


Ambari是Hortonworks主导发行的开源管理平台,作为Apache顶级项目,Ambari也是最早且最成熟的大数据集群管理开源组件,可类比于Cloudera研发的CDH Manager。在容器化未盛行的时候,是商用(toB/toC)大数据平台构建的不二选择,用于简化Apache Hadoop集群的配置和管理。除了Hadoop集群,基于可扩展配置文件,用户可扩展自定义组件的部署和运行管理。Ambari 提供了一个易于使用的Web UI和API,使得系统管理员可以对集群进行监控、配置和管理。
Ambari 提供的主要功能包括:
Ambari 具备特点:
Ambari的主要项目结构如下所示:
目录 | 描述 |
|---|---|
ambari-server | 对外提供Rest API,维护集群的运维管理元数据,与Agent保持心跳,下发执行命令 (Java、Python实现) |
ambari-agent | 接收Server端命令,并在本机执行,并向Server上报执行结果,定时采集本机组件服务、机器的监控信息 (Python实现) |
ambari-shell | 提供Shell的进行Ambari的基本运维操作(主要包括:cluster、blueprint、configuration操作,包括 Groovy和Python两种实现) |
ambari-common | 主要供Server和Agent公用的Python代码库 |
ambari-metrics | 内置监控指标的定义、收集、聚合 |
ambari-server 子项目主要模块:
ambari-agent 子项目主要模块:
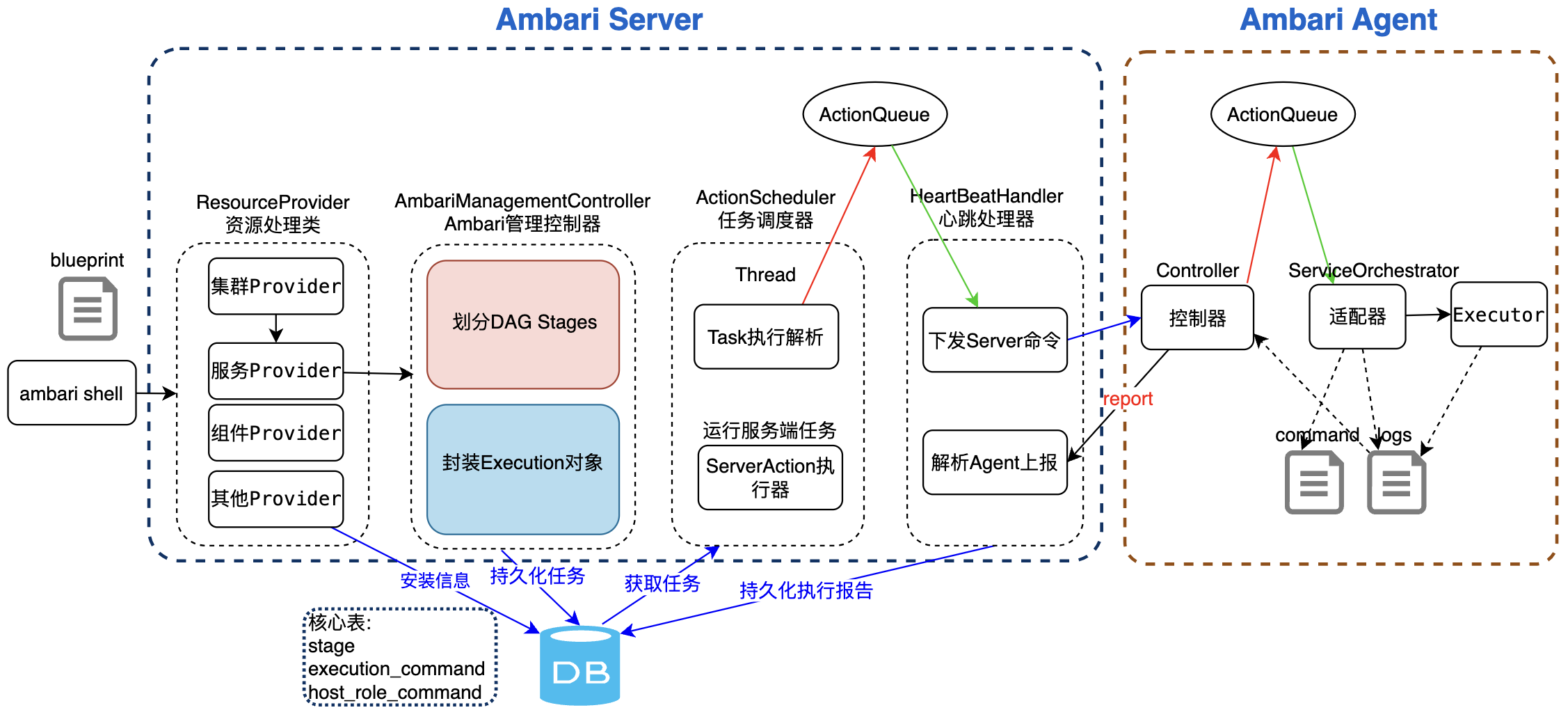
Ambari部署架构图,主要包括三个组件:
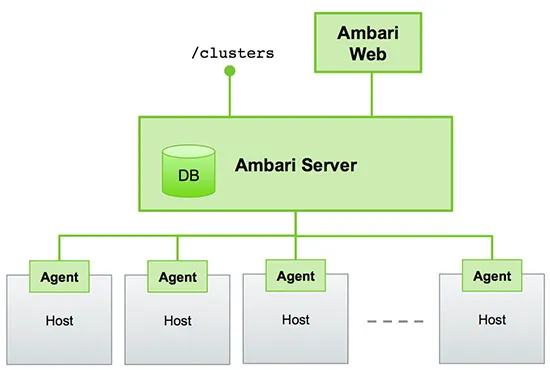
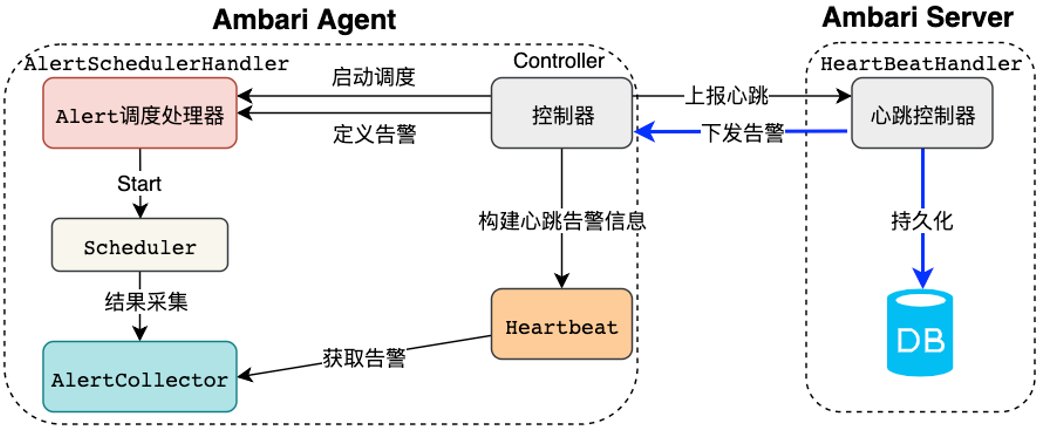
Amabri实现交互图,主要展示Ambari Server与各组件之间的交互处理:
Ambari 状态管理维护流程图:基于FSM(有限状态机)维护状态管理,并持久化到DB中
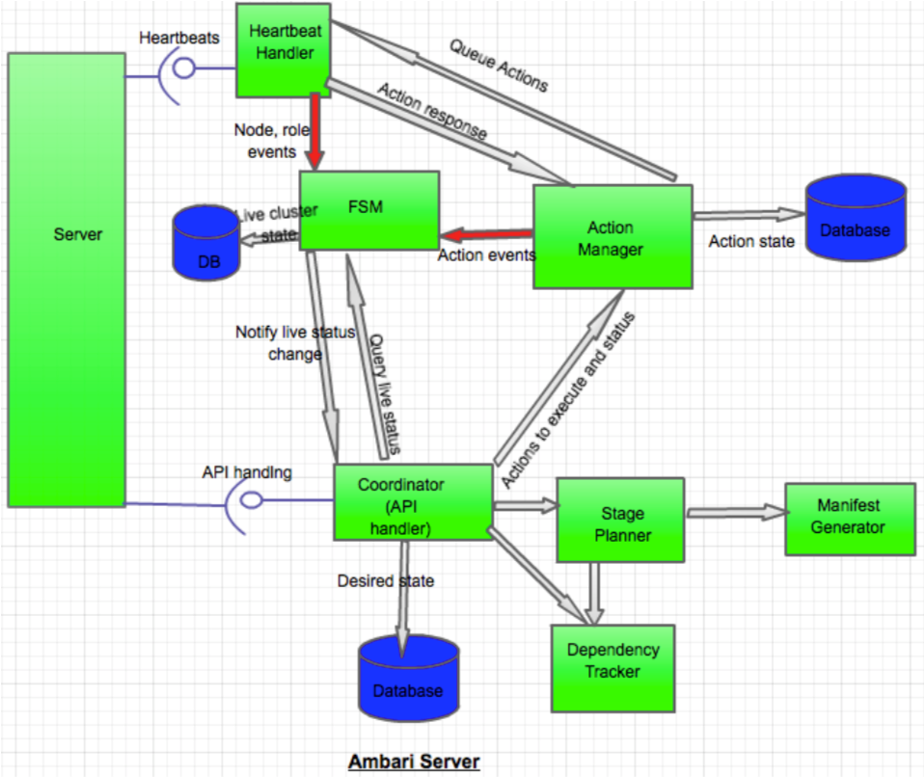
Ambari 任务管理、下发执行流程:

资源是Ambari集群管理的最核心概念,Ambari将管理的对象抽象为资源Resource实例,定义集群的资源分为:
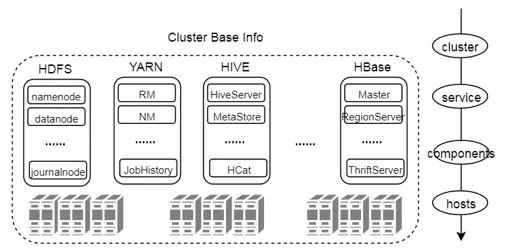
资源之间的关系相互关系:
