


图解学习网站:https://xiaolincoding.com
大家好,我是小林。
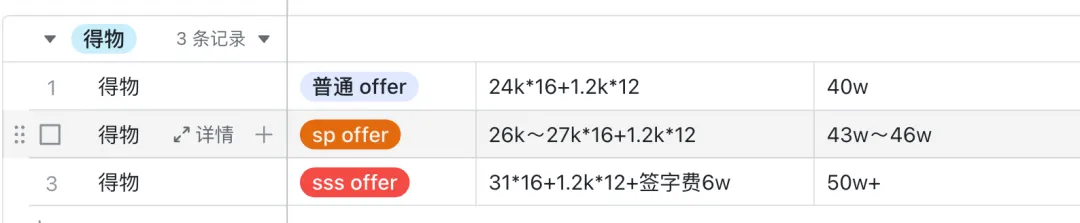
得物的校招薪资水平跟大厂一样,开的都挺高的,校招毕业年薪 40w 起步,最高档 offer 都到 50w 级别了。不过,得物工作强度会比较高,所以才开了比较有竞争力的薪资。
很多同学就好奇得物的面试难度如何?那么,今天跟大家分享得物的后端面经,其实跟面试难度大厂差不多,围绕八股+项目+算法这三个方面来考察。

考察的知识点:
三次握手

四次挥手
具体过程:
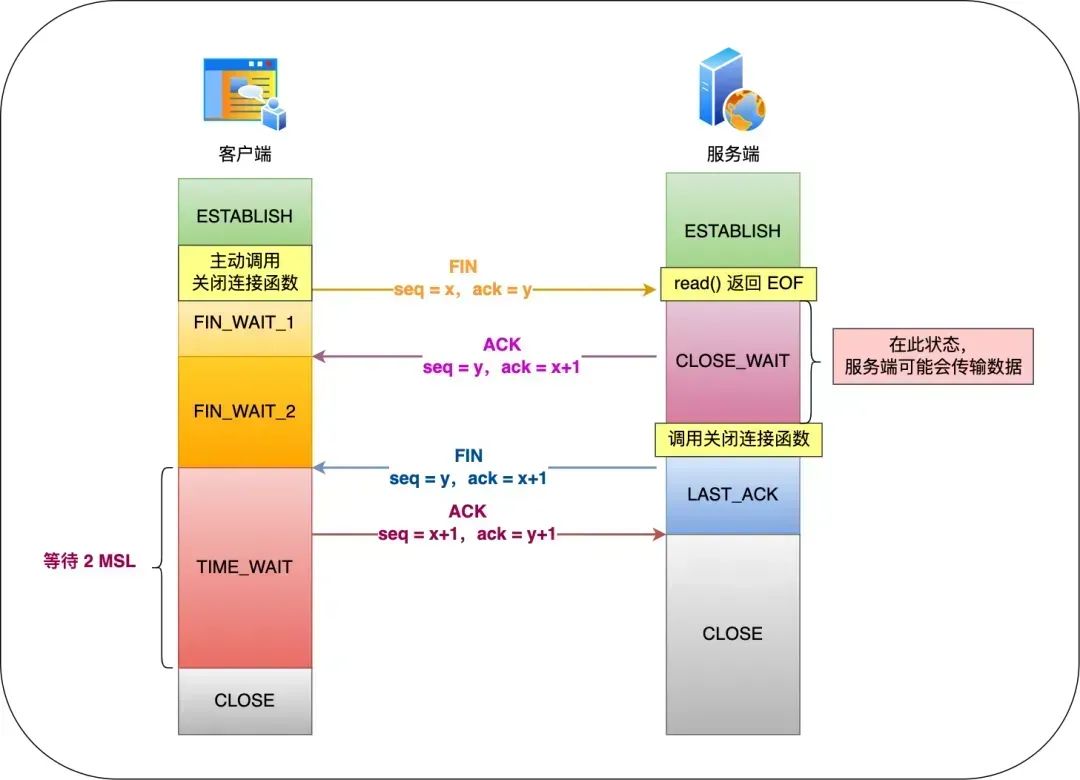
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。因为 TCP 报文基于是 IP 协议的,而 IP 头中有一个 TTL 字段,是 IP 数据报可以经过的最大路由数,每经过一个处理他的路由器此值就减 1,当此值为 0 则数据报将被丢弃,同时发送 ICMP 报文通知源主机。
MSL 与 TTL 的区别:MSL 的单位是时间,而 TTL 是经过路由跳数。所以 MSL 应该要大于等于 TTL 消耗为 0 的时间,以确保报文已被自然消亡。TTL 的值一般是 64,Linux 将 MSL 设置为 30 秒,意味着 Linux 认为数据报文经过 64 个路由器的时间不会超过 30 秒,如果超过了,就认为报文已经消失在网络中了。
