



在机器学习和数据科学领域,混淆矩阵(Confusion Matrix)是一种重要的工具,用于评估分类模型的性能。虽然混淆矩阵在二分类问题中被广泛使用,但它同样适用于多分类问题。本文将深入探讨多分类混淆矩阵的概念、解读方法、应用场景以及提供一个实际示例来帮助您更好地理解和使用它。
混淆矩阵是一个用于可视化分类模型性能的表格,它将模型的预测结果与实际标签进行比较。对于多分类问题,混淆矩阵的结构可能会略有不同,但基本思想相同。
一个典型的多分类混淆矩阵如下所示:
Class 1 Class 2 Class 3 ... Class N
Class 1 TP11 TP12 TP13 TP1N
Class 2 TP21 TP22 TP23 TP2N
Class 3 TP31 TP32 TP33 TP3N
... ... ... ... ...
Class N TPN1 TPN2 TPN3 TPNN其中,每一行代表实际类别,每一列代表模型的预测类别。矩阵的对角线上的元素(TPii)表示模型正确预测的样本数,而非对角线元素则表示模型错误预测的样本数。
解读混淆矩阵
混淆矩阵为评估分类模型提供了丰富的信息,有助于分析模型的性能和调整模型的参数。以下是一些混淆矩阵的常见应用:
首先需要导一个手写数字识别的数据集并做好数据的准备,本节我们将用它做练习实践
from sklearn.datasets import load_digits
digits = load_digits()
X = digits.data
y = digits.target此外我们还需要导入如下的一些库
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix,recall_score,precision_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression接下来我们进行数据集的切割以及拟合训练集并进行预测
log_reg = LogisticRegression(max_iter=10000)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.8,random_state=666)
log_reg.fit(X_train,y_train)
log_reg.score(X_test,y_test)准确率可以看一眼

接下来我们根据逻辑回归好的模型进行预测
y_predict = log_reg.predict(X_test)并且将混淆矩阵打印出来
confusion_matrix(y_test,y_predict)运行结果如下

之后我们可以看一看精确率和召回率的值
precision_score(y_test,y_predict,average='micro')
recall_score(y_test,y_predict,average='macro')运行结果如下