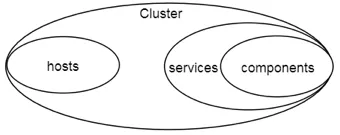
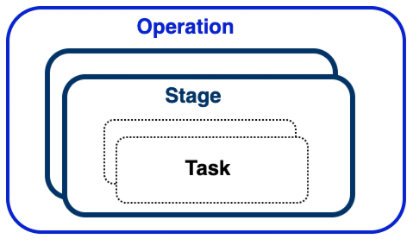
Ambari的操作行为可以拆解为不同粒度的表示,分别如下:
对应逻辑关系:一个Operation行为,会划分为多个Stage,同个Stage里面的任务是互相不依赖的,每个Stage根据对应的资源信息生成Task任务,一个Stage可以生成多个Task下发到各个Node主机执行。
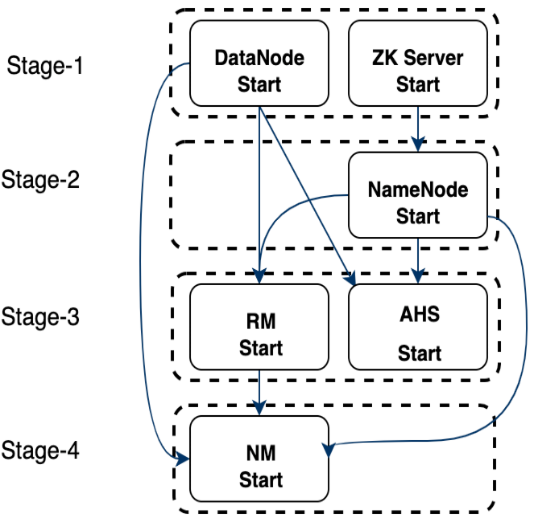
如图展示:HDFS、YARN启动Stage划分,划分为4个Stage,同个Stage执行不依赖,Stage之间具有单向依赖。
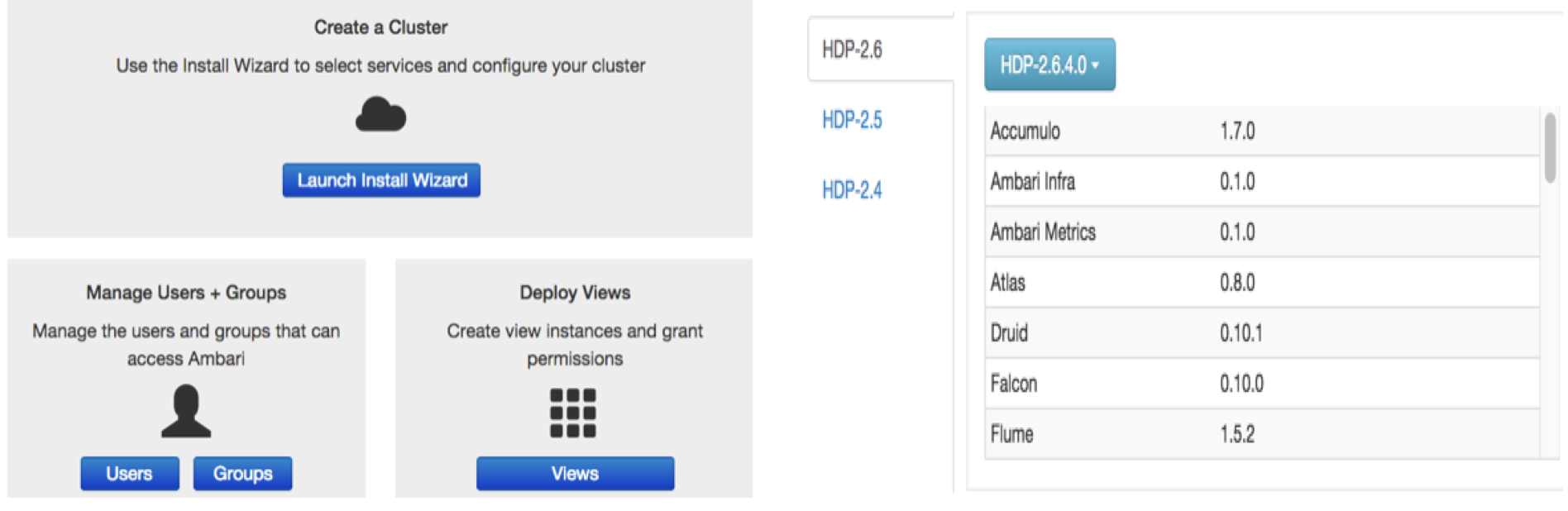
Ambari实现大数据组件安装步骤的流程主要包括如下:
图示:2.启动Web界面;5.选择版本
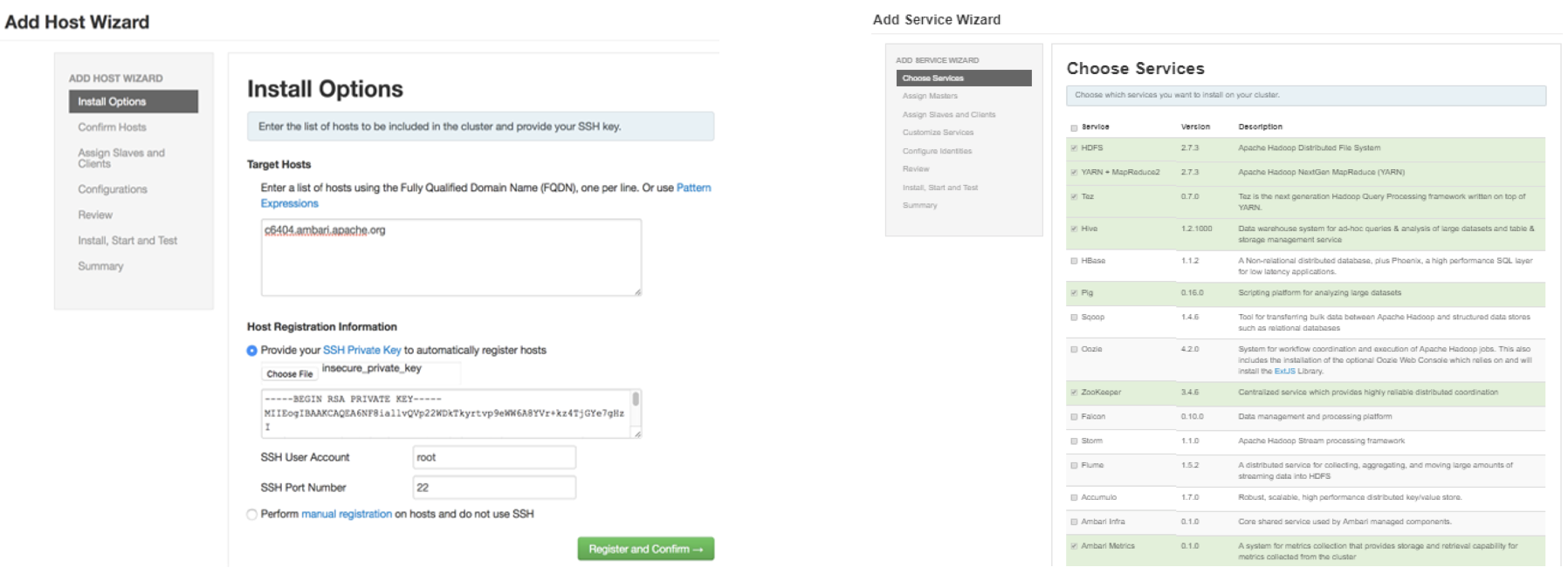
图示:6.配置主机;7.选择服务
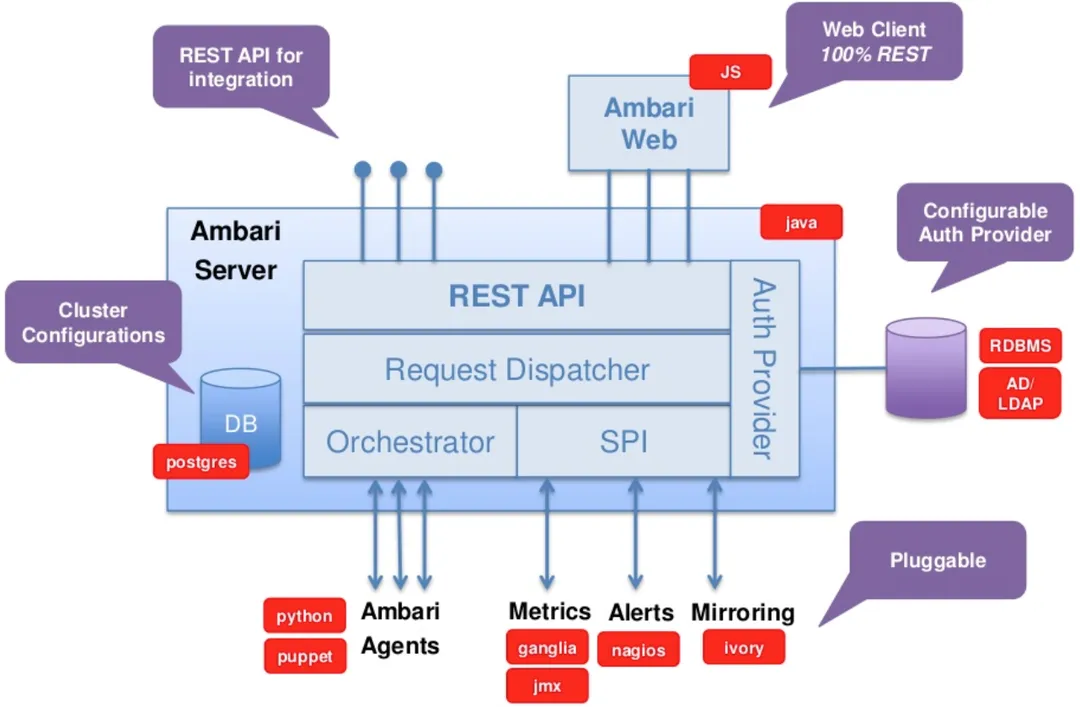
Ambari Request执行流程:核心在于AmbariManagerController 管理控制器
基于Ambari做二次开发的一个常用扩展是:扩展Ambari可部署管理的服务组件,主要基于扩展元数据文件实现。
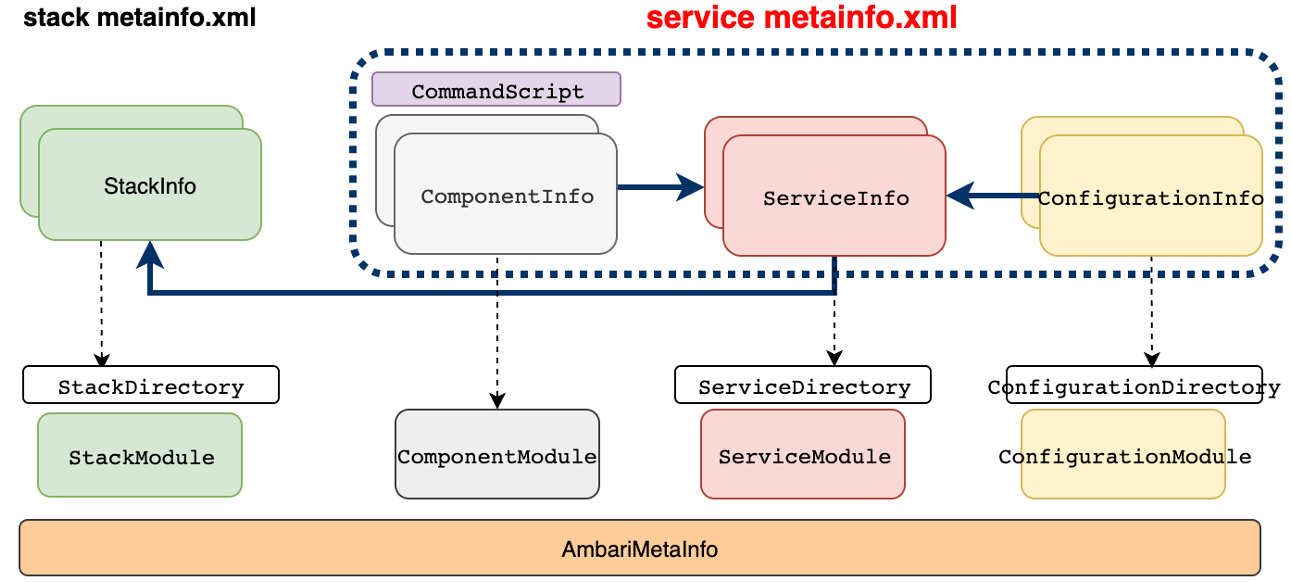
metainfo.xml 元数据文件描述Service、及对应Component、Configuration信息。

service/components:一个服务可对应多个组件
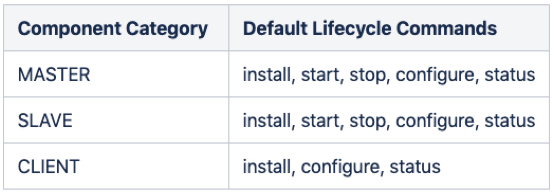
Scripts:定义组件全生命周期的执行脚本,每个脚本都需要继承Script类,脚本会根据OS变化
定义示例如下:
import?sys
from?resource_management?import?Script
class?Master(Script):
??def?install(self, env):
????print?'Install the Sample Srv Master';
??def?stop(self, env):
????print?'Stop the Sample Srv Master';
??def?start(self, env):
????print?'Start the Sample Srv Master';
