


今年OFC上,有多个报告以及workshop涉及到AI/ML热潮下对光互连的需求,这里简单整理下相关信息,供大家参考。
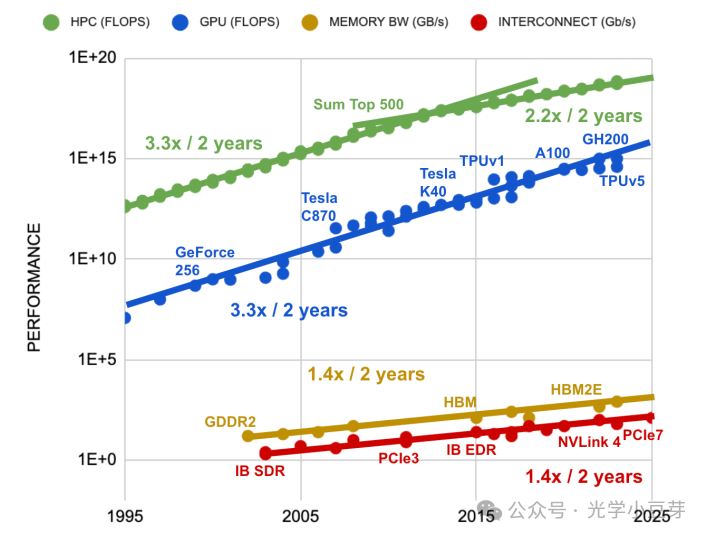
计算芯片的性能大约每两年提高3.3倍,HBM芯片的带宽每两年提高1.4倍,而互联带宽(PCIe,IB,NVLink等)每两年提高1.4倍,如下图所示。可以看出计算性能与互联带宽的发展速度存在较大的差异。3.3/1.4=2.4,需要将互联的数目增加2.4倍,才能弥补两者间的发展速度差异。
与此同时,在AIGC的驱动下,AI算力的需求呈指数级增长,每2-3个月翻一番,两年内增加了100倍多,如下图所示。
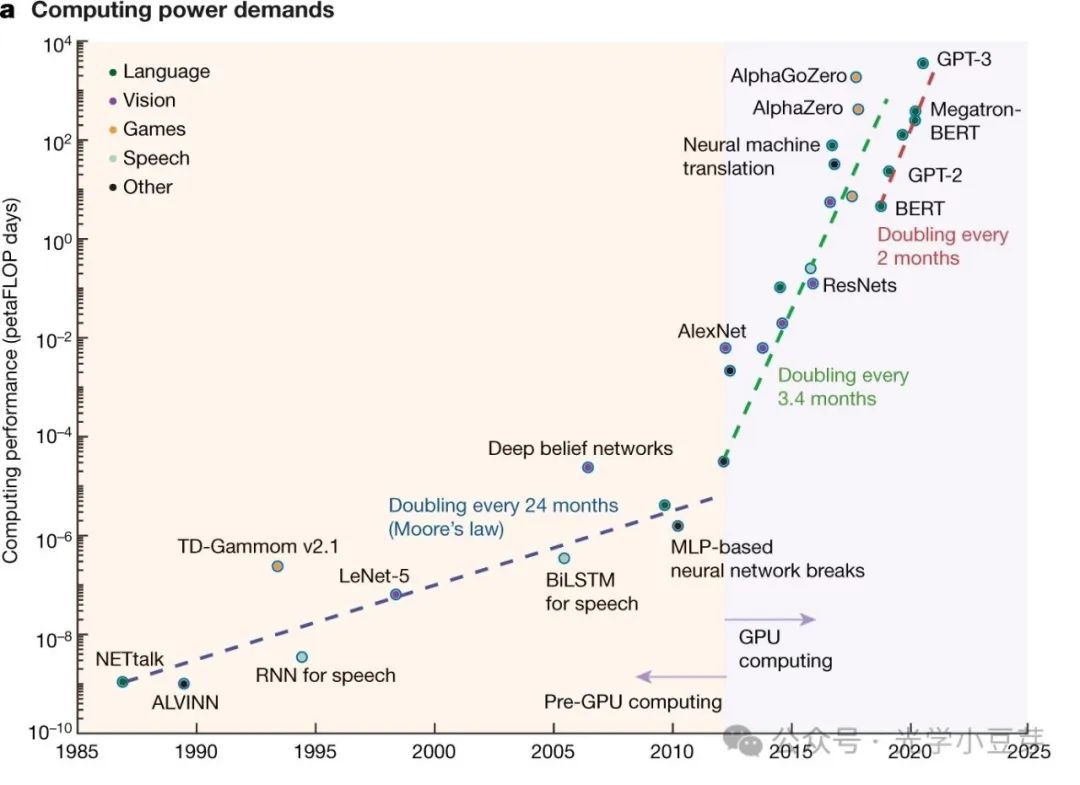
(图片来自https://www.nature.com/articles/s41586-021-04362-w)
简单计算下,100倍的算力增长需求,计算芯片的性能提升3.3倍,因此计算芯片的数目需要增加30倍多。再考虑到先前的2.4倍差异,每两年的互联总数需要提升70多倍。如何解决这一问题?一方面增加光模块的带宽。它的发展趋势是每四年带宽提升一倍,包括提升单通道速率、增加通道数、使用更多波长等方法。另一方面,增加光模块的总数目,提升IO口的带宽密度,在有限空间内可以布置更多的接口。
再看另外一组数据,GPU-Memory之间的互联带宽为5TB/s, GPU间的电互联带宽为900GB/s,但是光模块的带宽为400Gb/s, 相差了100倍。如何有效地将海量数据从计算芯片内传输出来,成为当务之急。Optical IO技术成为重要的技术方向之一。