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是:网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。
比如,如果被动关闭方没有收到断开连接的最后的 ACK 报文,就会触发超时重发 FIN 报文,另一方接收到 FIN 后,会重发 ACK 给被动关闭方, 一来一去正好 2 个 MSL。
可以看到 2MSL时长 这其实是相当于至少允许报文丢失一次。比如,若 ACK 在一个 MSL 内丢失,这样被动方重发的 FIN 会在第 2 个 MSL 内到达,TIME_WAIT 状态的连接可以应对。
为什么不是 4 或者 8 MSL 的时长呢?你可以想象一个丢包率达到百分之一的糟糕网络,连续两次丢包的概率只有万分之一,这个概率实在是太小了,忽略它比解决它更具性价比。
2MSL 的时间是从客户端接收到 FIN 后发送 ACK 开始计时的。如果在 TIME-WAIT 时间内,因为客户端的 ACK 没有传输到服务端,客户端又接收到了服务端重发的 FIN 报文,那么 2MSL 时间将重新计时。
在 Linux 系统里 2MSL 默认是 60 秒,那么一个 MSL 也就是 30 秒。Linux 系统停留在 TIME_WAIT 的时间为固定的 60 秒。
其定义在 Linux 内核代码里的名称为 TCP_TIMEWAIT_LEN:
#define TCP_TIMEWAIT_LEN (60*HZ) /* how long to wait to destroy TIME-WAIT
state, about 60 seconds */