??def?status(self, env):
????print?'Status of the Sample Srv Master';
??def?configure(self, env):
????print?'Configure the Sample Srv Master';
if?__name__?==?"__main__":
??Master().execute()params.py:用于配置文件管理,声明脚本、模板文件参数信息,解析command-{id}.json 文件,常用配置模板项
default('/configurations/{name}/{property_key}','{default}’)
config[configurations][{name}][{property_key}]Ambari基于Ambari Agent追踪的告警操作
创建方式:
调度方式:
告警方式:支持界面&API创建,EMAIL和SNMP方式
Ambari内置AMS(Ambari Metrics System)、采集、汇总Hadoop和机器系统指标。服务通过metrics.json 定义需要被AMS采集的指标信息。指标数据存储支持嵌入式、分布式(HBase)存储。

基于Ambari进行二次开发,经常需要对REST API进行改造和扩展,因此下文将针对REST API相关内容进行详述。
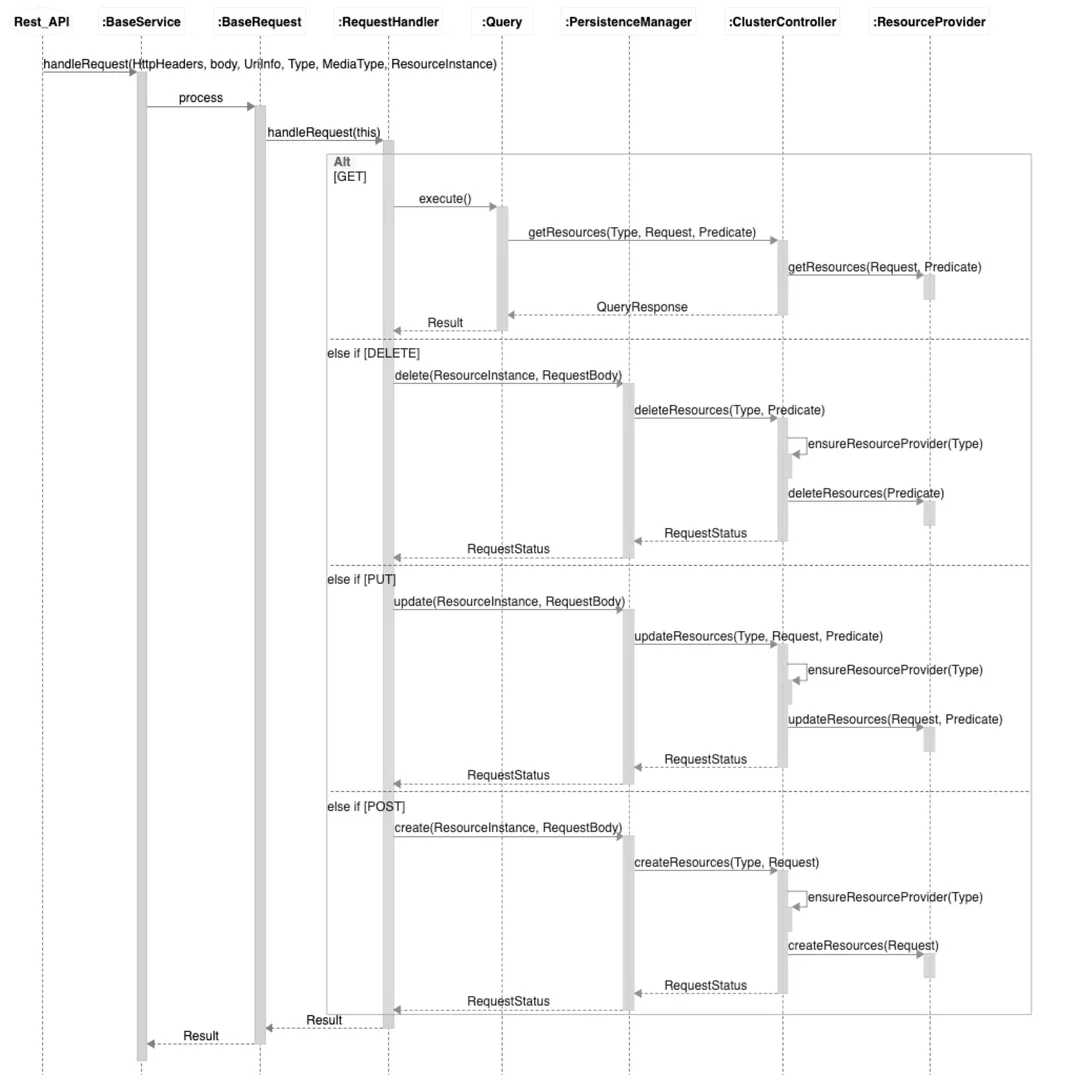
Ambari的Rest API基于框架Jersey实现,封装了各类型(GET/DELETE/PUT/Create)的调用流程,如下是调用的时序图。从时序图中我们可以得出Ambari对集群的操作主要是基于资源实现的,资源类型和资源操作分别通过:Resource.Type和ResourceProvider实现。
Rest API的请求最终由具体的ResourceProvider实现:
METHOD | 方法 | 描述 |
|---|---|---|
GET | ResourceProvider#getResources | 根据查询条件获取资源 |
DELETE | ResourceProvider#deleteResources | 根据过滤条件删除资源 |
PUT | ResourceProvider#updateResources | 更新资源的指定属性 |
POST | ResourceProvider#createResources | 根据请求参数创建对应资源 |
常用的Type类型和Provider如下:
Resource.Type | ResourceProvider | 描述 |
|---|---|---|
Blueprint | BlueprintResourceProvider | 部署规划蓝图 |
Cluster | ClusterResourceProvider | 集群 |
Service | ServiceResourceProvider | 服务 |
Host | HostResourceProvider | 主机 |
Component | ComponentResourceProvider | 组件 |
HostComponent | HostComponentResourceProvider | 主机组件 |
Configuration | ConfigurationResourceProvider | 配置 |
Request | RequestResourceProvider | 请求Rest,客户端向服务端发送的请求 |
Stack | StackResourceProvider | Stack安装版本栈 |
Alert | AlertResourceProvider | 告警 |
调用Ambari API时需要设置对应的用户登录认证信息,如用户名为admin,密码为123456。使用curl命令的示例如下:
export AMBARI_USER = admin
export AMBARI_PASSWD = 123456
export AMBARI_HOST = 10.0.0.1
export CLUSTER_NAME = tdw
export SERVICE = HIVE
export COMPONENT = HIVE_SERVER
export COMPONENT_HOST = 10.0.0.2GET获取集群下HIVE服务信息:
curl -u $AMBARI_USER:$AMBARI_PASSWD -H 'X-Requested-By: ambari' -X GET "http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER_NAME/services/$SERVICE"DELETE 删除10.0.0.2机器下的HIVE Server组件:
curl -u $AMBARI_USER:$AMBARI_PASSWD -H "X-Requested-By: ambari" -X PUT -d '{"RequestInfo":{"context":"Stop All Components"},"Body":{"ServiceComponentInfo":{"state":"INSTALLED"}}}' "http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER_NAME/services/$SERVICE/components/$COMPONENT"PUT 停止HIVE Server组件
curl -u $AMBARI_USER:$AMBARI_PASSWD -H 'X-Requested-By: ambari' -X PUT -d '{"RequestInfo":{"context":"Stop Service"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' "http://$AMBARI_HOST:8080/api/v1/clusters/$CLUSTER_NAME/services/$SERVICE/components/$COMPONENT"以下是请求中可以使用的资源属性汇总:
1. 集群Cluster
属性 | 描述 |
|---|---|
Clusters/cluster_id | The unique cluster id |
Clusters/cluster_name | The cluster name |
Clusters/version | The HDP stack version |
Clusters/desired_configs | The desired configurations |
2. 服务Service
属性 | 描述 |
|---|---|
ServiceInfo/service_name | The service name |
ServiceInfo/cluster_name | The parent cluster name |
ServiceInfo/state | The current state of the service |
ServiceInfo/desired_configs | The desired configurations |
3. 组件Component
属性 | 描述 |
|---|---|
ServiceComponentInfo/service_name | The name of the parent service |
ServiceComponentInfo/component_name | The component name |
