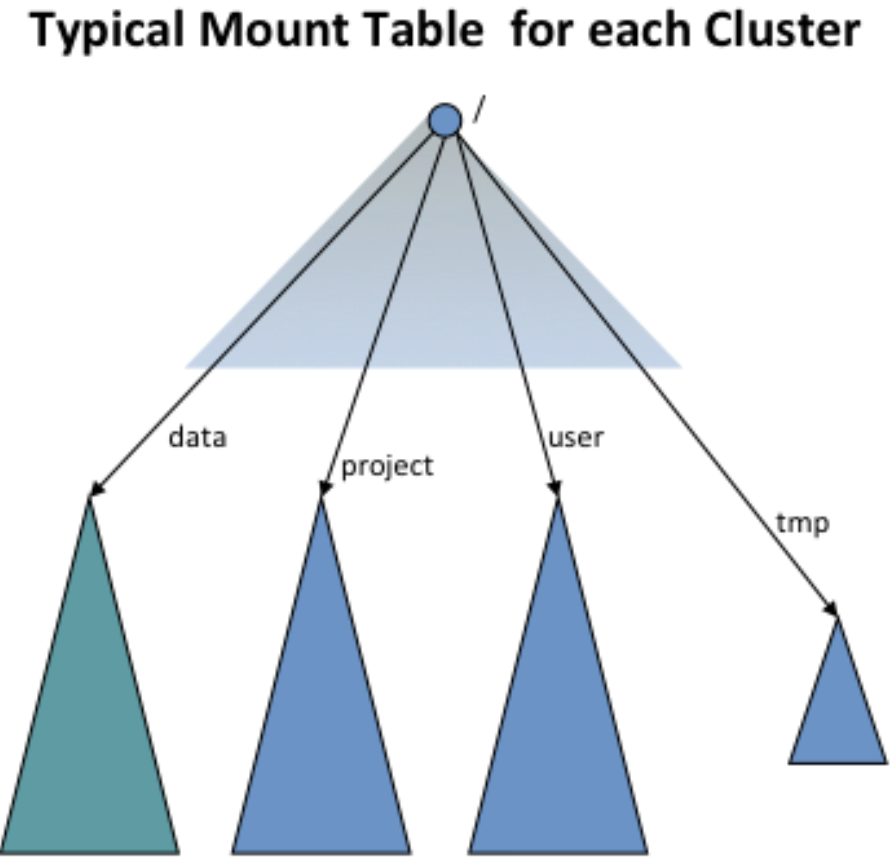
基于 HDFS Federation模式,允许一个集群内存在多个Namespace,每个Namespace只管理部分数据。客户端在查询时需要无感知查询数据,而无需关注各Namespace的数据组合。社区引入了视图文件系统(View File System,简称 ViewFs),映射各个Namespace的指定存储路径,类似于某些 Unix / Linux 系统中的客户端挂载表,fs.defaultFS的值已经变成了viewfs://clusterX。
如图:ViewFs分绑定了不同Namespace的路径包括 /data, /project, /user, /tmp.
迭代2:Router-based Federation (RBF)
ViewFs的实现方案,存在几个问题:
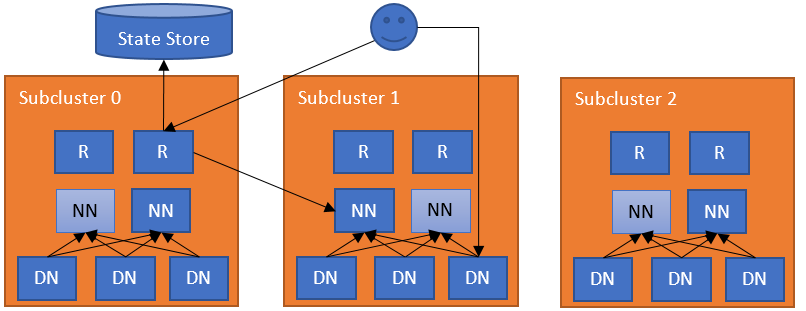
为解决以上问题,社区从Hadoop 2.9.0(HDFS-10467)开始引入一种基于路由的Federation方案(Router-Based Federation),简称RBF,基于服务端实现。在Client和集群NameNode服务之间新加了一层Router服务,Router接口与NameNode接口保持一致,基于State Store维护 Router挂载路由信息,所有客户端请求由Router转发给下游的NameNode节点。
备注:基于RBF进行NameNode联邦,由于所有请求需要经过Router转发,Router服务也会存在性能瓶颈
由于Hadoop的Block size一般是64MB,128MB或者256MB,如果文件小于默认值,也会存储占用一个Block存储,而这些明显小于Block大小的HDFS文件称为小文件。
严峻的小文件问题会对Namespace内存管理和计算性能造成影响:
现有的小文件合并方法主要包括:
以下将针对小文件合并的实现细节进行说明主要分为三个步骤:
FsImage镜像文件是Protobuf编码的, HDFS官方提供多种解析方式,将PB镜像文件解析为易读的文本格式,详情查看,支持的输出方式有:
解析命令说明如下:
hdfs oiv
Required command line arguments:
-i,--inputFile <arg> 指定解析的FsImage镜像文件
Optional command line arguments:
-o,--outputFile <arg> 解析后的输出文件,如果文件存在则覆盖
-p,--processor <arg> 选择镜像解析方式 (XML|FileDistribution|Web|Delimited)
(Web by default),方式说明详见上文
-delimiter <arg> Delimited解析方式指定的分隔符
-t,--temp <arg> Delimited解析时若镜像文件过大,文件的父子关系无法直接在内存执行,指定逻辑磁盘的临时目录因为对于某些字段是不关注的,如文件RWX权限信息。为减少解析后文件大小,镜像解析可参考Delimited方式实现自定义扩展。解析后的FsImage镜像文件可以上传HDFS便于后续Spark离线任务并发读取镜像文件。
基于解析后的文件元数据信息,可启动Spark离线任务进行镜像文件的统计计算,并把分析结果按照不同聚合维度持久化到数据库中,包括MySQL(PG)和HBase,若所有的HDFS目录信息都持久化,每天的数据达到1000万以上,传统关系型数据存储压力大,因此采用HBase存储统计后的文件目录信息,HBase数据查询基于Phoenix实现。
除了Hadoop系统提供的合并方法,开发者可以通过外置功能来实现小文件合并,以下给出基于Spark自定义任务实现小文件合并的思路:
支持的合并类型:(1). HDFS 文件类型;(2). 分区表类型
小文件合并需要用户主动触发的,系统不会自动执行文件合并,文件合并是个危险操作,合并前操作人员需要确保该目录下文件合并后不影响业务使用,或者合并后需要主动告知业务,文件使用方式变化,即小文件的合并是跟具体的业务使用挂钩的,不能进行随意合并,小文件合并的执行流程如下:
Action执行提交的Spark离线合并任务;
合并前需要识别HDFS文件类型和压缩方式
FileSystem 遍历获取指定目录所有文件列表,若文件超过合并阈值则忽略;获取路径下的所有待合并小文件列表;文件头(MimeType)与文件类型对应表:
文件头/MimeType | 文件类型 |
|---|---|
text/plain | TEXT File |
ORC | ORC File |
SEQ | Sequence File |
Obj(Objavro) | AVRO File |
PAR | PARQUET File |
文件后缀名与压缩方式对应表:
文件后缀名 | 压缩方式 | 压缩类 |
|---|---|---|
.deflate | DEFLATE压缩 | org.apache.hadoop.io.compress.DefaultCodec |
.gz | GZIP压缩 | org.apache.hadoop.io.compress.GzipCodec |
.bz2 | BZIP2压缩 | org.apache.hadoop.io.compress.BZip2Codec |