如果要修改 TIME_WAIT 的时间长度,只能修改 Linux 内核代码里 TCP_TIMEWAIT_LEN 的值,并重新编译 Linux 内核。
传统的 TLS 握手基本都是使用 RSA 算法来实现密钥交换的,在将 TLS 证书部署服务端时,证书文件其实就是服务端的公钥,会在 TLS 握手阶段传递给客户端,而服务端的私钥则一直留在服务端,一定要确保私钥不能被窃取。
在 RSA 密钥协商算法中,客户端会生成随机密钥,并使用服务端的公钥加密后再传给服务端。根据非对称加密算法,公钥加密的消息仅能通过私钥解密,这样服务端解密后,双方就得到了相同的密钥,再用它加密应用消息。
我用 Wireshark 工具抓了用 RSA 密钥交换的 TLS 握手过程,你可以从下面看到,一共经历了四次握手:
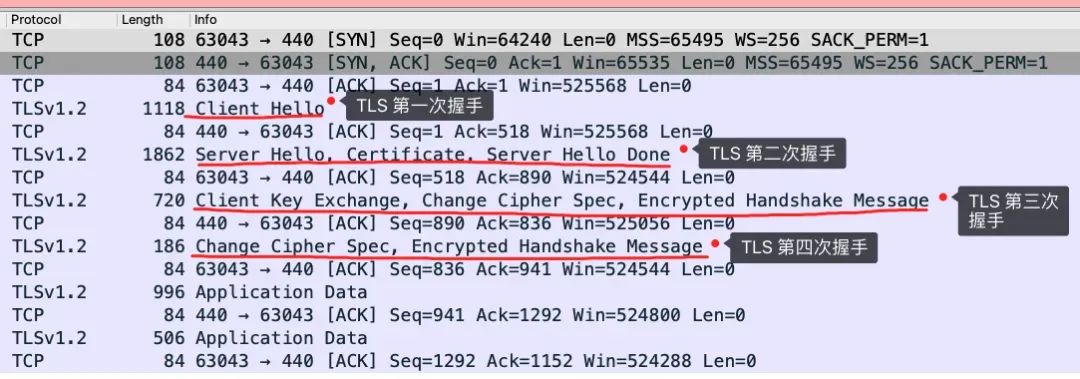

TLS 第一次握手
首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。在这一步,客户端主要向服务器发送以下信息:
TLS 第二次握手
服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
TLS 第三次握手
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
上面第一项的随机数是整个握手阶段的第三个随机数,会发给服务端,所以这个随机数客户端和服务端都是一样的。
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