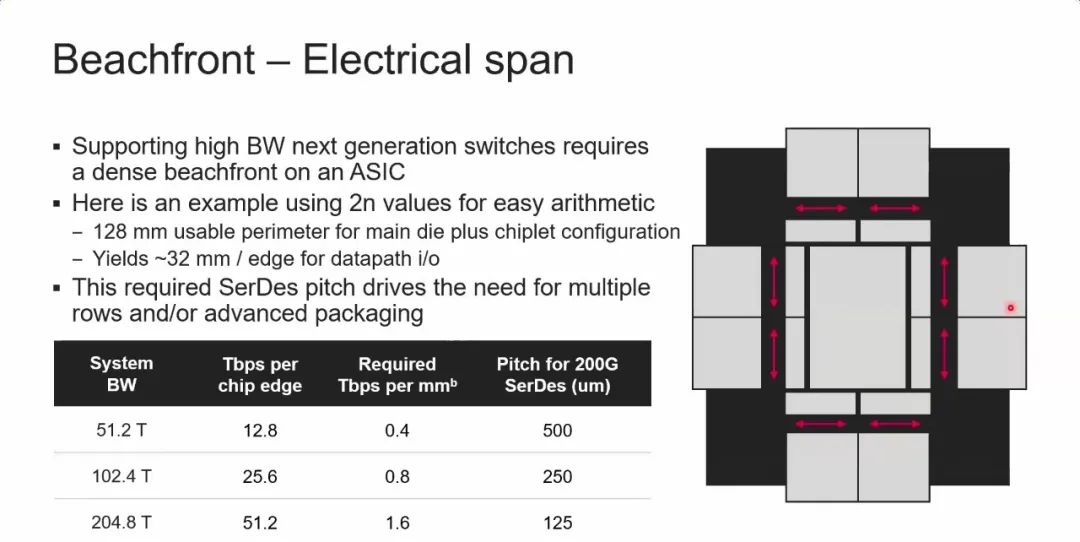
对于Switch芯片,假设其die的尺寸为32mm*32mm,可以估算出不同带宽下对应的带宽密度,如下表所示。51.2T/102.4T/204.8T带宽下对应的带宽密度分别为0.4/0.8/1.6 Tbps/mm。
与此同时,可以推算出采用CPO封装芯片方案的IO带宽密度。如果采用单个波长,一颗DFB激光器芯片支持4个通道,光口的通道间距为127um, 单通道速率为200Gbps, 对应的带宽密度约为0.7Tbps/mm。通过引入多波长、增加激光器功率、优化链路损耗等途径,可以进一步提高带宽密度,使之满足电芯片带宽提升的需求。

关于CPO在AI集群中的应用,分歧主要集中在CPO的可靠性、维护性、可测试性等问题。目前发布的CPO产品方案,大部分是将光引擎以socket的形式插入到substrate上。在封装前,先对光引擎进行测试,筛选出性能符合要求的光引擎,以此来提高良率。另外CPO产品需要与ASIC芯片公司深度合作,这也是为何目前CPO产品主要是交换机公司自己推出或者深度绑定,包括Broadcom、Marvell、Cisco等。

在AI集群中,可以通过光开关OCS(optical circuit switch)引入新型的网络架构,如下图所示。可以利用光开关连接GPU板卡, 灵活地切换网络拓扑结构,也可以连接不同机架间的硬件资源,形成新型的算力网络,提升硬件利用效率。随着AI集群中大量GPU的部署,需要实现GPU间高效率的信号互联,通过scale out横向扩展互联的方式来提升算力,否则互联会大大制约系统的性能,无法有效发挥出GPU集群的算力。

伴随着AI集群的快速发展,光互联迎来了新的需求与挑战,但是底层的要求是非常确定的——低功耗、高带宽、低延迟的信号互联。谁能抓住机遇,引领风骚?让我们拭目以待!
文章中如果有任何错误和不严谨之处,还望大家不吝指出,欢迎大家留言讨论。目前三个微信群都已经满员,小豆芽已经新开了微信讨论群4,有需要技术讨论或者商务咨询合作的朋友可以直接添加我的个人微信photon_walker。


