



在机器学习和深度学习中,数据集的加载和处理是一个至关重要的步骤。PyTorch是一种流行的深度学习框架,它提供了强大的工具来加载、转换和管理数据集。在本篇博客中,我们将探讨如何使用PyTorch加载数据集,以便于后续的模型训练和评估。
在实战前,我们需要了解三个名词,Epoch、Batch-Size、Iteration 下面针对上面,我展开进行说明
总结一下: 一个Epoch包含多个Iterations,每个Iteration包含一个Batch Size的样本。 Batch Size决定了每次参数更新的规模,而Epoch表示整个数据集的一个完整训练周期。 训练时通常迭代多个Epochs,其中每个Epoch由多个Iterations组成,以逐渐优化模型的参数。 超参数的选择,如Epoch数量和Batch Size,会影响训练的速度和模型的性能,需要根据具体问题进行调整和优化。
在DataLoader中有一个参数是shuffle,这个参数是一个bool值的参数,如果设置为TRUE的话,表示打乱数据集
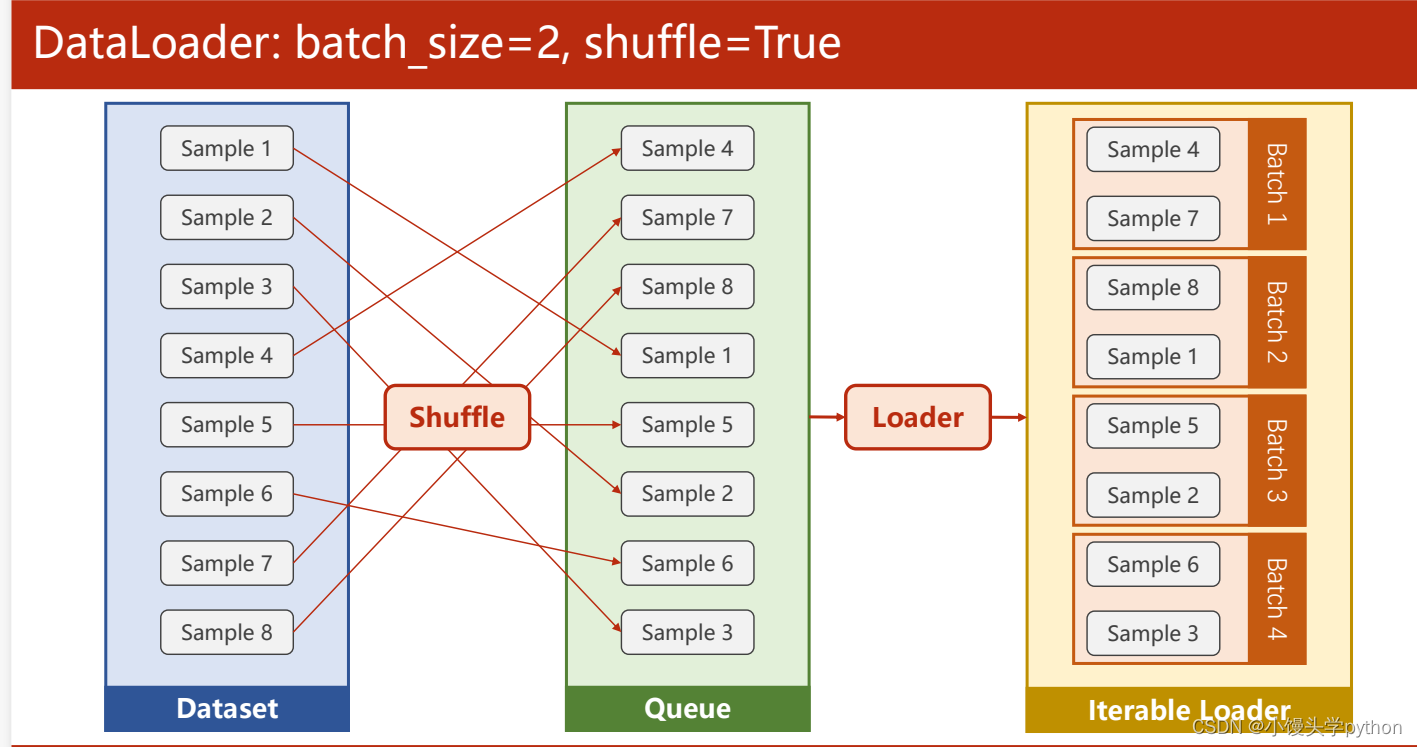
这里介绍一下DataLoader的参数
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
# 1. Prepare data
inputs, labels = data
# 2. Forward
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
# 3. Backward
optimizer.zero_grad()
loss.backward()
# 4. Update
optimizer.step()这段代码演示了一个基本的二分类问题的训练过程,其中神经网络模型用于预测糖尿病患者的标签(0表示非糖尿病,1表示糖尿病)。模型的训练是通过反向传播算法来更新模型参数以减小损失。在训练循环中,你可以观察损失值的变化,以了解模型的训练进展。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。