TLS 第四次握手
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。
然后,向客户端发送最后的信息:
至此,整个 TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」加密内容。
Redis 单线程指的是「接收客户端请求->解析请求 ->进行数据读写等操作->发送数据给客户端」这个过程是由一个线程(主线程)来完成的,这也是我们常说 Redis 是单线程的原因。但是,Redis 程序并不是单线程的,Redis 在启动的时候,是会启动后台线程(BIO)的:
Redis 6.0 版本之前的单线模式如下图:
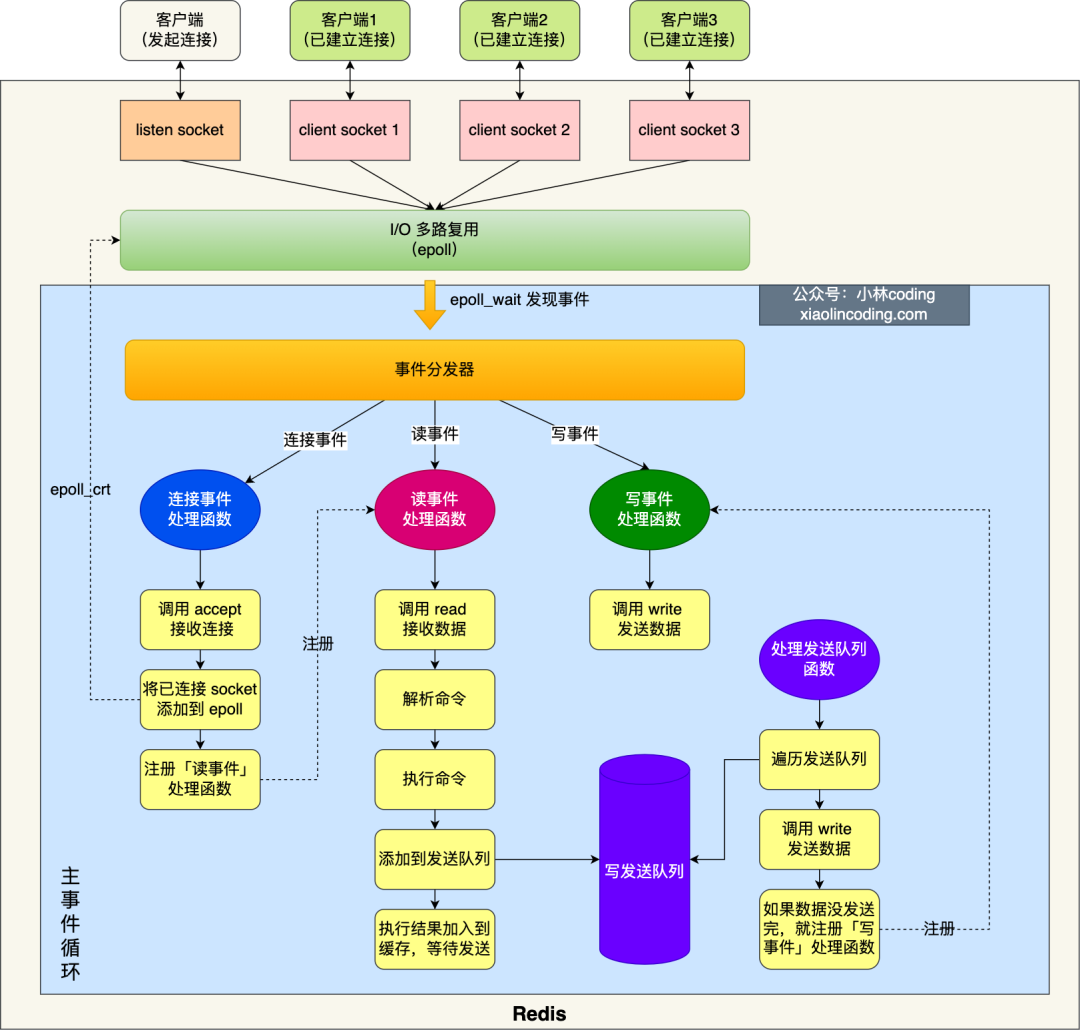
图中的蓝色部分是一个事件循环,是由主线程负责的,可以看到网络 I/O 和命令处理都是单线程。Redis 初始化的时候,会做下面这几件事情:
初始化完后,主线程就进入到一个事件循环函数,主要会做以下事情:
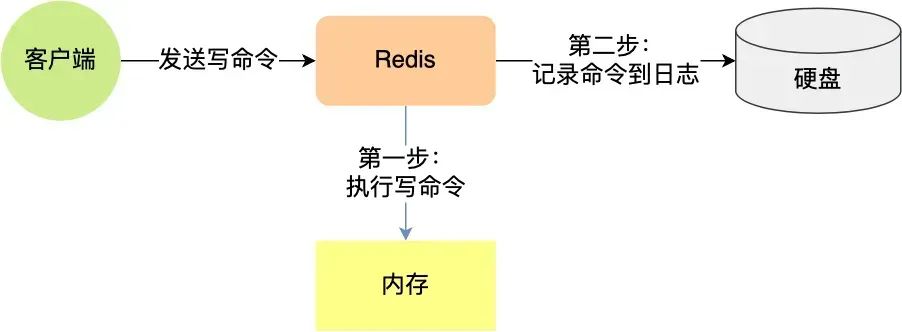
Redis 的读写操作都是在内存中,所以 Redis 性能才会高,但是当 Redis 重启后,内存中的数据就会丢失,那为了保证内存中的数据不会丢失,Redis 实现了数据持久化的机制,这个机制会把数据存储到磁盘,这样在 Redis 重启就能够从磁盘中恢复原有的数据。Redis 共有三种数据持久化的方式:
AOF 日志是如何实现的?