.lzo_deflate | LZO压缩 | io.airlift.compress.lzo.LzoCodec |
.lz4 | LZ4压缩 | org.apache.hadoop.io.compress.Lz4Codec |
.snappy | SNAPPY压缩 | org.apache.hadoop.io.compress.SnappyCodec |
.lzo | LZOP压缩 | io.airlift.compress.lzo.LzopCodec |
.bz2 | ZLIB压缩 | org.apache.orc.impl.ZlibCodec |
其他 | 不进行压缩 | 无 |
以下操作简述不同的HDFS文件格式的判断与获取:
AVRO文件类型:
private CodecType readAvroCodec(Path path) throws Exception {
try (DataFileStream reader = new DataFileStream(fs.open(path), new GenericDatumReader())) {
Schema schema = reader.getSchema();
String codec = reader.getMetaString("avro.codec");
LOG.info("read avro file by header info of schema={}, codec={}", schema, codec);
return CodecType.getTypeByName(codec, CodecType.NONE);
}
}SEQ(Sequence)文件类型:
private CodecType readSeqCodec(Path path) throws Exception {
try (SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(path))) {
CompressionCodec compressionCodec = reader.getCompressionCodec();
LOG.info("read seq file with compression type={}, codec={}", reader.getCompressionType().name(), compressionCodec.getCompressorType().getName());
return CodecType.getTypeByCodec(compressionCodec.getClass().getName(), CodecType.NONE);
}
}ORC文件类型:
private CodecType readORCCodec(Path path) throws Exception {
Reader reader = OrcFile.createReader(path, OrcFile.readerOptions(conf));
CompressionKind codec = reader.getCompressionKind();
LOG.info("read orc file of path={}, codec={}", path, codec);
return CodecType.getTypeByName(codec.name(), CodecType.NONE);
}PARQUET文件类型:
private CodecType readParquetCodec(Path path) throws Exception {
ParquetMetadata metadata = ParquetFileReader.readFooter(conf, path, ParquetMetadataConverter.NO_FILTER);
CompressionCodecName codec = CompressionCodecName.UNCOMPRESSED;
try {
codec = metadata.getBlocks().get(0).getColumns().get(0).getCodec();
} catch (Exception e) {
LOG.error("get codec info of parquet file error", e);
}
return CodecType.getTypeByName(codec.getParquetCompressionCodec().name(), CodecType.NONE);
}TEXT和其他类型,根据文件后缀名识别
private CodecType detectCodecTypeByExt(DirPathInfo dirPathInfo) {
List<Path> randomPaths = this.getRandomPaths(dirPathInfo.getFilePaths());
CodecType finalCodec = null;
boolean same = true;
for (Path path : randomPaths) {
String extension = FilenameUtils.getExtension(path.getName());
CodecType codec = CodecType.getTypeByExtension(extension);