ServiceComponentInfo/cluster_name | The name of the parent cluster |
ServiceComponentInfo/description | The component description |
ServiceComponentInfo/desired_configs | The desired configurations |
4. 主机Host
属性 | 描述 |
|---|---|
Hosts/host_name | The host name |
Hosts/cluster_name | The name of the parent cluster |
Hosts/ip | The host ip address |
Hosts/total_mem | The total memory available on the host |
Hosts/cpu_count | The cpu count of the host |
Hosts/os_arch | The OS architechture of the host (e.g. x86_64) |
Hosts/os_type | The OS type of the host (e.g. centos6) |
Hosts/rack_info | The rack info of the host |
Hosts/last_heartbeat_time | The time of the last heartbeat from the host in milliseconds since Unix epoch |
Hosts/last_agent_env | Environment information from the host |
Hosts/last_registration_time | The time of the last registration of the host in milliseconds since Unix epoc |
Hosts/disk_info | The host disk information |
Hosts/host_status | The host status (UNKNOWN, HEALTHY, UNHEALTHY) |
Hosts/host_state | The host state |
Hosts/desired_configs | The desired configurations |
4. 主机组件HostComponent
属性 | 描述 |
|---|---|
HostRoles/role_id | The host component id |
HostRoles/cluster_name | The name of the parent cluster |
HostRoles/host_name | The name of the parent host |
HostRoles/component_name | The name of the parent component |
HostRoles/state | The state of the host component |
HostRoles/actual_configs | The actual configuration |
HostRoles/desired_configs | The desired configuration |
HostRoles/stack_id | The stack id (e.g. HDP-1.3.0) |
1. 获取stack的服务栈信息
{stack} 部署安装栈,如hdp{version} 安装的版本GET /api/v1/stacks/{stack}/versions/{version}/services?fields=StackServices/*,components/StackServiceComponents/*,configurations/*2. 获取已安装的服务列表
{clusterName} 是对应的操作的集群名称GET /api/v1/clusters/{clusterName}/services?fields=ServiceInfo/service_name&minimal_response=true3. 启动/停止所有服务
text/plain/api/v1/clusters/tdw/services?ServiceInfo/service_name.in(FLINK,MAPREDUCE2)PUT /api/v1/clusters/{clusterName}/services4. 根据机器启动/停止对应的服务
PUT /api/v1/clusters/{clusterName}/hosts/{hostname}/host_components5. 重启服务操作
text/plainPOST /api/v1/clusters/{clustername}/requests6. 启动|停止|卸载服务操作