Redis 在执行完一条写操作命令后,就会把该命令以追加的方式写入到一个文件里,然后 Redis 重启时,会读取该文件记录的命令,然后逐一执行命令的方式来进行数据恢复。
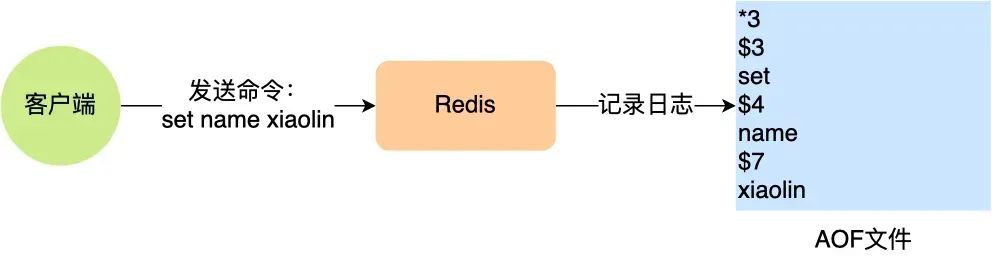
我这里以「_set name xiaolin_」命令作为例子,Redis 执行了这条命令后,记录在 AOF 日志里的内容如下图:
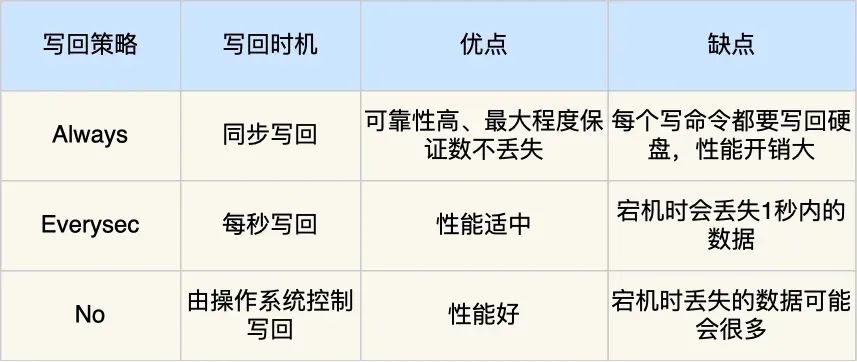
Redis 提供了 3 种写回硬盘的策略, 在 Redis.conf 配置文件中的 appendfsync 配置项可以有以下 3 种参数可填:
我也把这 3 个写回策略的优缺点总结成了一张表格:
RDB 快照是如何实现的呢?
因为 AOF 日志记录的是操作命令,不是实际的数据,所以用 AOF 方法做故障恢复时,需要全量把日志都执行一遍,一旦 AOF 日志非常多,势必会造成 Redis 的恢复操作缓慢。
为了解决这个问题,Redis 增加了 RDB 快照。所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息就记录到了一张照片。所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据。
因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 高些,因为直接将 RDB 文件读入内存就可以,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据。
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave,他们的区别就在于是否在「主线程」里执行:
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
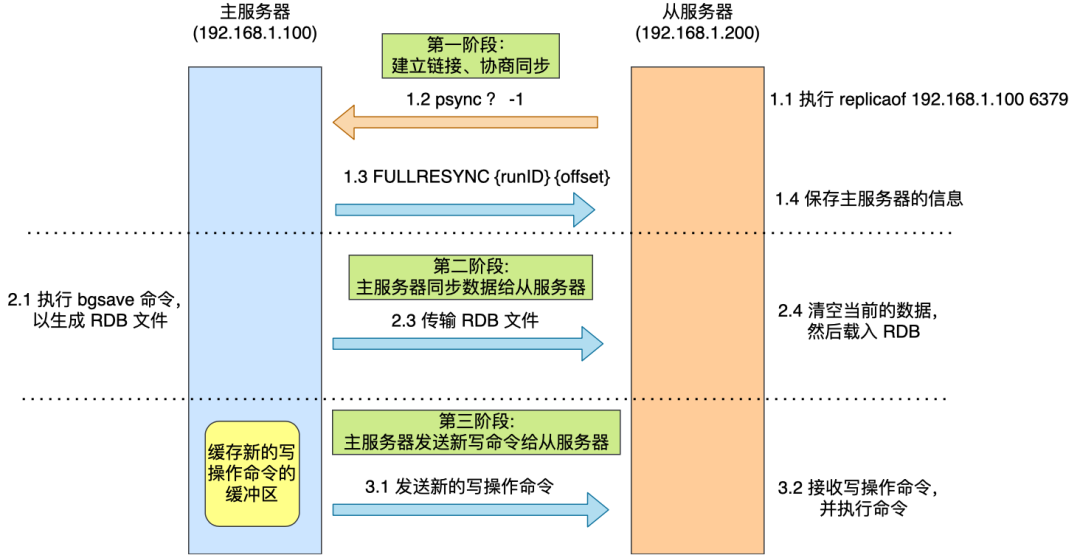
主从服务器间的第一次同步的过程可分为三个阶段:
为了让你更清楚了解这三个阶段,我画了一张图。
接下来,我在具体介绍每一个阶段都做了什么。
第一阶段:建立链接、协商同步
执行了 replicaof 命令后,从服务器就会给主服务器发送 psync 命令,表示要进行数据同步。
psync 命令包含两个参数,分别是主服务器的 runID 和复制进度 offset。
主服务器收到 psync 命令后,会用 FULLRESYNC 作为响应命令返回给对方。
并且这个响应命令会带上两个参数:主服务器的 runID 和主服务器目前的复制进度 offset。从服务器收到响应后,会记录这两个值。
FULLRESYNC 响应命令的意图是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
所以,第一阶段的工作时为了全量复制做准备。
那具体怎么全量同步呀呢?我们可以往下看第二阶段。