Preconditions.checkNotNull(codec, "[merge.detect_codec_null] can't get dir path info of codecType");
if (finalCodec == null) {
finalCodec = codec;
}
if (finalCodec.getClass() != codec.getClass()) {
same = false;
break;
}
}
Preconditions.checkArgument(same, "[merge.detect_codec_mismatch] file codec type is not same for dir=" + dirPathInfo.getDirPath());
return finalCodec;
}基于Spark作业执行合并时,需要保证合并前后的文件类型和压缩压缩方式一致。不同文件类型的读写实现如下:
TEXT读写
spark.read().textFile(dirInfo.getFilePathSeq())
.coalesce(1).write().option("compression", sparkCodec).text(targetPath);ORC读写
spark.conf().set("spark.sql.orc.impl", "native");
spark.read().orc(dirInfo.getFilePathSeq())
.coalesce(1).write().option("compression", sparkCodec).orc(targetPath);AVRO读写
spark.conf().set("spark.hadoop.avro.mapred.ignore.inputs.without.extension", false);
spark.conf().set("spark.sql.avro.compression.codec", sparkCodec);
spark.read().format("com.databricks.spark.avro").load(dirInfo.getFilePathSeq())
.coalesce(1).write().format("com.databricks.spark.avro").save(targetPath);PARQUET读写
spark.conf().set("spark.sql.parquet.binaryAsString", "true");
spark.conf().set("spark.sql.parquet.enableVectorizedReader", "false");
spark.read().parquet(dirInfo.getFilePathSeq())
.coalesce(1).write().option("compression", sparkCodec).parquet(targetPath);SEQUENCE读写
Path randomPath = new FileManager(conf).getRandomPath(dirInfo);
SequenceFile.Reader reader = new SequenceFile.Reader(conf, SequenceFile.Reader.file(randomPath));
JavaSparkContext sc = new JavaSparkContext(spark.sparkContext());
if (codec != CodecType.NONE) {
sc.hadoopConfiguration().set("mapreduce.output.fileoutputformat.compress", "true");
sc.hadoopConfiguration().set("mapreduce.output.fileoutputformat.compress.codec", codec.getCodec());
sc.hadoopConfiguration().set("mapreduce.output.fileoutputformat.compress.type", "BLOCK");
}
sc.sequenceFile(dirInfo.getFilePathNames(), reader.getKeyClass(), reader.getValueClass())
.map(tuple -> new Tuple2(tuple._1.toString(), tuple._2.toString()))
.coalesce(1).saveAsObjectFile(targetPath);资源管理组件是大数据平台中的运维组件,对于普通用户基本不可见,更多是辅助管理员进行运维管理。一个好的资源管理组件,会尽可能的将资源可视化,提供资源优化的运维建议,帮助运维发现资源瓶颈,及时进行资源扩缩容调整。
本文主要概述了资源管理组件的背景及系统核心能力;针对存储资源,介绍了HDFS四个优化技术点:分层存储、纠删码、NameNode Federation和小文件合并;最后,介绍了小文件合并的相关的实现细节,主要包括:镜像解析、离线分析任务、和自定义小文件合并实现。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。