PUT /api/v1/clusters/{clustername}/services/{servicename}text/plain7. 开启|关闭某机器组件的维护模式
PUT /api/v1/clusters/{clustername}/services/{servicename}备注:
text/plain8. 启动|停止某机器的组件
PUT /api/v1/clusters/{clustername}/hosts/{hostname}/host_components/{componentname}text/plain9. 重启机器组件操作
POST /api/v1/clusters/{clustername}/requeststext/plain10. 开启|关闭某机器组件的维护模式
PUT /api/v1/clusters/{clustername}/hosts/{hostname}/host_components/{componentname}text/plain11. 修改服务配置信息
PUT /api/v1/clusters/{clustername}text/plain12. 新增服务
POST /api/v1/clusters/{clustername}/services?ServiceInfo/service_name={servicename}application/x-www-form-urlencoded13. 配置服务关联的主机
POST /api/v1/clusters/{clustername}/hostsapplication/x-www-form-urlencoded14. 部署服务
PUT /api/v1/clusters/{clustername}/services?ServiceInfo/service_name.in({servicename})text/plain更多接口可参考:Ambari Rest API官方文档
在大数据平台搭建过程中,如果只针对公司内部场景,所有运维操作可由专门的运维同学管理,且面对的场景比较单一,可以不必考虑基于Ambari集群管理系统搭建环境。但在商业化过程中,需要将大数据平台的搭建过程流程化、可管理化、对用户友好化。因此最早一批的商业化大数据平台很多会选择Ambari进行集群管理,例如,腾讯大数据套件TBDS。目前,由于容器化的普及、存算分离架构演进,Ambari系统由于整体过重以及多集群、容器化等功能支持较弱,可能已不再是最优选择,但其设计思想和实现路径是值得借鉴的。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。