第二阶段:主服务器同步数据给从服务器
接着,主服务器会执行 bgsave 命令来生成 RDB 文件,然后把文件发送给从服务器。
从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。
这里有一点要注意,主服务器生成 RDB 这个过程是不会阻塞主线程的,因为 bgsave 命令是产生了一个子进程来做生成 RDB 文件的工作,是异步工作的,这样 Redis 依然可以正常处理命令。
但是,这期间的写操作命令并没有记录到刚刚生成的 RDB 文件中,这时主从服务器间的数据就不一致了。
那么为了保证主从服务器的数据一致性,主服务器在下面这三个时间间隙中将收到的写操作命令,写入到 replication buffer 缓冲区里:
第三阶段:主服务器发送新写操作命令给从服务器
在主服务器生成的 RDB 文件发送完,从服务器收到 RDB 文件后,丢弃所有旧数据,将 RDB 数据载入到内存。完成 RDB 的载入后,会回复一个确认消息给主服务器。
接着,主服务器将 replication buffer 缓冲区里所记录的写操作命令发送给从服务器,从服务器执行来自主服务器 replication buffer 缓冲区里发来的命令,这时主从服务器的数据就一致了。
至此,主从服务器的第一次同步的工作就完成了。
布隆过滤器由「初始值都为 0 的位图数组」和「 N 个哈希函数」两部分组成。当我们在写入数据库数据时,在布隆过滤器里做个标记,这样下次查询数据是否在数据库时,只需要查询布隆过滤器,如果查询到数据没有被标记,说明不在数据库中。
布隆过滤器会通过 3 个操作完成标记:
举个例子,假设有一个位图数组长度为 8,哈希函数 3 个的布隆过滤器。
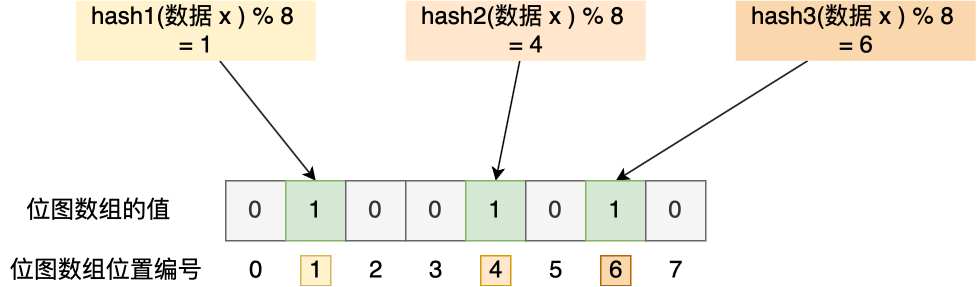
在数据库写入数据 x 后,把数据 x 标记在布隆过滤器时,数据 x 会被 3 个哈希函数分别计算出 3 个哈希值,然后在对这 3 个哈希值对 8 取模,假设取模的结果为 1、4、6,然后把位图数组的第 1、4、6 位置的值设置为 1。当应用要查询数据 x 是否数据库时,通过布隆过滤器只要查到位图数组的第 1、4、6 位置的值是否全为 1,只要有一个为 0,就认为数据 x 不在数据库中。
布隆过滤器由于是基于哈希函数实现查找的,高效查找的同时存在哈希冲突的可能性,比如数据 x 和数据 y 可能都落在第 1、4、6 位置,而事实上,可能数据库中并不存在数据 y,存在误判的情况。
所以,查询布隆过滤器说数据存在,并不一定证明数据库中存在这个数据,但是查询到数据不存在,数据库中一定就不存在这个数据。
Redis的ZSet支持分值为double类型,也是8字节,共 64 位,可以把score拆分成这样:
0(最高位不用)| 0000000 00000000 0000000(22bit表示分数)|0 00000000 00000000 00000000 00000000 00000000(41bit表示时间戳)