接下来我们将混淆矩阵保存于cfm中,并绘制图像
cfm = confusion_matrix(y_test,y_predict)
plt.matshow(cfm) 运行结果如下
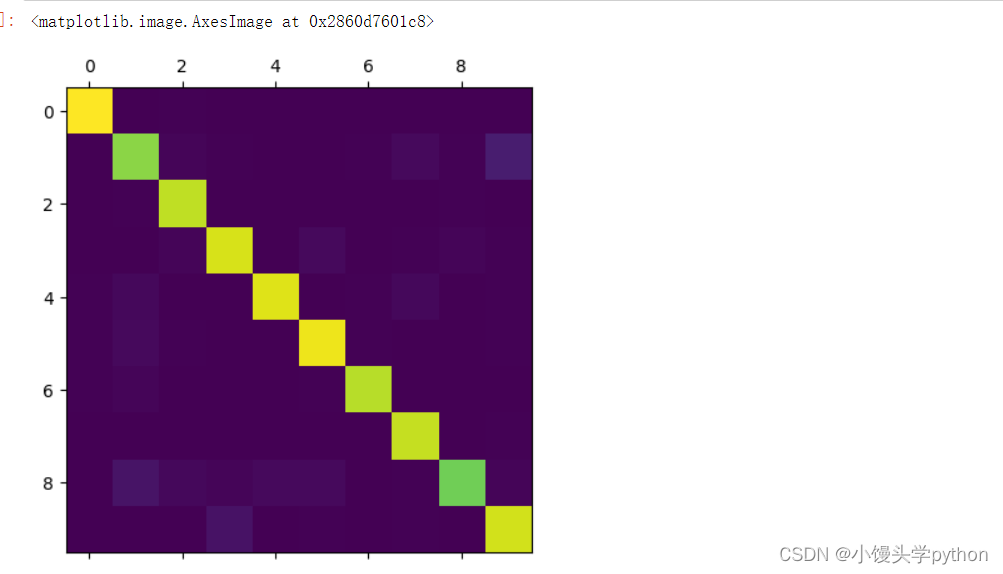
注意:越明亮的地方代表了错误的越多
我们可以将对角线置0
import numpy as np
row_sum = np.sum(cfm,axis=1)
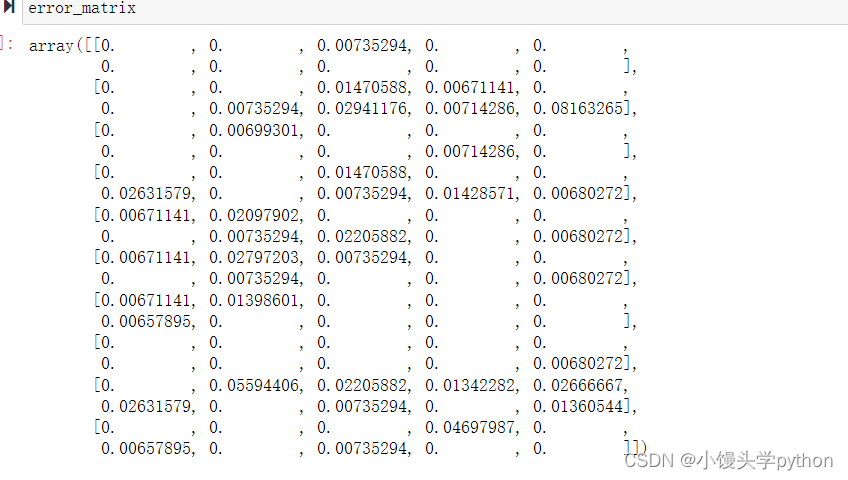
error_matrix = cfm/row_sum
np.fill_diagonal(error_matrix,0) # 对角线设置为0运行结果如下
这样再绘制图像
plt.matshow(error_matrix)就可以更直观的看出哪里错误率高,方便后面的处理
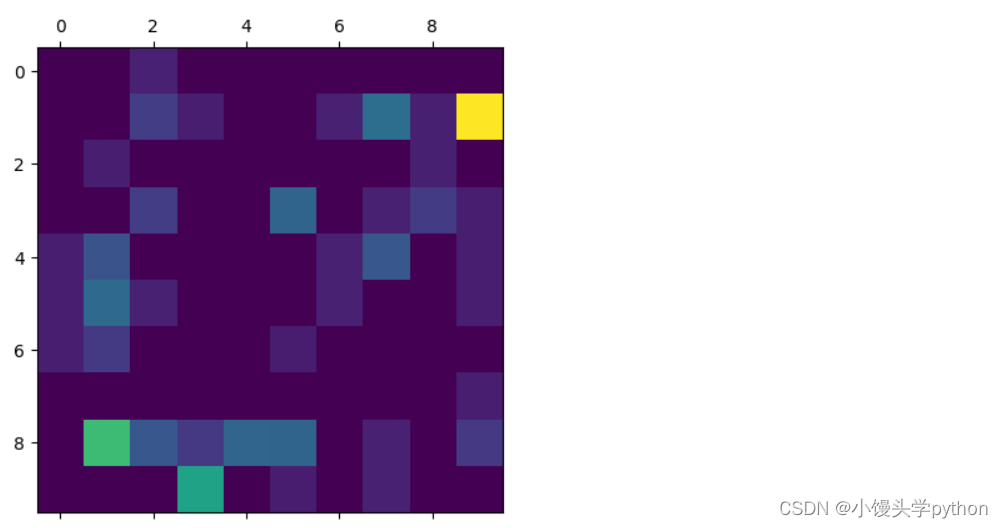
总结一下,混淆矩阵是评估多分类模型性能的强大工具,它提供了详细的信息,帮助我们了解模型在每个类别上的表现。结合精确度、精确率、召回率和F1分数等指标,可以更全面地评估模型的性能,进而改进模型或进行进一步的分析。深入理解和应用混淆矩阵有助于提高机器学习项目的质量和效果。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。