因为排序首先按分数排再按时间排,所以分数在高位,时间戳在低位,这样不管时间戳的值是多少,积分越大,64bit表示的数值就越大。
分数相同时候,时间要按升序排,也就是时间戳越早的,它的score的数值应该越大,所以我们不能单纯的使用41bit存储时间戳,而应该是存储一个随时间流逝而变小的数值。
由于排行榜都会有一个周期,如周榜是一周,月榜是一个月,所以我们使用41bit存储的是一个周期的结束时间yyy-MM-dd 23:59:59对应的时间戳与用户分数更新时间的时间戳的差值,这个值会随着时间的推移而变小,而且不会出现负数的情况,刚好能够达到目的。
在数据库层面解决
select * from goods for where goods_id=? for update
在事务中线程A通过select * from goods for where goods_id=#{id} for update语句给goods_id为#{id}的数据行上了锁。那么其他线程此时可以使用select语句读取数据,但是如果也使用select for update语句加锁,或者使用update,delete都会阻塞,直到线程A将事务提交(或者回滚),其他线程中的某个线程排在线程A后的线程才能获取到锁。
update goods set stock = stock - 1 where goods_id = ? and stock >0
这种通过数据库加锁来解决的方案,性能不是很好,在高并发的情况下,还可能存在因为获取不到数据库连接或者因为超时等待而报错。
利用分布式锁
同一个锁key,同一时间只能有一个客户端拿到锁,其他客户端会陷入无限的等待来尝试获取那个锁,只有获取到锁的客户端才能执行下面的业务逻辑。这种方案的缺点是同一个商品在多用户同时下单的情况下,会基于分布式锁串行化处理,导致没法同时处理同一个商品的大量下单的请求。
利用分布式锁+分段缓存
把数据分成很多个段,每个段是一个单独的锁,所以多个线程过来并发修改数据的时候,可以并发的修改不同段的数据 假设场景:假如你现在商品有100个库存,在redis存放5个库存key,形如:
key1=goods-01,value=20;
key2=goods-02,value=20;
key3=goods-03,value=20
用户下单时对用户id进行%5计算,看落在哪个redis的key上,就去取哪个,这样每次就能够处理5个进程请求 这种方案可以解决同一个商品在多用户同时下单的情况,但有个坑需要解决:当某段锁的库存不足,一定要实现自动释放锁然后换下一个分段库存再次尝试加锁处理,此种方案复杂比较高。
利用redis的incr、decr的原子性 + 异步队列
实现思路
update goods set stock = stock - 1 where goods_id = ? and stock >0
这种方案的缺点:由于是通过异步队列写入数据库中,可能存在数据不一致,其次引用多个组件复杂度比较高
可以使用 unlink 的方式来删除缓存,unlink 是异步删除数据,不会阻塞主线程


